Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans ce tutoriel, vous allez vous appuyer sur le travail d’un analyste Power BI stocké en tant que modèles sémantiques (jeux de données Power BI). En utilisant SemPy (préversion) dans l’expérience Synapse Data Science dans Microsoft Fabric, vous analysez les dépendances fonctionnelles dans les colonnes DataFrame. Cette analyse vous aide à découvrir des problèmes subtils de qualité des données pour obtenir des insights plus précis.
Dans ce tutoriel, vous allez apprendre à :
- Appliquez des connaissances de domaine pour formuler des hypothèses sur les dépendances fonctionnelles dans un modèle sémantique.
- Familiarisez-vous avec les composants de la bibliothèque Python de Semantic Link (SemPy) qui s’intègrent à Power BI et aident à automatiser l’analyse de la qualité des données. Ces composants sont les suivants :
- FabricDataFrame : structure de type pandas améliorée avec des informations sémantiques supplémentaires
- Fonctions qui extrayent des modèles sémantiques d’un espace de travail Fabric dans votre bloc-notes
- Fonctions qui évaluent les hypothèses de dépendance fonctionnelle et identifient les violations de relation dans vos modèles sémantiques
Conditions préalables
Obtenir un abonnement Microsoft Fabric. Vous pouvez également vous inscrire à une version d’évaluation gratuite de Microsoft Fabric .
Connectez-vous à Microsoft Fabric.
Basculez vers Fabric à l’aide du sélecteur d’expérience situé en bas à gauche de votre page d’accueil.

Sélectionnez Espaces de travail dans le volet de navigation pour rechercher et sélectionner votre espace de travail. Cet espace de travail devient votre espace de travail actuel.
Téléchargez le fichier Sample.pbix customer Profitability sample.pbix à partir du dépôt GitHub fabric-samples.
Dans votre espace de travail, sélectionnez Importer>Rapport ou rapport paginé>À partir de cet ordinateur pour charger le fichier Customer Profitability Sample.pbix dans votre espace de travail.
Suivre le notebook
Le notebook powerbi_dependencies_tutorial.ipynb vient avec ce tutoriel.
Pour ouvrir le bloc-notes associé pour ce didacticiel, suivez les instructions de Préparer votre système pour les didacticiels de science des données pour importer le bloc-notes dans votre espace de travail.
Si vous préférez copier et coller le code à partir de cette page, vous pouvez créer un bloc-notes.
Assurez-vous d'attacher un lakehouse au notebook avant de commencer à exécuter du code.
Configurer le notebook
Configurez un environnement de notebook avec les modules et les données dont vous avez besoin.
Permet
%pipd’installer SemPy à partir de PyPI dans le notebook.%pip install semantic-linkImportez les modules dont vous avez besoin.
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
Charger et prétraiter les données
Ce tutoriel utilise un exemple de modèle sémantique standard Customer Profitability Sample.pbix. Pour une description du modèle sémantique, voir l'exemple Rentabilité client pour Power BI.
Chargez des données Power BI dans un
FabricDataFrameà l’aide de lafabric.read_tablefonction.dataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()Chargez la
Statetable dans unFabricDataFrame.state = fabric.read_table(dataset, "State") state.head()Bien que la sortie ressemble à un DataFrame pandas, ce code initialise une structure de données appelée une
FabricDataFrameopération qui ajoute des opérations sur pandas.Vérifiez le type de données de
customer.type(customer)La sortie indique qu’il s’agit
customersempy.fabric._dataframe._fabric_dataframe.FabricDataFramede .Joignez les objets et
customerstatelesDataFrameobjets.customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
Identifier les dépendances fonctionnelles
Une dépendance fonctionnelle est une relation un-à-plusieurs entre les valeurs dans deux ou plusieurs colonnes d’un DataFrame. Utilisez ces relations pour détecter automatiquement les problèmes de qualité des données.
Exécutez la fonction SemPy
find_dependenciessur la fusionDataFramepour identifier les dépendances fonctionnelles entre les valeurs de colonne.dependencies = customer_state_df.find_dependencies() dependenciesVisualisez les dépendances à l’aide de la fonction semPy
plot_dependency_metadata.plot_dependency_metadata(dependencies)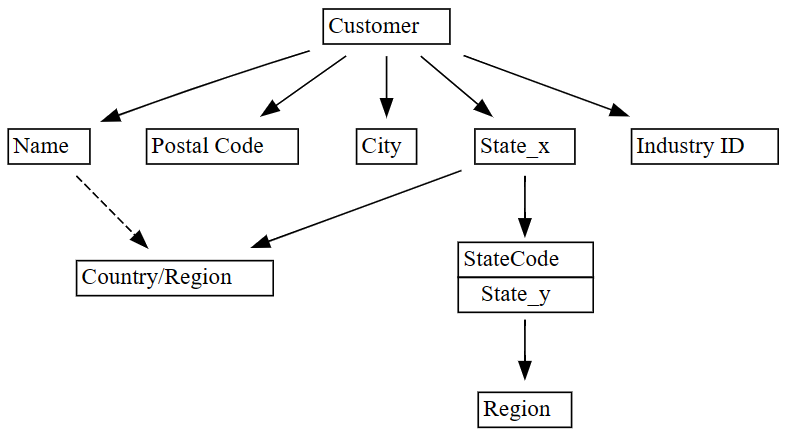
Le graphique des dépendances fonctionnelles montre que la
Customercolonne détermine des colonnes telles queCity,Postal CodeetName.Le graphique n’affiche pas de dépendance fonctionnelle entre
CityetPostal Code, probablement, car il existe de nombreuses violations dans la relation entre les colonnes. Utilisez la fonction semPy pour visualiser les violations deplot_dependency_violationsdépendances entre des colonnes spécifiques.

