Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Mirroring dans Fabric est une technologie SaaS d’entreprise, basée sur le cloud, zéro ETL. Dans cette section, vous allez apprendre à créer une base de données SAP mise en miroir, qui crée une copie en lecture seule et en continu de vos données SAP dans OneLake.
Ce tutoriel explique comment configurer SAP mis en miroir via SAP Datasphere. Pour obtenir une vue d’ensemble de la solution, reportez-vous à la mise en miroir pour SAP via SAP Datasphere.
Prerequisites
Tu as besoin de:
- Capacité existante pour Fabric. Si vous n’en avez pas, Lancez une version d’évaluation de Fabric.
- Environnement SAP Datasphere avec intégration sortante Premium.
Configurer SAP Datasphere
Cette section décrit les étapes de configuration dont vous avez besoin pour répliquer des données à partir de votre source SAP dans un conteneur Azure Data Lake Storage (ADLS) Gen2. Vous utiliserez ce conteneur ultérieurement pour configurer la base de données SAP mise en miroir dans Fabric.
Conseil / Astuce
Si vous avez déjà exécuté le flux de réplication pour répliquer des données dans ADLS Gen2, vous pouvez ignorer cette section et créer une base de données mise en miroir.
Configurer des connexions dans SAP Datasphere
Avant de pouvoir répliquer des données à partir de votre source SAP dans ADLS Gen2, vous devez créer des connexions à la fois à la source et à la cible dans SAP Datasphere.
Accédez à SAP Datasphere, puis sélectionnez l’outil Connexion . Vous devrez peut-être sélectionner l’espace dans lequel vous souhaitez créer la connexion.
Créez la connexion à votre système SAP source. Sélectionnez + ->Créer une connexion, choisissez la source SAP à partir de laquelle vous souhaitez répliquer les données et configurez les détails de connexion. Par exemple, vous pouvez créer une connexion à SAP S/4HANA localement.
Créez la connexion à votre cible ADLS Gen2. Sélectionnez Créer une connexion et choisissez Azure Data Lake Storage Gen2. Entrez le nom du compte de stockage, le nom du conteneur (sous le chemin d’accès racine), votre type d’authentification préféré et les informations d’identification. Vérifiez que l’utilisateur/le principal de connexion dispose de suffisamment de privilèges pour créer des fichiers et des dossiers dans ADLS Gen2. En savoir plus sur les connexions Microsoft Azure Data Lake Store Gen2.
Avant de continuer, validez vos connexions en sélectionnant votre connexion et en choisissant l’option Valider dans le menu supérieur.

Configurer un flux de réplication Datasphere
Créez un flux de réplication pour répliquer des données à partir de votre source SAP dans ADLS Gen2. Pour plus d’informations sur cette configuration, consultez l’aide SAP sur la création d’un flux de réplication.
Lancez le Générateur de données dans SAP Datasphere.
Sélectionnez Nouveau flux de réplication.
Lorsque le canevas de flux de réplication s’ouvre, sélectionnez Sélectionner la connexion source, puis sélectionnez la connexion que vous avez créée pour votre système source SAP.
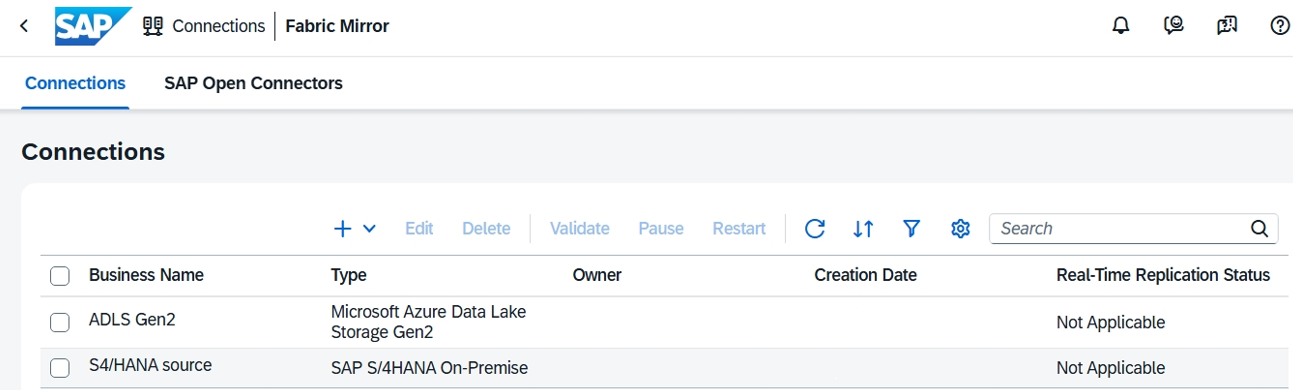
Sélectionnez le conteneur source approprié, qui est le type d’objets sources à partir duquel vous souhaitez répliquer. L’exemple suivant utilise CDS_EXTRACTION pour répliquer des données à partir de vues CDS dans un système source SAP S/4HANA local. Sélectionnez ensuite Sélectionner.
