Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Applies to :✅ Entrepôt dans Microsoft Fabric
Cet article explique comment fonctionnent les pipelines d’intégration et de déploiement Git pour les entrepôts dans Microsoft Fabric. Découvrez comment configurer une connexion à votre dépôt, gérer vos entrepôts et les déployer dans différents environnements. Le contrôle de code source pour Fabric Warehouse est actuellement une fonctionnalité en préversion.
Vous pouvez utiliser l’intégration Git et les pipelines de déploiement pour différents scénarios :
- Utilisez des projets de base de données Git et SQL pour gérer les modifications incrémentielles, la collaboration d’équipe et l’historique des validations dans des objets de base de données individuels.
- Utiliser des pipelines de déploiement pour promouvoir les modifications de code dans différents environnements de préproduction et de production.
Intégration Git
L’intégration git dans Microsoft Fabric permet aux développeurs d’intégrer leurs processus de développement, outils et meilleures pratiques directement dans la plateforme Fabric. Il permet aux développeurs qui se développent dans Fabric de :
- Sauvegarder et versionner leur travail
- Revenir aux étapes précédentes si nécessaire
- Collaborer avec d’autres personnes ou travailler seul à l’aide de branches Git
- Appliquer les fonctionnalités des outils de contrôle de code source familiers pour gérer les éléments Fabric
Pour plus d’informations sur le processus d’intégration Git, consultez :
- Qu'est-ce que l'intégration Git de Microsoft Fabric ?
- Concepts de base de l’intégration Git
- Démarrer avec l’intégration Git
Configurer une connexion au contrôle de code source
À partir de la page Paramètres de l’espace de travail, vous pouvez facilement configurer une connexion à votre dépôt pour commiter et synchroniser les modifications.
- Pour configurer la connexion, consultez Démarrer avec l’intégration de Git. Suivez les instructions pour Connecter à un dépôt Git pour Azure DevOps ou GitHub en tant que fournisseur Git.
- Une fois connectés, vos éléments, y compris les entrepôts, apparaissent dans le panneau Contrôle de code source.
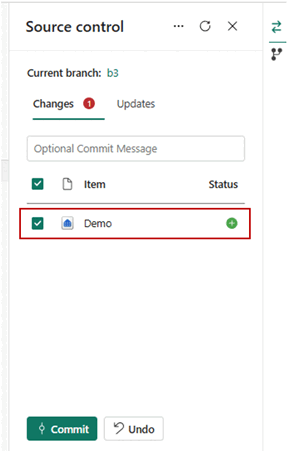
- Une fois que vous avez correctement connecté les instances de l’entrepôt au dépôt Git, vous voyez la structure des dossiers de l’entrepôt dans le dépôt. Vous pouvez maintenant exécuter des opérations futures, comme la création d’une pull request.
Projets de base de données pour un entrepôt dans Git
L’image suivante est un exemple de structure de fichiers de chaque élément d’entrepôt dans le dépôt :

Lorsque vous commitez l’élément d’entrepôt dans le dépôt Git, l’entrepôt est converti au format de code source, en tant que projet de base de données SQL. Un projet SQL est une représentation locale d’objets SQL qui comprennent le schéma d’une base de données unique, comme des tables, des procédures stockées ou des fonctions. La structure de dossiers des objets de base de données est organisée par schéma/type d’objet. Chaque objet de l’entrepôt est représenté par un fichier .sql qui contient sa définition DDL (Data Definition Language). Les données de table d’entrepôt et les fonctionnalités de sécurité SQL ne sont pas incluses dans le projet de base de données SQL.
Les requêtes partagées sont également commitées dans le dépôt, et héritent du nom sous lequel elles sont enregistrées.
Pour les espaces de travail avec contrôle de code source activé, toutes les modifications de schéma apportées via des outils externes (par exemple, l’exécution de requêtes dans SSMS) s’affichent comme des modifications non validées dans l’entrepôt. Les utilisateurs doivent passer en revue et valider ces modifications via le contrôle de code source de l’espace de travail dans le portail Fabric.
Pipelines de déploiement
Vous pouvez également utiliser des pipelines de déploiement pour déployer votre code d’entrepôt dans différents environnements : développement, test, et production. Les pipelines de déploiement n’exposent pas de projet de base de données.
Procédez comme suit pour effectuer votre déploiement d’entrepôt à l’aide du pipeline de déploiement.
- Créez un pipeline de déploiement ou ouvrez un pipeline de déploiement existant. Pour plus d’informations, consultez Commencer avec les pipelines de déploiement.
- Affectez des espaces de travail à différentes phases en fonction de vos objectifs de déploiement.
- Sélectionnez, affichez et comparez les éléments, y compris les entrepôts, entre différentes étapes, comme illustré dans l’exemple suivant.
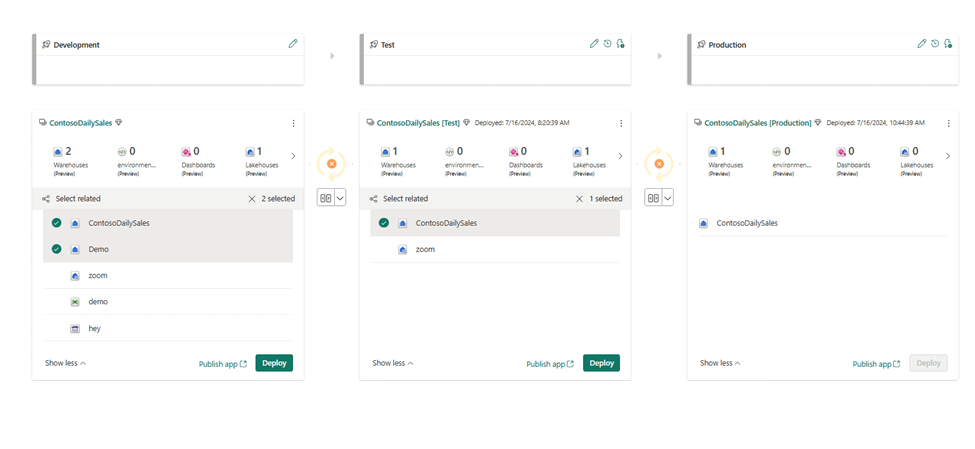
- Sélectionnez Déployer pour déployer vos entrepôts dans les phases Développement, Test, et Production.

