Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
La mise en miroir de bases de données dans Microsoft Fabric est une technologie SaaS d'entreprise, basée sur le cloud, et sans ETL. Ce guide vous aide à établir une base de données mise en miroir à partir d’Azure Databricks, qui crée une copie en lecture seule et en continu de vos données Azure Databricks dans OneLake.
Prerequisites
- Un espace de travail Fabric.
- Activez l’accès aux données externes sur le metastore. Pour plus d’informations, consultez Activer l’accès aux données externes sur le metastore.
- Créez ou utilisez un espace de travail Azure Databricks existant avec Unity Catalog activé.
- Disposez du privilège
EXTERNAL USE SCHEMAsur le schéma du catalogue Unity qui contient les tables auxquelles Fabric accès. - Utilisez le modèle d’autorisations de Fabric pour définir des contrôles d’accès pour les catalogues, les schémas et les tables dans Fabric.
Créer une base de données mise en miroir à partir d’Azure Databricks
Suivez ces étapes pour créer une base de données mise en miroir à partir de votre catalogue Azure Databricks Unity.
Accédez à votre espace de travail dans Fabric.
Sélectionnez Nouvel élément>catalogue mis en miroir Azure Databricks.

Sélectionnez une connexion existante si vous en avez une configurée ou créez une connexion.
Pour créer une connexion, vous devez être un utilisateur ou un administrateur de l’espace de travail Azure Databricks. Vous pouvez vous authentifier à votre espace de travail Azure Databricks à l’aide de l’authentification compte d’organisation ou de l’authentification principal de service.
Note
Le choix d’authentification que vous effectuez ici s’applique à l’authentification Databricks et à l’autorisation du catalogue Unity. Si vous devez accéder aux comptes Azure Data Lake Storage (ADLS) Gen2 derrière un pare-feu, suivez les étapes pour Enable accès à la sécurité réseau pour votre compte Azure Data Lake Storage Gen2 plus loin dans cet article. Lorsque ADLS Gen2 se trouve derrière un pare-feu, l’identité de l’espace de travail Fabric est requise pour accéder au pare-feu de stockage, quelle que soit la méthode d’authentification choisie pour la connexion Databricks.
Après vous être connecté à un espace de travail Azure Databricks, dans la page Choose des tables à partir d’un catalogue Databricks, sélectionnez le catalogue, les schémas et les tables que vous souhaitez ajouter et accéder à partir de Fabric à l’aide de la liste d’inclusion ou d’exclusion. Sélectionnez le catalogue et ses schémas et tables associés que vous souhaitez ajouter à votre espace de travail Fabric.
Vous ne pouvez voir que les catalogues, schémas et tables auxquels vous avez accès. Pour plus d'informations, consultez Privilèges Unity Catalog et objets sécurisables.
Par défaut, la synchronisation automatique des modifications futures du catalogue pour l’option de schéma sélectionnée est activée. Pour plus d’informations, consultez Mirroring Azure Databricks > Synchronisation des métadonnées.
Sélectionnez Suivant pour continuer.
Dans la page Vérifier et créer , passez en revue les détails et modifiez éventuellement le nom de l’élément de base de données mis en miroir, qui doit être unique dans votre espace de travail. Par défaut, le nom de l’élément mis en miroir est le nom du catalogue.
Sélectionnez Créer pour continuer.
Un élément de catalogue Databricks est créé et, pour chaque table, un raccourci de type Databricks correspondant est également créé.
Les schémas qui n’ont pas de tables ne sont pas affichés.
Vous pouvez également afficher un aperçu des données lorsque vous accédez à un raccourci en sélectionnant le point de terminaison d’analytique SQL. Ouvrez l’élément de l'endpoint SQL Analytics pour lancer la page de l’Explorateur et de l’éditeur de requête. Vous pouvez interroger vos tables Azure Databricks mises en miroir à l’aide de T-SQL dans l’éditeur SQL.
Créer des raccourcis Lakehouse vers l’élément de catalogue Databricks
Vous pouvez également créer des raccourcis à partir de votre Lakehouse vers votre élément de catalogue Databricks pour utiliser vos données Lakehouse et pour pouvoir utiliser des notebooks Spark.
- Tout d'abord, créez un lakehouse. Si vous disposez déjà d’un lakehouse dans cet espace de travail, vous pouvez utiliser un lakehouse existant.