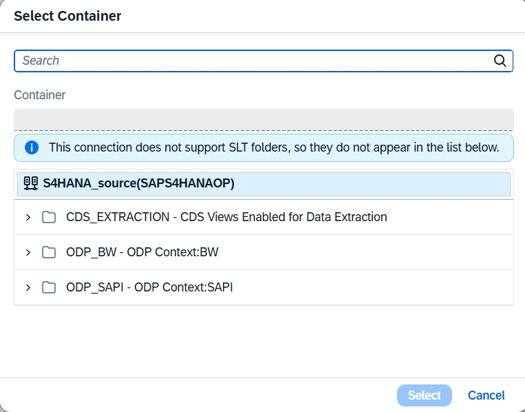
Sélectionnez Ajouter des objets sources pour choisir les objets sources que vous souhaitez répliquer. Après avoir sélectionné toutes vos sources, sélectionnez Suivant.
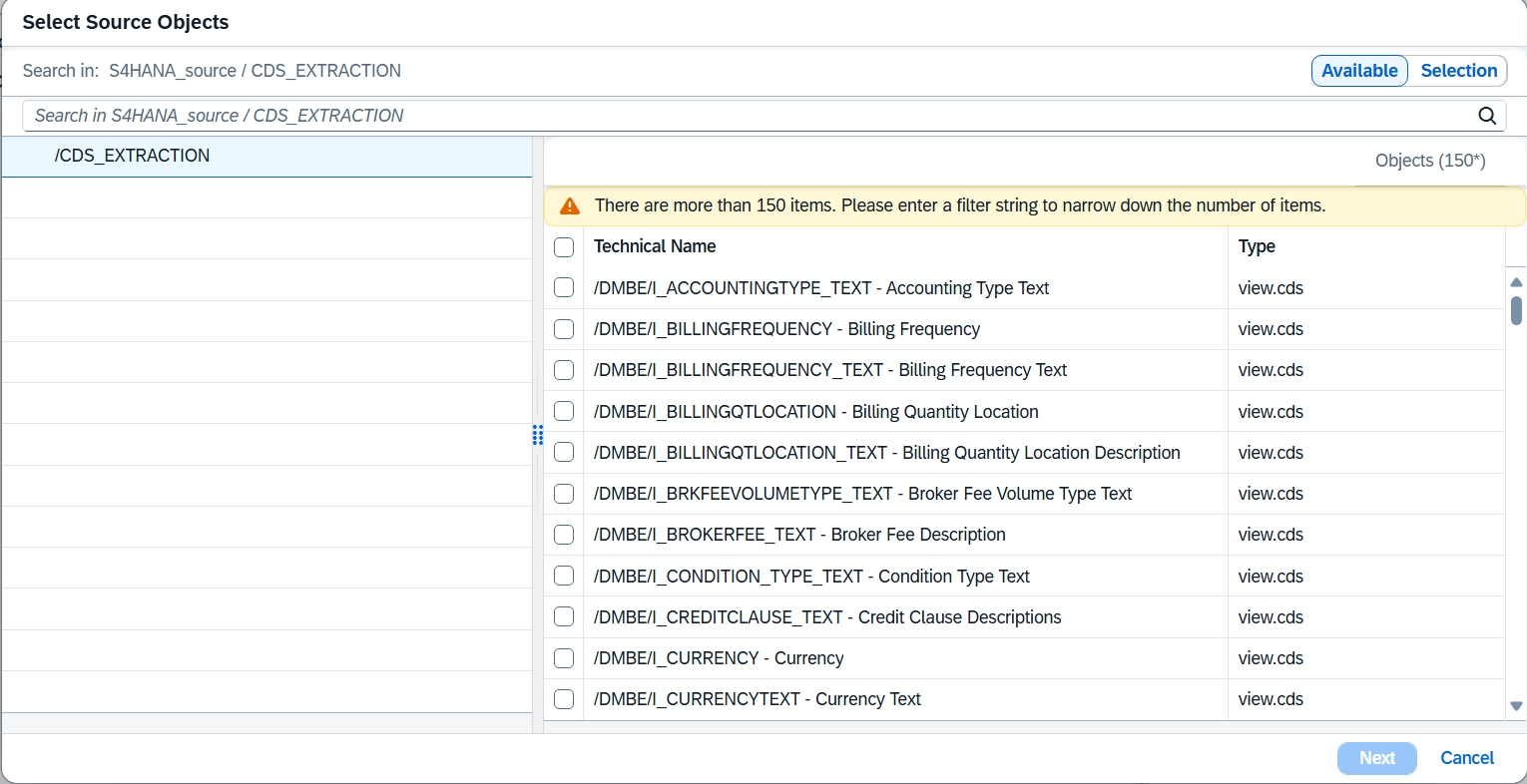
Configurez le ADLS Gen2 désigné. Sélectionnez la connexion cible et le conteneur. Vérifiez que les paramètres cibles sont corrects : Group Delta by est défini sur None et le type de fichier est défini sur Parquet.