Pour plus d’informations sur le processus des pipelines de déploiement Fabric, consultez Introduction aux pipelines de déploiement.
Limitations dans le contrôle de code source
- Vous devez exporter ou migrer des fonctionnalités de sécurité SQL à l’aide d’une approche basée sur des scripts. Envisagez d’utiliser un script post-déploiement dans un projet de base de données SQL. Vous pouvez configurer ce script en ouvrant le projet avec l’extension SQL Database Projects disponible dans Visual Studio Code.
Limitations de l’intégration Git
- Actuellement, si vous utilisez
ALTER TABLEpour ajouter une contrainte ou une colonne dans le projet de base de données, le processus de déploiement supprime et recrée la table, ce qui entraîne une perte de données. Pour conserver la définition de table et les données, tenez compte de la solution de contournement suivante :- Créez une nouvelle copie de la table dans l’entrepôt à l’aide de
CREATE TABLEet deINSERT,CREATE TABLE AS SELECT, ou cloner la table. - Modifiez la nouvelle définition de table avec de nouvelles contraintes ou colonnes, comme vous le souhaitez, en utilisant
ALTER TABLE. - Supprimez l’ancienne table.
- Renommez la nouvelle table en nom de l’ancienne table à l’aide de sp_rename.
- Modifiez la définition de l’ancienne table dans le projet de base de données SQL exactement de la même façon. Le projet de base de données SQL de l’entrepôt dans la gestion du contrôle de source et l’entrepôt en ligne doivent être synchronisés.
- Créez une nouvelle copie de la table dans l’entrepôt à l’aide de
- Actuellement, ne créez pas de dataflow Gen2 avec une destination de sortie vers l’entrepôt. Un nouvel élément nommé
DataflowsStagingWarehouseapparaît dans le référentiel et bloque la validation et la mise à jour à partir de Git. - L'intégration Git de Fabric ne prend pas en charge l'élément du point de terminaison SQL Analytics.
- Les dépendances entre les éléments, le séquencement d’éléments et les lacunes de synchronisation entre le point de terminaison d’analytique SQL et l’entrepôt ont un impact sur la « branchement vers un espace de travail nouveau ou existant » et le « basculement vers une autre branche » pendant le développement et l’intégration continue.
Limitations des pipelines de déploiement
- Actuellement, si vous utilisez
ALTER TABLEpour ajouter une contrainte ou une colonne dans le projet de base de données, le processus de déploiement supprime et recrée la table, ce qui entraîne une perte de données. - Actuellement, ne créez pas de dataflow Gen2 avec une destination de sortie vers l’entrepôt. Un nouvel élément nommé
DataflowsStagingWarehouseapparaît dans le pipeline de déploiement et bloque le déploiement. - Les pipelines de déploiement Fabric ne prennent pas en charge l'élément de point de terminaison pour les analyses SQL.
- Dépendances entre composants, séquencement de composants et écarts de synchronisation entre le point de terminaison d’analytique SQL et l’entrepôt qui impactent les flux de travail des Pipelines de déploiement Fabric.
Scénarios non pris en charge
Les flux de travail CI/CD suivants ne sont pas officiellement pris en charge lorsque les entrepôts dans différents espaces de travail ont des classements différents. Même si ces opérations peuvent réussir sans erreur, elles peuvent entraîner des erreurs de métadonnées.
Dans tous ces scénarios, si une incompatibilité de classement se produit, utilisez le script Python scripts/dw-collation-error-update-tmsl/pbi_interactive.py dans la boîte à outils Fabric sur le référentiel GitHub pour mettre à jour le classement du jeu de données (TMSL) afin qu'il corresponde à celui de l'entrepôt.
| Scénario | Description | Risque |
|---|---|---|
| Pipelines de déploiement | La promotion du contenu de l’entrepôt via des étapes de pipeline (par exemple, Dev → Test → Prod) où l’entrepôt cible a été créé avec un classement différent de la source n’est pas pris en charge. | Le déploiement peut réussir, mais le classement du jeu de données n’est pas mis à jour pour correspondre au classement de l’entrepôt cible. |
| Extension dans un espace de travail nouveau ou existant | L'utilisation de l'intégration de Git pour créer une branche à partir d’un espace de travail existant vers un nouvel espace de travail ou un espace de travail existant où l’entrepôt a une collation différente n’est pas prise en charge. | Le contenu de l’entrepôt est synchronisé, mais les métadonnées de classement ne sont pas rapprochées. |
| Changement de branches sur un espace de travail | Le passage à une branche associée à un entrepôt d’un autre classement sur un espace de travail connecté à Git n’est pas pris en charge. | Le contenu synchronisé pourrait comporter ses propres hypothèses de classement qui ne correspondent pas à l’entrepôt actuel. |
| Fusion des modifications entre les espaces de travail via des branches | La fusion de branches Git entre les espaces de travail où les entrepôts ont des classements différents n’est pas prise en charge. | La fusion peut réussir au niveau Git, mais le classement du jeu de données résultant ne reflète pas le classement de l’entrepôt cible. |