Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Introduction
Les partenaires Microsoft, y compris les éditeurs de logiciels indépendants (ISV) comme vous-même, peuvent créer des solutions d’IA génératives à l’aide de nombreuses approches pro-code et low-code différentes. Pour vous aider dans ce processus, Microsoft crée des conseils pour les éditeurs de logiciels indépendants afin de mieux vous permettre de créer ces solutions.
À mesure que les éditeurs de logiciels indépendants visent à gérer des requêtes et des tâches spécialisées, la complexité de leurs solutions d’INTELLIGENCE artificielle générative augmente. Ces solutions d’INTELLIGENCE artificielle complexes nécessitent des précautions uniques pendant le développement et la surveillance et l’observation cohérentes tout au long de la production. En observant le comportement et les sorties de votre produit, vous pouvez rapidement identifier les domaines de croissance, résoudre rapidement les risques et les problèmes, et générer des performances encore plus élevées pour votre application.
Création et opérationnalisation d’applications copilotes
Pour comprendre comment l’observabilité a un impact sur votre application depuis le début du cycle de vie de la solution, il est essentiel de réfléchir au cycle de vie en trois étapes principales : l’idée sur votre cas d’usage, la création de votre solution et son opérationnalisation pour une utilisation après le déploiement.
Image intitulée Cycle de vie LLM dans le monde réel. Il se compose de trois cercles, reliés à des flèches et entourés d’une flèche plus grande intitulée « gestion ». Le premier cercle est intitulé « Ideating/Explore » et inclut « try prompts », « Hypothèse » et « Find LLMs ». Il provient de la flèche nécessaire pour l’entreprise et est connecté au deuxième cercle avec une flèche intitulée « projet avancé ». Le deuxième cercle est intitulé « Bâtiment/augmentation » et se compose de « récupération de génération augmentée », de « gestion des exceptions », d'« ingénierie rapide ou de réglage précis » et de « évaluation ». Le deuxième cercle se connecte au dernier cercle avec « préparer le déploiement d’applications ». Le dernier cercle est le plus grand, est intitulé « operationalizing » et se compose de « deploy LLM app/UI », « quota and cost management », « content filtering », « safe rollout/staging » et « monitoring ». Le dernier cercle est connecté au deuxième cercle avec « envoyer des commentaires », tandis que le second est connecté au premier avec 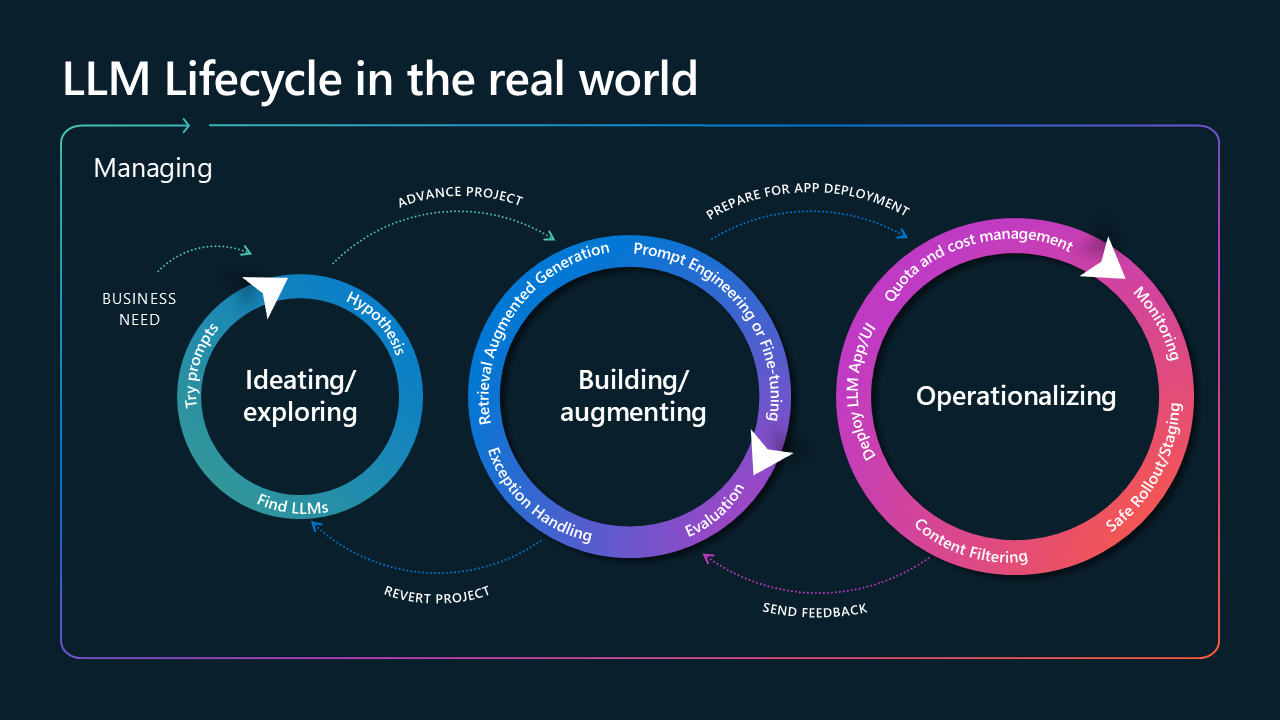
La première phase est constituée de l’identification de votre cas d’usage et de l’idée sur les approches technologiques de la construire. Une fois que vous avez identifié un chemin d’accès à la création de votre application, vous entrez la deuxième phase, qui consiste à développer et à évaluer l’application. Une fois l’application déployée en production, elle entre dans la dernière phase, où elle peut être observée et mise à jour.