Configurez les paramètres de détail de la réplication. Sélectionnez Paramètres dans la section centrale du canevas. Vérifiez et ajustez le type de chargement sélectionné si nécessaire. Actuellement, la mise en miroir prend en charge Initiale et Delta ou Initiale uniquement.
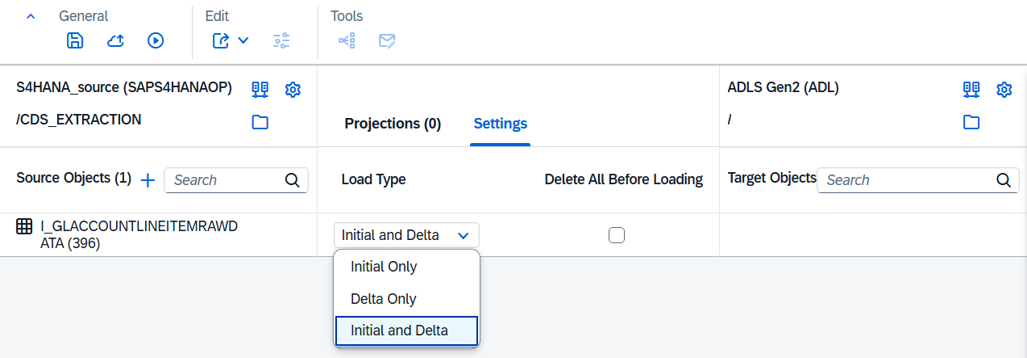
Dans la boîte de dialogue Paramètres d’exécution , vous pouvez ajuster la fréquence de charge de la réplication et ajuster les ressources si nécessaire.
Déployez et exécutez la réplication pour répliquer les données.
Accédez à votre conteneur ADLS Gen2 et vérifiez que les données sont répliquées.




Créer une base de données SAP mise en miroir (via SAP Datasphere)
Cette section explique comment créer la base de données SAP mise en miroir dans Fabric.
Créer un raccourci Lakehouse
Ouvrez le portail Fabric.
Créez un lac ou réutilisez un lac existant.
Dans votre lakehouse, créez un raccourci Azure Data Lake Storage Gen2 vers le conteneur de stockage où SAP Datasphere réplique les données SAP sources. Veillez à sélectionner l’ensemble du conteneur de stockage lors de la création du raccourci :
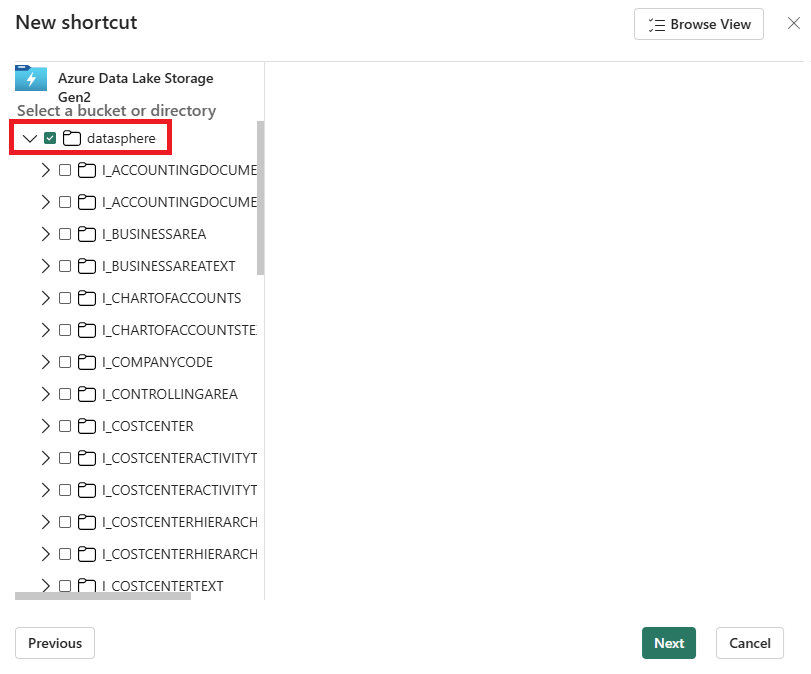
Vérifiez que vous pouvez voir les données SAP dans votre lakehouse sous « Fichiers ».

