Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Power Automate permet aux utilisateurs de lire, d’extraire et de gérer des données dans un assortiment de fichiers grâce à des technologies de reconnaissance optique de caractères (OCR).
Pour créer un moteur OCR et extraire du texte à partir d’images et de documents avec OCR, utilisez l’action Extraire du texte avec OCR. L’exemple suivant extrait le texte de l’intégralité de l’image spécifiée.
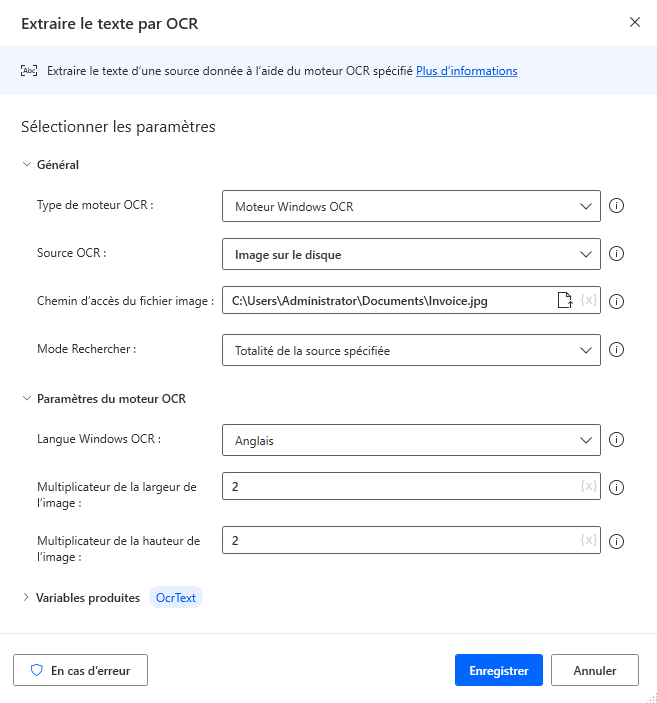
Toutes les actions OCR peuvent créer une nouvelle variable de moteur OCR ou en utiliser une existante. Vous pouvez utiliser des variables du moteur OCR existantes dans toute action contenant des capacités OCR.
Power Automate prend en charge les moteurs OCR Windows et Tesseract. Pour configurer le moteur OCR sélectionné, accédez aux Paramètres du moteur OCR de l’action appropriée. Les options disponibles incluent langue et les multiplicateurs de largeur et de hauteur de l’image.
Note
- Tous les moteurs OCR disponibles sont préinstallés dans Power Automate et travaillent localement sans connexion au cloud. Cependant, vous devrez peut-être télécharger des modules linguistiques ou des fichiers de données pour extraire des textes dans des langues spécifiques.
- Les multiplicateurs d’image augmentent la taille de l’image pour rendre l’extraction ou la recherche de texte plus efficace. Paramétrer des valeurs supérieures à 3 peut conduire à des résultats erronés.
Utiliser le moteur OCR Windows
Le moteur OCR par défaut dans Power Automate est le moteur OCR Windows. Pour extraire des textes à l’aide du moteur OCR Windows, vous devez installer le module linguistique approprié pour la langue que vous souhaitez extraire.
Si le module linguistique approprié n’a pas été installé, Power Automate affiche une erreur pour vous inviter à l’installer. Pour plus d’informations concernant le téléchargement et l’installation des modules linguistiques, accédez à Modules linguistiques pour Windows.
Après avoir installé le module linguistique approprié, étendez les Paramètres du moteur OCR de l’action OCR et sélectionnez la langue souhaitée. Le moteur OCR Windows prend en charge 25 langues : chinois (simplifié et traditionnel), tchèque, danois, néerlandais, anglais, finnois, français, allemand, grec, hongrois, italien, japonais, coréen, norvégien, polonais, portugais, roumain, russe, serbe (cyrillique et latin), slovaque, espagnol, suédois et turc.
Utiliser le moteur OCR Tesseract
Note
Pour utiliser le moteur Tesseract OCR, assurez-vous que le processeur de la machine prend en charge le jeu d’instructions AVX2.