Les insights d’observabilité glanés à partir des deuxième et troisième phases deviennent critiques lors du retour aux phases antérieures pour effectuer des mises à jour et des déploiements. En effectuant des tests continus et en récupérant des métriques pour informer les processus antérieurs, vous pouvez maintenir le réglage précis de votre application.
Il est important de comprendre les actions que vous pouvez entreprendre pour pratiquer l’observabilité à différents moments du processus. À un niveau élevé, les actions d’observabilité suivantes se produisent pendant le cycle de vie de l’application :
Première phase
- Les personnes non techniques telles que les responsables de produits pratiquent l’observabilité en utilisant des idées sur les qualités clés de leur application.
- Les parties prenantes peuvent définir les métriques les plus importantes pour mesurer les performances de leur application, telles que les métriques de risque et de sécurité, les métriques de qualité ou les métriques d’exécution.
- Teams peut définir des objectifs pour les métriques telles que l’engagement des utilisateurs et la gestion des coûts.
- Les personnages techniques se concentrent sur l’identification des plateformes, des outils et des méthodes qui peuvent permettre la création de l’application avec succès.
- Cette étape peut inclure le choix d’un modèle à utiliser, le choix d’un modèle de langage volumineux (LLM) et l’identification des sources de données clés à partir de laquelle tirer.
Deuxième phase
- Au cours de cette phase, les développeurs et les scientifiques des données peuvent configurer leur solution pour être facilement surveillés et itérés. Pour promouvoir l’observabilité ultérieurement, les éditeurs de logiciels indépendants peuvent :
- Créez des jeux de données d’or et des jeux de données de conversation à plusieurs tour automatisés pour l’évaluation copilote.
- Déboguer, exécuter et évaluer le flux avec un sous-ensemble de données.
- Créez des variantes pour l’évaluation du modèle avec différentes invites.
- Effectuez la tarification et l’optimisation des ressources adaptées à la réduction des coûts LLM pour itérer et générer.
- Les développeurs se concentrent sur l’exécution d’expériences tout au long du développement et l’évaluation de la qualité de leur application avant de la déployer en production. Au cours de cette phase, il est essentiel de :
- Évaluez les performances globales de l’application avec des jeux de données de test à l’aide de métriques prédéfinies, notamment l’efficacité du modèle et de l’invite.
- Comparez les résultats de ces tests, établissez une base de référence, puis déployez le code en production.
Troisième phase
- De nombreuses expériences sont menées alors que l’application est activement utilisée en production. Il est important de surveiller votre solution pour s’assurer qu’elle fonctionne correctement. Pendant cette phase :
- L’instrumentation de télémétrie incorporée dans l’application émet les traces, métriques et journaux pertinents.
- Les services cloud émettent azure OpenAI Health et d’autres métriques pertinentes.
- Le stockage de télémétrie personnalisé contient des données sur les traces, les métriques, les journaux, l’utilisation, le consentement et d’autres métriques pertinentes.