Explorer les données à la recherche de problèmes de qualité
Dessinez un graphique avec la fonction de visualisation
plot_dependency_violationsde SemPy.customer_state_df.plot_dependency_violations('Postal Code', 'City')
Le tracé des violations de dépendance affiche les valeurs pour
Postal Codele côté gauche et les valeurs pourCityle côté droit. Un bord connecte unPostal Codesur le côté gauche avec unCitysur le côté droit s’il existe une ligne qui contient ces deux valeurs. Les arêtes sont annotées avec le nombre de lignes de ce type. Par exemple, il existe deux lignes avec le code postal 20004, l’une avec la ville « Tour Nord » et l’autre avec la ville « Washington ».Le tracé affiche également quelques violations et de nombreuses valeurs vides.
Confirmez le nombre de valeurs vides pour
Postal Code:customer_state_df['Postal Code'].isna().sum()50 lignes ont na pour
Postal Code.Supprimez des lignes avec des valeurs vides. Ensuite, recherchez des dépendances à l’aide de la fonction
find_dependencies. Notez le paramètre supplémentaireverbose=1qui offre un aperçu des fonctionnements internes de SemPy :customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)L’entropie conditionnelle pour
Postal CodeetCityest 0,049. Cette valeur indique qu’il existe des violations de dépendance fonctionnelles. Avant de corriger les violations, augmentez le seuil d’entropie conditionnelle de la valeur par défaut de0.01à0.05, juste pour voir les dépendances. Les seuils inférieurs entraînent moins de dépendances (ou une sélectivité plus élevée).Augmentez le seuil de l’entropie conditionnelle de la valeur par défaut de
0.01à0.05:plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))
Si vous appliquez des connaissances de domaine dont l’entité détermine les valeurs d’autres entités, ce graphique de dépendances semble précis.
Explorez d’autres problèmes de qualité des données détectés. Par exemple, une flèche en pointillés joint
CityetRegion, ce qui indique que la dépendance n’est que approximative. Cette relation approximative peut impliquer qu’il existe une dépendance fonctionnelle partielle.customer_state_df.list_dependency_violations('City', 'Region')Examinez de plus près chaque cas où une valeur
Regionnon vide provoque une violation :customer_state_df[customer_state_df.City=='Downers Grove']Le résultat montre la ville de Downers Grove dans l’Illinois et le Nebraska. Cependant, Downers Grove est une ville de l’Illinois, pas de Nebraska.
Regardez la ville de Fremont:
customer_state_df[customer_state_df.City=='Fremont']Il y a une ville appelée Fremont en Californie. Toutefois, pour le Texas, le moteur de recherche retourne Premont, pas Fremont.
Il est également suspicieux de voir les violations de la dépendance entre
NameetCountry/Region, comme le montre la ligne en pointillé dans le graphique initial des violations de dépendances (avant de supprimer les lignes avec des valeurs vides).customer_state_df.list_dependency_violations('Name', 'Country/Region')Un client, SDI Design, apparaît dans deux régions ( États-Unis et Canada). Ce cas peut ne pas être une violation sémantique, tout simplement rare. Toujours, il vaut la peine d’avoir un regard étroit :
Examinez de plus près le client SDI Design:
customer_state_df[customer_state_df.Name=='SDI Design']L’inspection supplémentaire montre deux clients différents de différents secteurs d’activité portant le même nom.

L’analyse exploratoire des données et le nettoyage des données sont itératifs. Ce que vous trouvez dépend de vos questions et de votre perspective. Le lien sémantique vous donne de nouveaux outils pour obtenir plus d’informations à partir de vos données.
Contenu connexe
Consultez d’autres tutoriels pour le lien sémantique et SemPy :
- Didacticiel : Nettoyer les données avec des dépendances fonctionnelles
- Tutoriel : Extraire et calculer des mesures Power BI à partir d’un notebook Jupyter
- Tutoriel : Découvrir les relations dans un modèle sémantique, à l’aide d’un lien sémantique
- Tutoriel : Découvrir des relations dans le jeu de données Synthea, à l’aide d’un lien sémantique
- tutoriel : Valider les données à l’aide de SemPy et de GX (Great Expectations)