Outre le moteur OCR Windows, Power Automate prend en charge le moteur Tesseract. Ce moteur peut extraire du texte dans cinq langues sans configuration supplémentaire : anglais, allemand, espagnol, français et italien.
Pour extraire du texte dans une langue qui ne figure pas dans la liste mentionnée, activez l’option Utiliser d’autres langues dans les Paramètres du moteur OCR de l’action OCR. Lorsque cette option est activée, l’action affiche deux paramètres supplémentaires : les champs Abréviation de la langue et Chemin d’accès aux données de la langue.
Le champ Abréviation de la langue indique au moteur quelle langue rechercher lors de l’OCR. Le champ Chemin d’accès aux données de la langue contient les fichiers de données de langue (.traineddata) utilisés pour entraîner le moteur OCR. Vous trouverez les fichiers de données de langue pour toutes les langues disponibles dans ce référentiel GitHub.
Vous pouvez également utiliser le moteur Tesseract pour extraire du texte de documents multilingues. Pour plus d’informations concernant l’extraction de texte de documents multilingues, accédez à Effectuer l’OCR sur des documents multilingues.
Si le texte s’affiche à l’écran (OCR)
Marque le début d’un bloc conditionnel d’actions selon qu’un texte sélectionné apparaît sur l’écran ou non, avec OCR.
Paramètres d’entrée
| Argument | Facultatif | Accepte | Valeur par défaut | Description |
|---|---|---|---|---|
| Si le texte | N/A | Existe, N’existe pas | Existe | Indique s’il convient de vérifier si le texte existe ou non sur la source spécifiée à analyser |
| Type de moteur OCR | Non | Moteur OCR Windows, moteur Tesseract, variable du moteur OCR | Variable du moteur OCR | Type de moteur OCR à utiliser. Sélectionnez un moteur OCR préconfiguré ou configurez-en un nouveau. |
| Variable du moteur OCR | Non | OCREngineObject | Moteur à utiliser pour l’opération OCR | |
| Texte à rechercher | Non | Valeur de texte | Texte à rechercher dans la source spécifiée | |
| Est une expression régulière | S.O. | Valeur booléenne | Faux | Indique s’il faut ou non utiliser une expression régulière pour trouver le texte spécifié. |
| Rechercher un texte sur | N/A | Écran entier, Fenêtre de premier plan | Écran total | Indique si le texte spécifié doit être recherché sur l’écran visible pour l’écran, ou uniquement dans la fenêtre de premier plan |
| Mode de recherche | N/A | Ensemble de la source spécifiée, Sous-région spécifique uniquement, Sous-région par rapport à l’image | Totalité de la source spécifiée | Indique s’il faut analyser ou non l’intégralité de l’écran (ou de la fenêtre) ou uniquement à une sous-région réduite |
| Image(s) | Non | Liste des images | Image(s) spécifiant la sous-région (par rapport à l’angle supérieur gauche de l’image) à analyser pour le texte fourni | |
| X1 | Oui | Valeur numérique | Coordonnée X de début de la sous-région à analyser pour le texte fourni | |
| Tolerance | Oui | Valeur numérique | 10 | Indique combien l’image recherchée peut être différente de l’image choisie à la base. |
| Y1 | Oui | Valeur numérique | Coordonnée Y de début de la sous-région à analyser pour le texte fourni | |
| X1 | Oui | Valeur numérique | Coordonnée X de début de la sous-région par rapport à l’image indiquée à analyser pour le texte fourni | |
| X2 | Oui | Valeur numérique | Coordonnée X de fin de la sous-région à analyser pour le texte fourni | |
| Y1 | Oui | Valeur numérique | Coordonnée Y de début de la sous-région par rapport à l’image indiquée à analyser pour le texte fourni | |
| Y2 | Oui | Valeur numérique | Coordonnée Y de fin de la sous-région à analyser pour le texte fourni | |