- Les expériences de tableau de bord prédéfinies permettent aux développeurs, aux scientifiques des données et aux administrateurs de surveiller les performances des API LLM et l’intégrité du système dans l’environnement de production.
- Les commentaires des utilisateurs finaux sont renvoyés aux développeurs et aux scientifiques des données pour l’évaluation afin d’améliorer la solution.
La collecte des données et des données de télémétrie vous donne des informations sur les domaines à traiter et à améliorer à l’avenir. En effectuant des étapes préemptives pendant la phase d’idée, telles que l’identification des métriques appropriées et l’exécution d’évaluations rigoureuses de votre solution lors de la création de votre application, vous pouvez préparer votre solution pour réussir ultérieurement.
Défis d’observabilité dans l’IA générative
Même si l’observabilité en général peut nécessiter des éditeurs de logiciels indépendants pour parcourir de nombreux obstacles, les solutions d’INTELLIGENCE artificielle générative présentent des considérations et des défis spécifiques.
Évaluation qualitative
Étant donné que les réponses d’invite d’IA génératives sont fournies sous forme de langage naturel, elles doivent être évaluées de manière unique. Par exemple, ils peuvent être vérifiés pour des qualités telles que la pertinence et la pertinence.
Les éditeurs de logiciels indépendants doivent prendre en compte le meilleur itinéraire pour mesurer ces qualités, qu’ils choisissent une évaluation manuelle ou des métriques assistées par l’IA avec un humain dans la boucle pour la validation finale.
Quelle que soit la façon dont vous l’évaluez, vous avez probablement besoin de jeux de données préexistants pour comparer vos réponses d’invite. Ces préparations peuvent signifier plus de travail pendant le développement de votre application, car vous identifiez une réponse idéale aux rubriques d’invite courantes.
IA responsable
De nouvelles considérations et attentes en matière d’IA éthique présentent un besoin de surveiller la confidentialité, la sécurité, l’inclusivité et bien plus encore. Les éditeurs de logiciels indépendants doivent surveiller ces attributs afin de promouvoir la sécurité de l’utilisateur final, réduire les risques et réduire les expériences utilisateur négatives.
Les six principes de l’IA responsable de Microsoft aident à promouvoir des systèmes IA fiables, éthiques et dignes de confiance. Pour promouvoir ces valeurs au sein de votre solution, l’évaluation de votre application par rapport à ces normes est essentielle.
Métriques d’utilisation et de surveillance des coûts
Les jetons sont l’unité principale de mesure pour les applications IA génératives, et toutes les invites et réponses sont tokenisées afin qu’elles puissent être mesurées. Le suivi du nombre de jetons utilisés est essentiel, car il affecte le coût d’exécution de votre application.
Métriques de l’utilitaire
La surveillance de la satisfaction des utilisateurs et de l’impact métier de votre application est aussi essentielle que les métriques de performances ou de qualité. Étant donné que l’IA interagit avec les clients de différentes façons, il existe de nouvelles considérations pour la surveillance de l’engagement et de la rétention des clients.
La mesure de l’utilité des réponses de votre IA peut être réalisée de plusieurs façons différentes. Par exemple, les entonnoirs d’invite et de réponse suivent le temps nécessaire pour que l’interaction entraîne une réponse utilisable ou utile. Il est également important de suivre le moment où votre utilisateur s’engage avec l’IA, la longueur de la conversation et le nombre de fois où votre utilisateur accepte la réponse fournie. Dans les scénarios où votre utilisateur peut modifier la réponse, il est essentiel de mesurer la distance de modification ou la mesure dans laquelle il modifie la réponse.
Mesures de performances
L’IA nécessite des systèmes de plus en plus complexes et hautes performances qui doivent être correctement gérés pour garantir que votre solution peut traiter rapidement et efficacement les invites et les données. Comme l’IA générative crée du contenu qualitatif avec un grand degré de variété, il est important d’avoir des systèmes en place pour évaluer et tester votre IA dans différents scénarios.
Étant donné que les interactions LLM sont plus complexes qu’une application classique, elles doivent être mesurées à plusieurs couches pour identifier les problèmes de latence. Par exemple, les temps de jeton de l’invite de votre utilisateur, de générer une réponse et de retourner la réponse à un utilisateur peuvent être mesurés séparément ou dans son ensemble. Chaque composant individuel du flux de travail doit être évalué pour identifier les zones pour les problèmes potentiels.