- Sélectionnez votre espace de travail dans le menu de navigation.
- Sélectionnez + New>Lakehouse.
- Indiquez un nom pour votre lakehouse dans le champ Nom , puis sélectionnez Créer.
- Dans l’affichage Explorateur de votre lakehouse, dans le menu Obtenir les données de votre lakehouse , sous Charger des données dans votre lakehouse, sélectionnez le bouton Nouveau raccourci .
- Sélectionnez Microsoft OneLake. Sélectionnez un catalogue. Il s’agit de l’élément de données que vous avez créé lors des étapes précédentes. Ensuite, sélectionnez Suivant.
- Sélectionnez des tables dans le schéma, puis sélectionnez Suivant.
- Cliquez sur Créer.
- Les raccourcis sont désormais disponibles dans votre Lakehouse pour les utiliser avec vos autres données Lakehouse. Vous pouvez également utiliser Notebooks et Spark pour effectuer le traitement des données sur les données de ces tables de catalogue que vous avez ajoutées à partir de votre espace de travail Azure Databricks.
Créer un modèle sémantique
Vous pouvez créer un modèle sémantique Power BI en fonction de votre élément mis en miroir et ajouter ou supprimer manuellement des tables. Pour plus d’informations sur la création et la gestion de modèles sémantiques, consultez Créer un modèle sémantique Power BI.
Pour une expérience optimale, utilisez le navigateur Microsoft Edge pour les tâches de modélisation sémantique.
Gérer vos relations de modèle sémantique
Après avoir créé un modèle sémantique basé sur votre base de données mise en miroir, configurez les relations entre les tables.
- Sélectionnez Les dispositions de modèle dans l’Explorateur dans votre espace de travail.
- Une fois que vous avez sélectionné Dispositions du modèle, une représentation graphique des tables faisant partie du modèle sémantique s’affiche.
- Pour créer des relations entre les tables, faites glisser un nom de colonne d’une table vers un autre nom de colonne d’une autre table. Une fenêtre contextuelle apparaît pour identifier la relation et la cardinalité des tables.
Activer l’accès à la sécurité réseau pour votre compte Azure Data Lake Storage Gen2
Configurez la sécurité réseau pour votre compte Azure Data Lake Storage (ADLS) Gen2 lorsque vous disposez d’un pare-feu stockage Azure configuré. Cette section s’applique aux comptes de stockage ADLS Gen2 derrière un pare-feu stockage Azure. Le stockage de l’espace de travail Azure Databricks protégé par un pare-feu stockage Azure n’est pas pris en charge.
Prerequisites
Lorsqu’un pare-feu stockage Azure protège ADLS Gen2, Fabric utilise l’identité de l’espace de travail pour accéder au pare-feu. Même si vous sélectionnez principal du service pour l’authentification ADLS dans l’onglet Network Security, vous devez autoriser l’identité de l’espace de travail dans le pare-feu du compte stockage Azure.
L’identité de l’espace de travail est utilisée pour l’accès au pare-feu de stockage. Un principal de service ou OAuth est utilisé pour l’authentification Databricks et l’autorisation du catalogue Unity.
Pour activer le type d’authentification d’identité de l’espace de travail (recommandé), associez l’espace de travail Fabric à une capacité F. Pour créer une identité d’espace de travail, consultez Authentifier avec l’identité de l’espace de travail.
Vous ne pouvez associer un catalogue qu’à un seul compte de stockage.
Activer l’accès à la sécurité réseau
Lors de la création d’un catalogue Azure Databricks mis en miroir, dans l’étape Choisir des données , sélectionnez l’onglet Sécurité réseau .
