Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Avant de créer des suggestions, il est essentiel de comprendre leur fonctionnement. Le système récupère d’abord toutes les données basées sur la génération augmentée par récupération (RAG), telles que les tables Dataverse associées au prompt. Il analyse ensuite les documents d’entrée. Enfin, le grand modèle de langage (LLM) traite les informations collectées, combinées aux instructions.
Plus l’entrée combinée est importante, plus le temps de réponse est long, les données documentaires étant le contributeur le plus important.
Nous devons prendre en compte ces points dans le contexte des contraintes de requête :
- L’exécution rapide est limitée à 100 secondes.
- Chaque modèle a une taille maximale autorisée pour l’entrée combinée, incluant les instructions, les données et la réponse du modèle.
- Bien que nous augmentions régulièrement la capacité du GPU, les ressources restent limitées et sont allouées par région et par modèle.
En conséquence, vous pourriez rencontrer des problèmes tels que des délais d’exécution, des limites de fenêtre de jetons atteintes, des temps de réponse incohérents ou une limitation. Les pratiques suivantes peuvent vous aider à minimiser ces problèmes.
Choisissez le modèle le plus efficace pour la tâche
Les modèles plus avancés mettent généralement plus de temps à répondre. Commencez toujours par le modèle Basic pour votre scénario, puis considérez le modèle Standard, et réservez le modèle Premium uniquement aux tâches qui l’exigent réellement.
Exemple : Utiliser un modèle Premium pour une simple tâche d’analyse de sentiment n’est pas nécessaire.
Optimiser la longueur de la sortie du modèle
La longueur de la sortie est le facteur unique le plus important qui influence à la fois le temps de réponse et le coût.
Contraindre le modèle
Lors de la génération de résumés ou de sorties similaires, spécifiez des limites telles que le nombre de mots ou de phrases. Sans contraintes, les réponses des modèles peuvent varier en durée, complexité et temps.
Exemple : Résumez en 50 mots.
Optimiser la structure JSON
Lorsque vous utilisez des sorties JSON, réduisez la complexité en simplifiant la structure et en minimisant le nombre de clés.
Exemple : Ces deux sorties contiennent les mêmes informations, mais la sortie 2 est nettement plus compacte et efficace.
| Sortie 1 | Sortie 2 |
|---|---|
{"extracted data from document":{"Contoso internal policy number": "value"}} |
{"policy":"value"} |
Ne considérez que les informations nécessaires
Évitez de demander au modèle de produire des informations qui ne seront pas utilisées. Le contenu inutile augmente le coût et la latence.
Exemple : Ne demandez au modèle de fournir une raison que si elle est nécessaire pour une validation humaine ou une auditabilité.
Optimiser la taille de l’entrée du modèle
La taille de l’entrée a un impact modéré sur le temps de réponse et le coût, notamment lors du traitement de documents ou d’images.
Éviter la redondance
Répéter des instructions similaires augmente les coûts et peut embrouiller le modèle.
Exemple : Évitez de fournir plusieurs instructions qui transmettent la même exigence.
Convertir les numéros au format américain ... Lors de l’analyse du contenu, utilisez toujours les normes américaines
Soyez concis
Les modèles comprennent des instructions concises et directes. Les courtes consignes sont plus faciles à traiter et livrent souvent des résultats plus précis.
Exemple : Le deuxième prompt est plus efficace.
- Générez un résumé à partir de ce [contenu]. Le résumé doit être professionnel et formaté sous forme de puces.
- Résumez [contenu] sous forme de points clés avec un ton professionnel.
Réduire la taille de l’entrée
Les entrées contiennent souvent du contenu sans rapport pour l’analyse (par exemple, balises HTML, signatures de courriels répétées, texte standard). Prétraitez le contenu lorsque c’est possible, extrayez du texte, effacez la mise en forme ou résumez de grandes sections avant de les envoyer à une requête plus complexe.
Exemple : Utilisez l’action Html to text dans un workflow pour analyser un e-mail en réponse à une invite.
Traitez les documents uniquement lorsque cela est nécessaire
Le traitement des documents est coûteux. Si vous utilisez le même document à plusieurs reprises, extrayez son contenu une fois et réutilisez-le au lieu de le retraiter à chaque fois.
Exemple : Dans cet exemple, le document de directives ne doit pas être traité à chaque exécution mais plutôt fourni à l'invite de commande sous forme de texte. « Considérez ce [document de directive] pour extraire des informations de ce [document à traiter] »
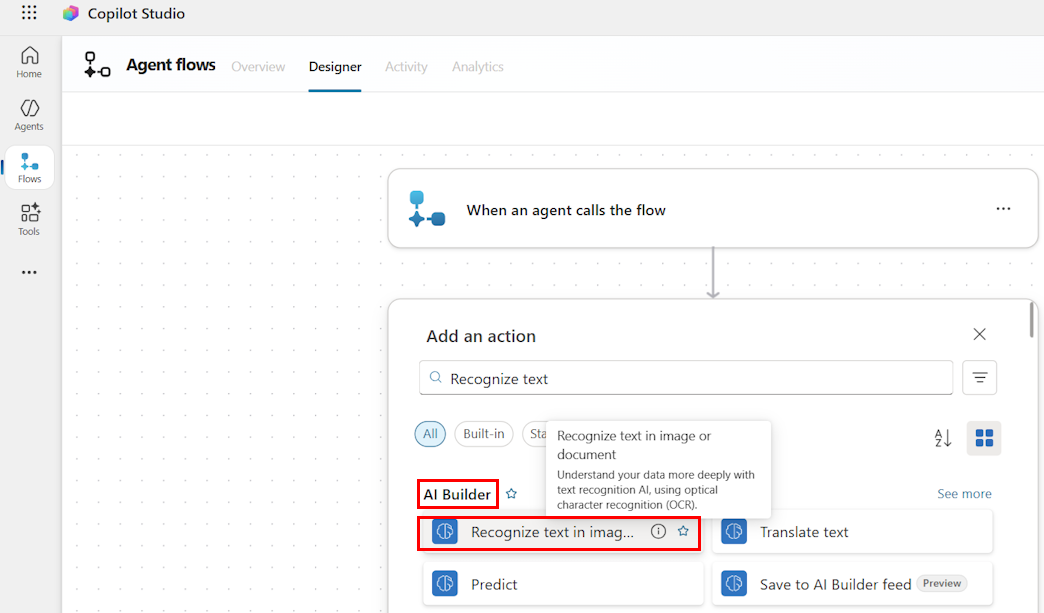
Traiter les documents longs en sections
Les documents longs peuvent entraîner des dépassements de délais ou dépasser les limites de tokens. Lorsque possible, traitez le contenu de manière progressive, page par page, ou en tronquant les pages inutiles à l’avance. Il en va de même pour d’autres types de contenu, comme les e-mails, en ne fournissant que le fil le plus récent.
Exemple : utilisez l’action Reconnaître le texte dans une image ou un document de la catégorie AI Builder pour obtenir le contenu de la page et traiter chaque résultat de page avec une application à chaque.
Utilisez des filtres lors de l’application de la génération augmentée par récupération (RAG)
Lorsque vous ajoutez du contexte métier provenant de sources telles que les tables Dataverse, récupérez uniquement les champs nécessaires et appliquez des filtres pour réduire l’ensemble de données.
Exemple : Filtrez les produits par famille d’appareils informatiques et récupérez uniquement le champ Nom avant de faire correspondre les noms des produits dans un e-mail.