Votre capacité à observer votre solution dépend également de votre méthode de déploiement. Les éditeurs de logiciels indépendants adoptent généralement l’un des deux modèles de déploiement pour leurs applications copilotes. Vous pouvez déployer et gérer vos applications dans un environnement que vous possédez ou déployer des applications dans un environnement qui appartient à vos clients.
Pour en savoir plus sur la façon dont le déploiement affecte l’observabilité entre les types de solutions, consultez le guide d’observabilité pro-code.
Métriques à surveiller et à évaluer
Dans le domaine isv des applications d’IA générative et des modèles Machine Learning, il est important d’évaluer en permanence votre solution et d’intervenir rapidement pour limiter les comportements indésirables. La surveillance des métriques liées à l’expérience utilisateur ou aux commentaires, aux garde-fous et à l’IA responsable, à la cohérence de la sortie, à la latence et au coût sont essentielles pour optimiser les performances de vos applications copilotes.
Évaluation qualitative à l’aide de métriques assistées par l’IA
Pour mesurer des informations qualitatives, les éditeurs de logiciels indépendants peuvent utiliser des métriques assistées par l’IA pour surveiller leurs solutions. Les métriques assistées par l’IA utilisent des modules LLM comme GPT-4 pour évaluer les métriques de la même façon que le jugement humain, ce qui vous offre une entrée plus nuance sur les fonctionnalités de votre solution.
Ces métriques nécessitent généralement des paramètres tels que la question, la réponse et tout contexte environnant de la conversation. Elles se répartissent en deux catégories :
- Les métriques de risque et de sécurité surveillent le contenu à haut risque, comme la violence, l’auto-préjudice, le contenu sexuel et le contenu haineux
- Les métriques de qualité de génération effectuent le suivi des mesures qualitatives telles que :
- Comment la réponse du modèle s’aligne sur les informations de l’invite ou de la source d’entrée.
- La pertinence de la réponse du modèle est liée à l’invite d’origine.
- Cohérence dans laquelle la réponse du modèle est compréhensible et humaine.
- Fluency- les langues, la grammaire et la syntaxe de la réponse du modèle.
Les métriques comme celles-ci permettent aux éditeurs de logiciels indépendants d’évaluer plus facilement la qualité des réponses de leur application. Ils fournissent une évaluation rapide et mesurable de nombreuses valeurs différentes qui peuvent être difficiles à interpréter.
Normes d’IA responsables
Microsoft s’engage à respecter les normes pour l’IA responsable. Pour ce faire, nous avons établi un ensemble de normes d’IA responsables qui peuvent vous aider à atténuer les risques associés à l’IA générative :
- Responsabilité
- Transparence
- Équité
- Inclusivité
- Fiabilité et sécurité
- Confidentialité et sécurité
Les éditeurs de logiciels indépendants peuvent surveiller les métriques qui les informent lorsqu’un problème se produit. Ces notifications peuvent inclure des métriques qualitatives assistées par l’IA qui filtrent les réponses ou les invites pour du contenu dangereux, ou alertent les éditeurs de logiciels indépendants à certaines erreurs ou messages marqués.
Par exemple, Azure OpenAI propose des solutions qui peuvent mesurer le pourcentage d’invites filtrées et de réponses qui n’ont pas retourné de contenu en raison du filtrage de contenu. Les éditeurs de logiciels indépendants doivent surveiller les invites qui retournent ces erreurs et visent à réduire la quantité qu’elles produisent.
Utilisation et satisfaction des clients
Certaines fonctionnalités de l’IA peuvent être surveillées de la même façon que d’autres types d’applications, telles que la surveillance de la rétention des clients et le temps passé à l’aide de l’application. Toutefois, il existe de nombreuses différences dans la surveillance de la satisfaction des clients qui s’appliquent spécifiquement à l’IA :
- Réaction de l’utilisateur à la réponse. Cela peut être mesuré par le biais de métriques aussi simples que si un utilisateur réagit à une réponse avec un pouce vers le haut ou vers le bas.