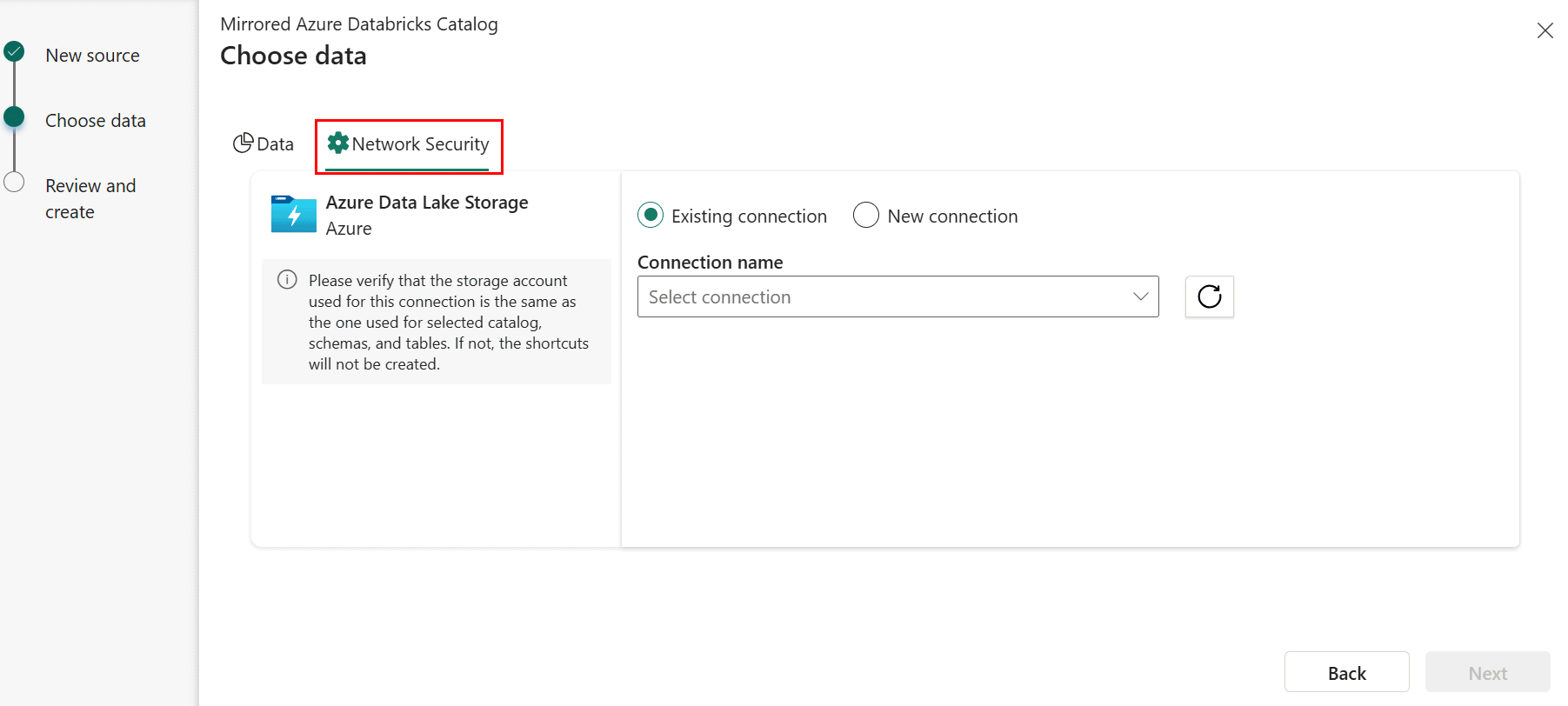
Sélectionnez une connexion existante au compte de stockage si vous en avez configuré un.
- Si vous n’avez pas de connexion ADLS existante, créez une nouvelle connexion.
-
L’URL du point de terminaison de stockage est l’emplacement où les données du catalogue sélectionné sont stockées. Le point de terminaison doit être le dossier spécifique dans lequel les données sont stockées, plutôt que de spécifier le point de terminaison au niveau du compte de stockage. Par exemple, fournissez
https://<storage account>.dfs.core.windows.net/container1/folder1plutôt quehttps://<storage account>.dfs.core.windows.net/. - Fournissez les informations d’identification de connexion. Les types d’authentification pris en charge sont le compte organisationnel, le principal de service et l’identité de l’espace de travail (recommandé).
Note
Quand ADLS Gen2 est protégé par un pare-feu stockage Azure, Fabric utilise l’identité de l’espace de travail pour parcourir le pare-feu, quel que soit le type d’authentification sélectionné ici. Le type d’authentification (principal de service ou compte organisationnel) contrôle l’authentification à Databricks et l’autorisation dans Unity Catalog, tandis que l’identité de l’espace de travail contrôle l’accès de confiance via le pare-feu de stockage. L’identité de l’espace de travail doit être autorisée dans le pare-feu de compte stockage Azure même si vous sélectionnez un autre type d’authentification pour la connexion ADLS.
