Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :✅ point de terminaison d’analytique SQL et entrepôt dans Microsoft Fabric
La récupération de données à partir du lac de données est une opération d’entrée/sortie (E/S) cruciale avec des implications importantes pour les performances des requêtes. L’entrepôt de données Fabric utilise des modèles d’accès affinés pour améliorer la lecture des données à partir du stockage et augmenter la vitesse d’exécution des requêtes. En outre, il réduit intelligemment le besoin de lectures de stockage à distance en tirant parti des caches locaux.
La mise en cache est une technique qui améliore les performances des applications de traitement de données en réduisant les opérations d’E/S. La mise en cache stocke les données et les métadonnées fréquemment consultées dans une couche de stockage plus rapide, telle que la mémoire locale ou les disques SSD locaux, afin que les requêtes suivantes puissent être traitées plus rapidement, directement à partir du cache. Si un ensemble particulier de données a été précédemment accédé par une requête, toutes les requêtes suivantes récupèrent ces données directement à partir du cache en mémoire. Cette approche diminue considérablement la latence d’E/S, car les opérations de mémoire locale sont considérablement plus rapides par rapport à l’extraction des données à partir d’un stockage distant.
La mise en cache en mémoire et sur disque dans Fabric Data Warehouse est entièrement transparente pour l’utilisateur. Quelle que soit l’origine, qu’il s’agisse d’une table d’entrepôt, d’un raccourci OneLake ou même d’un raccourci OneLake qui fait référence à des services non Azure, la requête met en cache toutes les données auxquelles elle accède.
Il existe deux types de caches décrits plus loin dans cet article, le cache en mémoire et le cache de disque. La mise en cache du jeu de résultats est abordée dans un autre article.
Cache en mémoire
Lorsque la requête accède aux données du stockage et les récupère, elle effectue un processus de transformation qui transcode les données de son format d’origine basé sur un fichier en structures hautement optimisées dans le cache en mémoire.

Les données dans le cache sont organisées dans un format de colonne compressé optimisé pour les requêtes analytiques. Chaque colonne de données est stockée ensemble, séparée des autres, ce qui permet une meilleure compression, car des valeurs de données semblables sont stockées ensemble, ce qui réduit l’empreinte mémoire. Lorsque les requêtes doivent effectuer des opérations sur une colonne spécifique, comme les agrégats ou le filtrage, le moteur peut fonctionner plus efficacement, car il n’a pas besoin de traiter les données inutiles d’autres colonnes.
En outre, ce stockage en colonnes est également propice au traitement parallèle, qui peut considérablement accélérer l’exécution des requêtes pour les jeux de données volumineux. Le moteur peut effectuer des opérations sur plusieurs colonnes simultanément, en tirant parti des processeurs multicœurs modernes.
Cette approche est particulièrement utile pour les charges de travail analytiques où les requêtes impliquent l’analyse de grandes quantités de données pour effectuer des agrégations, des filtrages et d’autres manipulations des données.
Cache de disque
Certains jeux de données sont trop volumineux pour être hébergés dans un cache en mémoire. Pour soutenir des performances de requête rapides pour ces jeux de données, l’entrepôt utilise l’espace disque comme extension complémentaire du cache en mémoire. Toutes les informations chargées dans le cache en mémoire sont également sérialisées dans le cache SSD.
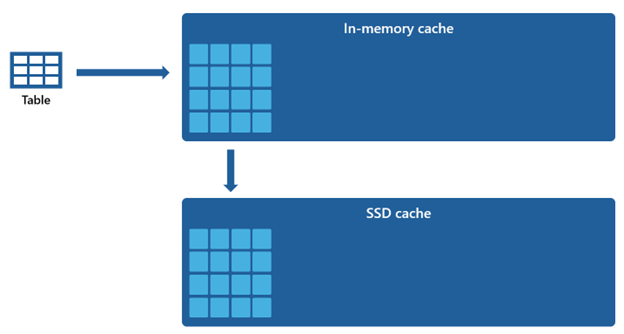
Étant donné que le cache en mémoire a une capacité inférieure par rapport au cache SSD, les données supprimées du cache en mémoire restent dans le cache SSD pendant une période prolongée. Lorsque les requêtes suivantes demandent ces données, elles sont récupérées du cache SSD dans le cache en mémoire beaucoup plus rapidement que si elles sont extraites du stockage distant, ce qui vous offre des performances de requête plus cohérentes.

Gestion du cache
La mise en cache reste toujours active et fonctionne en toute transparence en arrière-plan, ce qui ne nécessite aucune intervention de votre part. La désactivation de la mise en cache n’est pas nécessaire, car cela entraînerait inévitablement une détérioration notable des performances des requêtes.
Le mécanisme de mise en cache est orchestré et maintenu par Microsoft Fabric lui-même, et il n’offre pas aux utilisateurs la possibilité d’effacer manuellement le cache.
La cohérence transactionnelle du cache complet garantit que toutes les modifications apportées aux données dans le stockage, telles que les opérations DML (Data Manipulation Language), une fois qu’elles ont été initialement chargées dans le cache en mémoire, aboutissent à des données cohérentes.
Lorsque le cache atteint son seuil de capacité et que de nouvelles données sont lues pour la première fois, les objets qui sont restés inutilisés pendant la durée la plus longue sont supprimés du cache. Ce processus est adopté pour créer de l’espace pour l’afflux de nouvelles données et maintenir une stratégie d’utilisation optimale du cache.