- Modifications apportées par l’utilisateur à la réponse. Dans les scénarios où votre utilisateur peut modifier la réponse de votre IA en fonction de ses besoins, des insights peuvent être obtenus en surveillant la quantité de modification de la réponse par votre utilisateur. Par exemple, un e-mail brouillon que l’utilisateur a changé radicalement n’était probablement pas aussi utile qu’un e-mail brouillon envoyé par l’utilisateur tel qu’il l’est.
- Utilisation de la réponse par l’utilisateur. Envisagez de surveiller si votre utilisateur effectue une action par le biais de votre application en réponse à l’IA. Si une IA suggère d’effectuer une action via votre application, mesurez le taux d’utilisateurs qui acceptent la suggestion.
L’objectif de nombreuses applications IA est de créer une réponse que votre utilisateur trouve utile. L’utilisation d’un entonnoir d’invite et de réponse est un moyen courant de mesurer la rapidité avec laquelle votre solution peut générer une réponse utile. Cet entonnoir mesure le temps et les interactions nécessaires à votre solution pour créer une réponse avec laquelle l’utilisateur conserve ou met fin à la conversation.
Dans ce concept, l’entonnoir commence lorsqu’un utilisateur envoie une invite. À mesure que l’IA génère des réponses avec lesquelles l’utilisateur peut interagir, l’entonnoir se limite à mesure que les réponses se rapprochent de ce que l’utilisateur souhaite. Par exemple, l’utilisateur peut modifier la réponse IA ou demander une réponse légèrement différente. Une fois que l’utilisateur est satisfait de l’interaction, il dispose des informations spécifiques qu’il recherchait et de la fin de l’entonnoir. Mesurer le nombre d’interactions qu’il faut pour que votre invite passe de large à utile et spécifique est utile pour déterminer l’efficacité de votre application à votre client.
En observant la façon dont vos utilisateurs interagissent avec votre solution, vous pouvez faire des inférences sur l’utilité de votre application. Si vos utilisateurs utilisent constamment les sorties de votre LLM sans prendre plus d’action, il est probable que la réponse leur était utile.
Supervision des coûts
Comme les ressources nécessaires à l’exécution d’une application IA générative peuvent rapidement s’ajouter, il est essentiel de les observer de manière cohérente.
Voici quelques domaines qui peuvent avoir un impact sur l’optimisation des coûts de votre application :
- Utilisation du GPU
- Coûts de stockage et considérations
- Mise à l'échelle - Éléments à prendre en compte
Garantir la visibilité de ces métriques peut vous aider à maintenir les coûts sous contrôle, tout en configurant des systèmes d’alerte ou des processus automatiques liés à ces métriques peut également être utile pour demander une action immédiate.
Par exemple, le nombre de jetons d’invite et de saisie semi-automatique utilisés par votre application affecte directement l’utilisation de votre GPU et le coût d’exploitation de votre solution. La surveillance étroite de l’utilisation de votre jeton et la configuration des alertes si elle dépasse certains seuils peut vous aider à rester au courant du comportement de votre application.
Disponibilité et performances de la solution
Comme avec toutes les solutions, la surveillance cohérente des applications IA peut aider à générer un niveau élevé de performances. L’une des principales différences entre les applications d’IA génératives et d’autres est le concept de tokenisation, qui doit être pris en compte lors de la mesure des performances.
Les éditeurs de logiciels indépendants qui créent des solutions IA génératives peuvent mesurer :
- Heure d’affichage du premier jeton
- Jetons rendus par seconde
- Demandes par seconde que votre application peut gérer
Bien que toutes ces métriques puissent être mesurées en tant que groupe, il est également important de noter que les machines virtuelles llms ont plusieurs couches. Par exemple, le temps nécessaire à votre IA pour générer une réponse est composé du temps nécessaire pour :
- Recevoir l’invite de l’utilisateur
- Traiter l’invite par le biais de la tokenisation
- Déduire les informations manquantes pertinentes
- Générer une réponse
- Compiler ces informations dans une réponse via la détokenisation
- Renvoyer cette réponse à l’utilisateur
La mesure à chacune de ces étapes peut vous aider à identifier les retards et leur emplacement, ce qui vous permet de résoudre le problème à sa source.
Autres techniques d’évaluation de l’IA générative
Jeux de données golden
Un jeu de données Golden est une collection de réponses d’experts aux questions utilisateur réalistes utilisées pour fournir une assurance qualité copilote. Ces réponses ne sont pas utilisées pour entraîner votre modèle, mais elles peuvent être comparées aux réponses que votre modèle donne à la même question utilisateur.