Créer une base de données mise en miroir
Dans votre espace de travail, sélectionnez Nouvel élément et recherchez SAP mis en miroir.
Sélectionnez le nom du lac contenant le raccourci vers votre conteneur de stockage ADLS Gen2 dans le catalogue OneLake.
Sélectionnez Parcourir et sélectionnez le dossier racine qui contient les données SAP répliquées (
dataspheredans cet exemple). Vous pouvez également entrer directement le chemin de raccourci (omettez le préfixe « Fichiers/ ») dans la zone d’entrée. Sélectionnez OK, puis Suivant.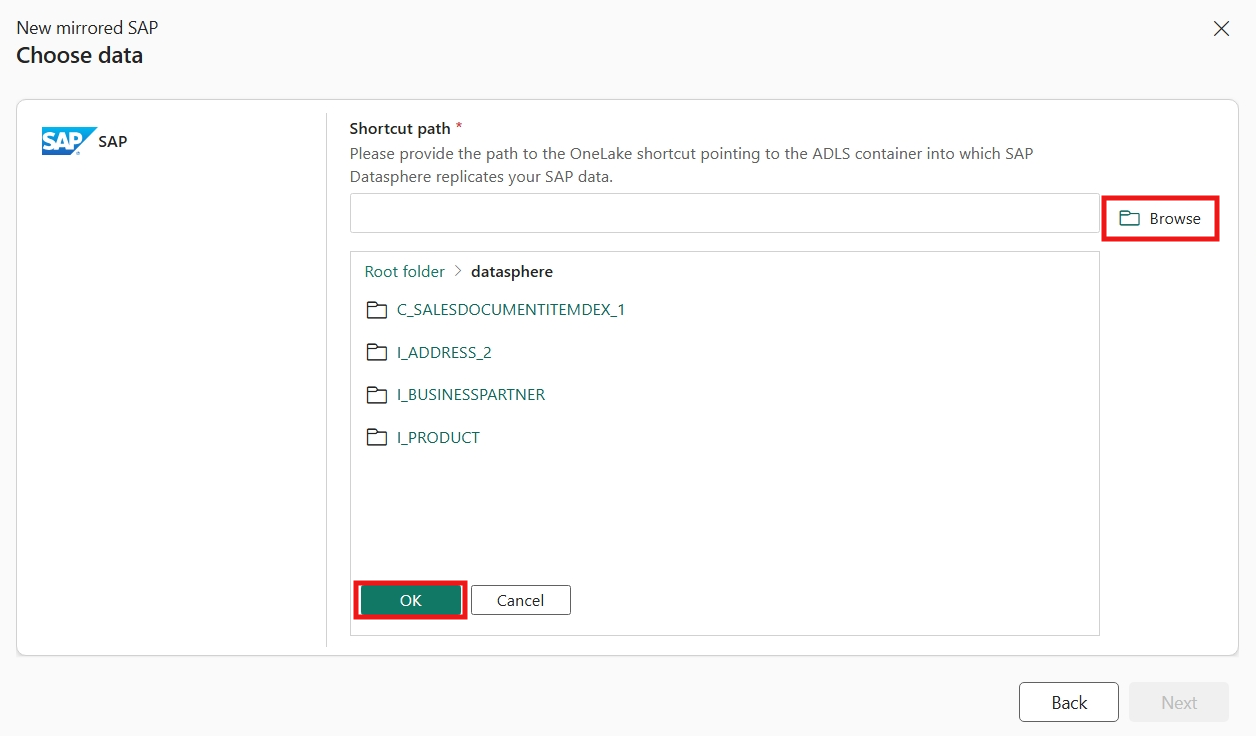
Entrez un nom pour la base de données SAP mise en miroir, puis sélectionnez Créer une base de données mise en miroir.