| X2 | Oui | Valeur numérique | Coordonnée X de fin de la sous-région par rapport à l’image indiquée à analyser pour le texte fourni | |
| Y2 | Oui | Valeur numérique | Coordonnée Y de fin de la sous-région par rapport à l’image indiquée à analyser pour le texte fourni | |
| Langue OCR Windows | S.O. | Chinois (simplifié), chinois (traditionnel), tchèque, danois, néerlandais, anglais, finnois, français, allemand, grec, hongrois, italien, japonais, coréen, norvégien, polonais, portugais, roumain, russe, serbe (cyrillique), serbe (latin), slovaque, espagnol, suédois, turc | Anglais | Langue du texte détecté par le moteur OCR Windows |
| Utiliser une autre langue | S.O. | Valeur booléenne | Faux | Indique s’il faut utiliser ou non une langue non mentionnée dans le champ Langue Tesseract |
| Langue Tesseract | S.O. | Anglais, allemand, espagnol, français, italien | Anglais | Langue du texte de l’image détectée par le moteur Tesseract |
| Abréviation de la langue | Non | Valeur de texte | Abréviation Tesseract de la langue à utiliser. Par exemple, si les données sont « eng.traineddata », définissez ce paramètre sur « eng » | |
| Chemin d’accès aux données de la langue | Non | Valeur de texte | Chemin d’accès du dossier qui contient les données Tesseract spécifiques à la langue | |
| Multiplicateur de la largeur de l’image | Non | Valeur numérique | 1 | Multiplicateur de la largeur de l’image |
| Multiplicateur de la hauteur de l’image | Non | Valeur numérique | 1 | Multiplicateur de la hauteur de l’image |
| Image correspondant à l’algorithme | S.O. | De base, Avancé | De base | Quel algorithme d’image utiliser lors de la recherche d’image |
Note
- Le moteur d’expressions régulières de Power Automate est .NET. Pour plus d’informations concernant les expressions régulières, accédez à Langage d’expression régulière - Référence rapide.
- L’option Variable du moteur OCR devrait être abandonnée.
Variables produites
| Argument | Type | Description |
|---|---|---|
| LocationOfTextFoundX | Valeur numérique | Coordonnée X du point où le texte apparaît à l’écran. Si la recherche est effectuée dans la fenêtre de premier plan, la coordonnée renvoyée est relative au coin supérieur gauche de la fenêtre |
| LocationOfTextFoundY | Valeur numérique | Coordonnée X du point où le texte apparaît à l’écran. Si la recherche est effectuée dans la fenêtre de premier plan, la coordonnée renvoyée est relative au coin supérieur gauche de la fenêtre |
Exceptions
| Exception | Description |
|---|---|
| Impossible de vérifier si le texte existe en mode non interactif | Indique qu’il est impossible de vérifier le texte à l’écran en mode non-interactif. |
| Coordonnées de la sous-région non valides | Indique que les coordonnées de la sous-région spécifiée n’étaient pas valides. |
| Impossible d’analyser le texte par OCR | Indique qu’une erreur s’est produite lors de la tentative d’analyse du texte avec OCR |
| Impossible de créer le moteur OCR | Indique qu’une erreur s’est produite lors de la tentative de création du moteur OCR |
| Le dossier de chemin d’accès aux données n’existe pas. | Indique que le dossier spécifié pour les données de la langue n’existe pas |
| Le module linguistique Windows sélectionné n’est pas installé sur la machine | Indique que le module linguistique Windows sélectionné n’a pas été installé sur la machine |
| Le moteur OCR n’est pas actif | Indique que le moteur OCR n’est pas actif |
Attendre le texte sur l’écran (OCR)
Attendre qu’un texte spécifique apparaisse/disparaisse de l’écran, dans la fenêtre de premier plan ou par rapport à une image sur l’écran ou la fenêtre de premier plan par OCR.