Dans le portail Azure, fournissez des droits d’accès au compte de stockage en fonction du type d’authentification que vous avez choisi à l’étape précédente. Accédez au compte de stockage dans le portail Azure. Sélectionnez Contrôle d’accès (IAM). Sélectionnez +Ajouter et ajouter une attribution de rôle. Pour plus d’informations, consultez Affecter des rôles Azure à l’aide du portail Azure.
Attribuez un rôle en fonction de l’étendue de la connexion :
- Compte de stockage : l’identité d’authentification choisie a besoin du rôle Lecteur de données Blob de stockage sur le compte de stockage.
- Conteneur : l’identité d’authentification choisie a besoin du rôle Lecteur de données Blob du stockage sur le conteneur.
- Dossier au sein d’un conteneur (recommandé) : l’identité d’authentification choisie nécessite des autorisations Lecture (R) et Exécuter (E) au niveau du dossier. Si vous utilisez le principal de service ou l’identité de l’espace de travail comme type d’authentification, accordez également à cette identité les autorisations d’exécution sur le dossier racine du conteneur, ainsi que sur chaque dossier de la hiérarchie menant au dossier spécifié.
Pour plus d’informations et des étapes d’octroi d’accès ADLS, consultez le contrôle d’accès ADLS.
Activez Accès à l’espace de travail approuvé en configurant une règle d’instance de ressource pour votre espace de travail Fabric sur le compte de stockage. Pour obtenir des instructions détaillées, consultez Accès approuvé à l’espace de travail et Bases de données Fabric mises en miroir sécurisées depuis Azure Databricks.
Une fois la connexion établie, un raccourci vers les tables du catalogue Unity est créé pour les tables dont le nom du compte de stockage correspond au compte de stockage spécifié dans la connexion ADLS. Les raccourcis ne sont pas créés pour les tables dont le nom du compte de stockage ne correspond pas.
Important
Si vous envisagez d’utiliser la connexion ADLS en dehors des scénarios d’élément de catalogue Azure Databricks mis en miroir, vous devez également affecter le rôle Storage Blob Delegator sur le compte de stockage.
Tip
Si vous recevez une erreur d’autorisation 403 lors de l’utilisation d’un principal de service pour l’authentification Databricks avec un compte ADLS Gen2 protégé par le pare-feu, vérifiez que l’identité de l’espace de travail est autorisée dans le pare-feu du compte stockage Azure. Même lorsqu’un principal de service est sélectionné pour l’authentification, Fabric utilise l’identité de l’espace de travail pour parcourir le pare-feu de stockage.
Activer la sécurité OneLake sur l’élément Databricks mis en miroir
Associez les stratégies du catalogue Unity (UC) à la sécurité Microsoft OneLake en procédant comme suit :
- Synchronisez le groupe Entra et appliquez des autorisations dans le catalogue Unity. Dans Azure Databricks, utilisez Automatic Identity Management pour synchroniser un groupe Microsoft Entra ID et lui accorder les privilèges de catalogue Unity nécessaires (USE, BROWSE et SELECT) sur le catalogue et les tables appropriés.
- Attribuez un rôle d’accès aux données OneLake. Dans l’espace de travail Fabric, créez un rôle d’accès aux données pour les données nouvellement mises en miroir. Ajoutez le même groupe Entra à ce rôle et accordez-lui un accès en lecture aux raccourcis OneLake correspondant aux tables Azure Databricks. Pour commencer à utiliser la sécurité au niveau de la table, sélectionnez le bouton Gérer la sécurité OneLake dans le ruban. Veillez à conserver les configurations d’accès synchronisées à mesure que les structures de catalogue et les autorisations évoluent. Pour plus d’informations, consultez le modèle de contrôle d’accès aux données OneLake (préversion).
Contenu connexe
- Bases de données Secure Fabric mises en miroir à partir d’Azure Databricks
- Blog : Sécuriser les données Azure Databricks mises en miroir dans Fabric avec la sécurité OneLake
- Limitations dans les bases de données mises en miroir Microsoft Fabric à partir d’Azure Databricks
- Questions fréquemment posées sur les bases de données en miroir à partir d’Azure Databricks dans Microsoft Fabric
- Mise en miroir du catalogue Unity Azure Databricks
- Contrôler l’accès externe aux données dans le catalogue Unity