La mise en miroir commence et vous accédez à la page de surveillance. Après quelques minutes, vous verrez le nombre de lignes répliquées et pouvez afficher vos données dans le point de terminaison d’analyse SQL.
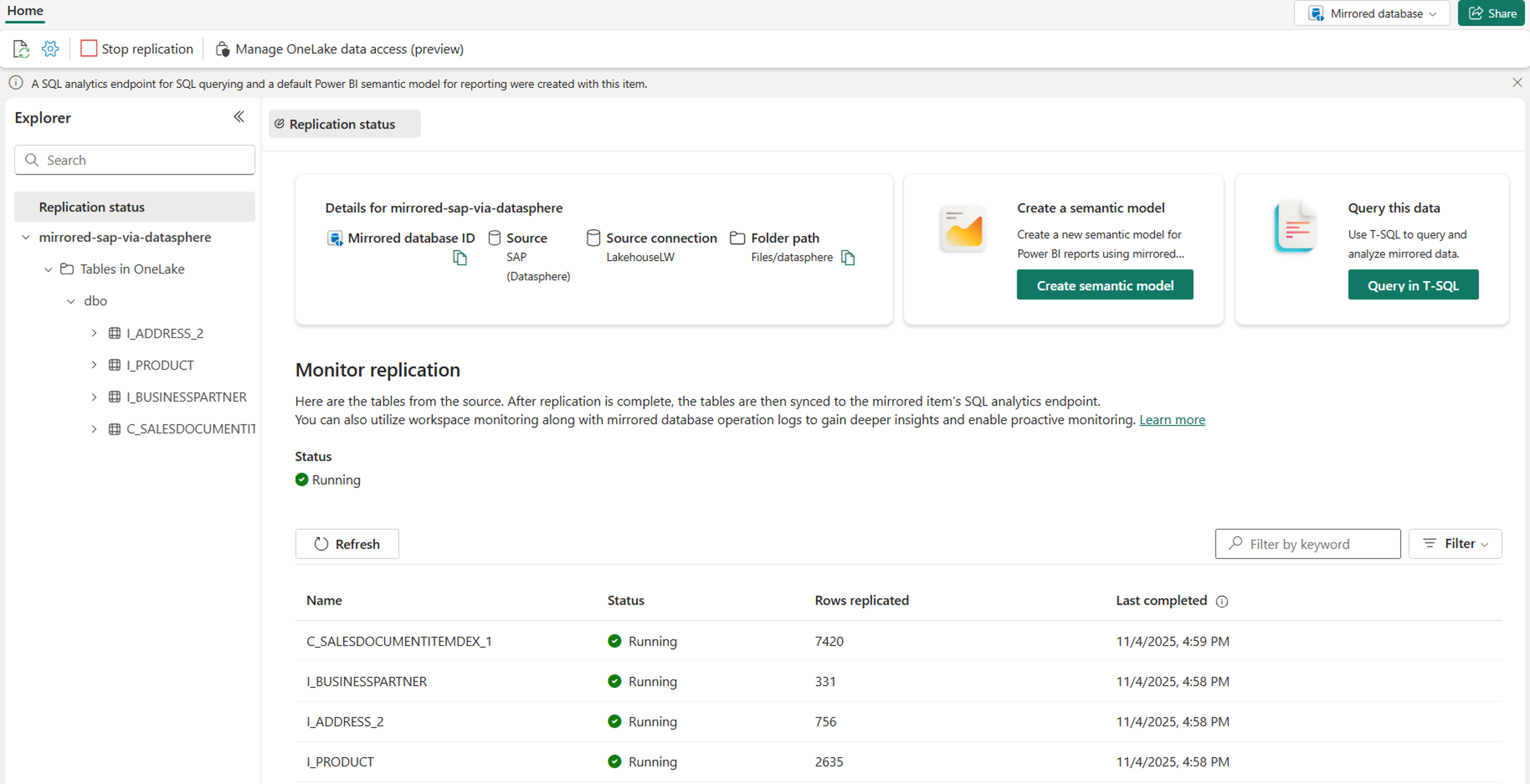


Surveiller la mise en miroir du réseau
Une fois la mise en miroir configurée, vous êtes dirigé vers la page État de la mise en miroir. Ici, vous pouvez surveiller l’état actuel de la réplication. Pour plus d'informations et de détails sur les états de réplication, consultez Monitor Fabric Mirrored Database Replication.