Paramètres d’entrée
| Argument | Facultatif | Accepte | Valeur par défaut | Description |
|---|---|---|---|---|
| Attendre que le texte | N/A | Apparaître, Disparaître | Apparaître | Indique s’il faut attendre que le texte apparaisse ou disparaisse |
| Type de moteur OCR | Non | Moteur OCR Windows, moteur Tesseract, variable du moteur OCR | Variable du moteur OCR | Type de moteur OCR à utiliser. Sélectionnez un moteur OCR préconfiguré ou configurez-en un nouveau. |
| Variable du moteur OCR | Non | OCREngineObject | Moteur à utiliser pour l’opération OCR | |
| Texte à rechercher | Non | Valeur de texte | Texte à rechercher dans la source spécifiée | |
| Est une expression régulière | S.O. | Valeur booléenne | Faux | Indique s’il faut ou non utiliser une expression régulière pour trouver le texte spécifié. |
| Rechercher un texte sur | N/A | Écran entier, Fenêtre de premier plan | Écran total | Indique si le texte spécifié doit être recherché sur l’écran visible pour l’écran, ou uniquement dans la fenêtre de premier plan |
| Mode de recherche | N/A | Ensemble de la source spécifiée, Sous-région spécifique uniquement, Sous-région par rapport à l’image | Totalité de la source spécifiée | Indique s’il faut analyser ou non l’intégralité de l’écran (ou de la fenêtre) ou uniquement à une sous-région réduite |
| Image(s) | Non | Liste des images | Image(s) spécifiant la sous-région (par rapport à l’angle supérieur gauche de l’image) à analyser pour le texte fourni | |
| X1 | Oui | Valeur numérique | Coordonnée X de début de la sous-région à analyser pour le texte fourni | |
| Tolerance | Oui | Valeur numérique | 10 | Indique combien l’image recherchée peut être différente de l’image choisie à la base. |
| Y1 | Oui | Valeur numérique | Coordonnée Y de début de la sous-région à analyser pour le texte fourni | |
| X1 | Oui | Valeur numérique | Coordonnée X de début de la sous-région par rapport à l’image indiquée à analyser pour le texte fourni | |
| X2 | Oui | Valeur numérique | Coordonnée X de fin de la sous-région à analyser pour le texte fourni | |
| Y1 | Oui | Valeur numérique | Coordonnée Y de début de la sous-région par rapport à l’image indiquée à analyser pour le texte fourni | |
| Y2 | Oui | Valeur numérique | Coordonnée Y de fin de la sous-région à analyser pour le texte fourni | |
| X2 | Oui | Valeur numérique | Coordonnée X de fin de la sous-région par rapport à l’image indiquée à analyser pour le texte fourni | |
| Y2 | Oui | Valeur numérique | Coordonnée Y de fin de la sous-région par rapport à l’image indiquée à analyser pour le texte fourni | |
| Langue OCR Windows | S.O. | Chinois (simplifié), chinois (traditionnel), tchèque, danois, néerlandais, anglais, finnois, français, allemand, grec, hongrois, italien, japonais, coréen, norvégien, polonais, portugais, roumain, russe, serbe (cyrillique), serbe (latin), slovaque, espagnol, suédois, turc | Anglais | Langue du texte détecté par le moteur OCR Windows |
| Utiliser une autre langue | S.O. | Valeur booléenne | Faux | Indique s’il faut utiliser ou non une langue non mentionnée dans le champ Langue Tesseract |
| Langue Tesseract | S.O. | Anglais, allemand, espagnol, français, italien | Anglais | Langue du texte de l’image détectée par le moteur Tesseract |
| Abréviation de la langue | Non | Valeur de texte | Abréviation Tesseract de la langue à utiliser. Par exemple, si les données sont « eng.traineddata », définissez ce paramètre sur « eng » | |
| Chemin d’accès aux données de la langue | Non | Valeur de texte | Chemin d’accès du dossier qui contient les données Tesseract spécifiques à la langue | |
| Multiplicateur de la largeur de l’image | Non | Valeur numérique | 1 | Multiplicateur de la largeur de l’image |
| Multiplicateur de la hauteur de l’image | Non | Valeur numérique | 1 | Multiplicateur de la hauteur de l’image |
| Image correspondant à l’algorithme | S.O. | De base, Avancé | De base | Quel algorithme d’image utiliser lors de la recherche d’image |
| Échec avec erreur du délai d’attente | S.O. | Valeur booléenne | Faux | Indiquer si vous souhaitez que l’action attende indéfiniment ou échoue après une période définie |
Note
- Le moteur d’expressions régulières de Power Automate est .NET. Pour plus d’informations concernant les expressions régulières, accédez à Langage d’expression régulière - Référence rapide.