Bien qu’il ne s’agit pas d’une métrique que vous pouvez mesurer, avoir une réponse standardisée de haute qualité, vous pouvez comparer les réponses de votre LLM pour aider vos sorties de solution. De cette façon, la création de vos propres jeux de données Golden pour évaluer les performances de copilot permet d’accélérer votre processus d’évaluation de copilote.
Simulation de conversation multitour
L’organisation manuelle des jeux de données d’évaluation peut être principalement limitée aux conversations à tour unique en raison de la difficulté à créer des conversations multitours naturels. Au lieu d’écrire des interactions scriptées pour comparer les réponses de votre modèle, les éditeurs de logiciels indépendants peuvent développer des conversations simulées pour tester les capacités de conversation multitour de leurs copilotes.
Cette simulation peut générer un dialogue en permettant à votre IA d’interagir avec un utilisateur virtuel simple. Cet utilisateur interagirait ensuite avec votre IA par le biais d’un script prédéfinis d’invites, ou il les générerait via l’IA, ce qui vous permet de créer un grand nombre de conversations de test à évaluer. Vous pouvez également utiliser des évaluateurs humains pour interagir avec l’application et générer des conversations plus longues à examiner.
En évaluant les interactions de votre application au sein d’une conversation plus longue, vous pouvez évaluer comment elle identifie efficacement l’intention de votre utilisateur et utilise le contexte tout au long de la conversation. Comme de nombreuses solutions d’IA génératives sont destinées à s’appuyer sur plusieurs interactions utilisateur, il est essentiel d’évaluer la façon dont votre application gère les conversations multitours.
Outils de développement commencer
Les développeurs isv et les scientifiques des données doivent utiliser des outils et des métriques pour évaluer leurs solutions LLM. Microsoft dispose de nombreuses options disponibles pour vous permettre d’explorer.
Azure AI Foundry
Azure AI Foundry offre des fonctionnalités d’observabilité pour la gestion des modèles, les benchmarks de modèle, le suivi, l’évaluation et le réglage précis de votre solution LLM.
Il prend en charge deux types de métriques automatisées pour évaluer les applications IA génératives : les métriques ML traditionnelles et les métriques assistées par l’IA. Vous pouvez également utiliser le terrain de jeu de conversation et les fonctionnalités associées tester facilement votre modèle.
Flux rapide
Le flux d’invite est une suite d’outils de développement conçus pour simplifier le cycle de développement de bout en bout des applications IA basées sur LLM, du prototypage et des tests, au déploiement et à la surveillance. Le Kit de développement logiciel (SDK) de flux d’invite fournit les éléments suivants :
- Évaluateurs intégrés qui prennent en charge des évaluateurs personnalisés basés sur du code ou basés sur des invites via Prompty pour répondre aux besoins d’évaluation spécifiques aux tâches.
- Suivi des invites qui effectue le suivi des entrées, des sorties et du contexte des invites et permet aux développeurs d’identifier les causes et les origines des problèmes de modèle
- Tableaux de bord de supervision y compris le système (par exemple, l’utilisation des jetons, la latence) et les métriques personnalisées de l’évaluation pour prendre en charge l’observabilité avant et post-déploiement dans Azure AI Foundry et Application Insights.
Autres outils
Prompty est une classe de ressources indépendante du langage pour la création et la gestion des invites LLM. Il vous permet d’accélérer le processus de développement en fournissant des options de conception, de test et d’amélioration de vos solutions.
PyRIT (Python Risk Identification Tool for Generative AI) est l’infrastructure d’automatisation ouverte de Microsoft pour les systèmes d’IA générative red-teaming. Il vous permet d’évaluer la robustesse de vos copilotes contre différentes catégories de préjudices.
Étapes suivantes
En concevant votre application IA générative avec l’observabilité et la surveillance à l’esprit, vous pouvez évaluer sa qualité du développement par le biais de la production. Commencez à utiliser les outils disponibles pour commencer à développer votre application ou à explorer les options de supervision d’une solution déjà en production.
Ressources complémentaires
Conseils supplémentaires sur l’évaluation de votre application LLM
Bien démarrer dans le flux d’invite - Azure Machine Learning | Microsoft Learn
Informations sur la configuration et le début de l’utilisation du flux d’invite