- L’option Variable du moteur OCR devrait être abandonnée.
Variables produites
| Argument | Type | Description |
|---|---|---|
| LocationOfTextFoundX | Valeur numérique | Coordonnée X du point où le texte apparaît à l’écran. Si la recherche est effectuée dans la fenêtre de premier plan, la coordonnée renvoyée est relative au coin supérieur gauche de la fenêtre |
| LocationOfTextFoundY | Valeur numérique | Coordonnée X du point où le texte apparaît à l’écran. Si la recherche est effectuée dans la fenêtre de premier plan, la coordonnée renvoyée est relative au coin supérieur gauche de la fenêtre |
Exceptions
| Exception | Description |
|---|---|
| Impossible de vérifier si le texte existe en mode non interactif | Indique qu’il est impossible de vérifier le texte à l’écran en mode non-interactif. |
| Coordonnées de la sous-région non valides | Indique que les coordonnées de la sous-région spécifiée n’étaient pas valides. |
| Impossible d’analyser le texte par OCR | Indique qu’une erreur s’est produite lors de la tentative d’analyse du texte avec OCR |
| Impossible de créer le moteur OCR | Indique qu’une erreur s’est produite lors de la tentative de création du moteur OCR |
| Le dossier de chemin d’accès aux données n’existe pas. | Indique que le dossier spécifié pour les données de la langue n’existe pas |
| Le module linguistique Windows sélectionné n’est pas installé sur la machine | Indique que le module linguistique Windows sélectionné n’a pas été installé sur la machine |
| Le moteur OCR n’est pas actif | Indique que le moteur OCR n’est pas actif |
| Erreur de temporisation | Indique que l’action a échoué après une période définie |
Extraire le texte par OCR
Extraire le texte d’une source donnée à l’aide du moteur OCR donné.
Paramètres d’entrée
| Argument | Facultatif | Accepte | Valeur par défaut | Description |
|---|---|---|---|---|
| Moteur OCR | Non | Moteur OCR Windows, moteur Tesseract, variable du moteur OCR | Variable du moteur OCR | Type de moteur OCR à utiliser. Sélectionner un moteur OCR préconfiguré ou en configurer un nouveau |
| Variable du moteur OCR | Non | OCREngineObject | Moteur à utiliser pour l’opération OCR | |
| Source OCR | N/A | Écran, Fenêtre de premier plan, Image sur disque | Écran | Chemin source de l’image sur laquelle effectuer l’opération OCR |
| Chemin d’accès du fichier image | Non | Fichier | Chemin d’accès de l’image sur laquelle effectuer l’opération OCR | |
| Mode de recherche | N/A | Ensemble de la source spécifiée, Sous-région spécifique uniquement, Sous-région par rapport à l’image | Totalité de la source spécifiée | Mode sélectionné pour l’opération OCR |
| Image | Non | Liste des images | Image à utiliser pour limiter l’analyse à une sous-région par rapport à l’image spécifiée | |
| Tolerance | Oui | Valeur numérique | 10 | Indique combien l’image peut être différente de l’image choisie à la base. |
| X1 | Oui | Valeur numérique | Coordonnée X de début de la sous-région à réduire pour l’analyse | |
| X2 | Oui | Valeur numérique | Coordonnée X de fin de la sous-région à réduire pour l’analyse | |
| Y1 | Oui | Valeur numérique | Coordonnée Y de début de la sous-région à réduire pour l’analyse | |
| Y2 | Oui | Valeur numérique | Coordonnée Y de fin de la sous-région à réduire pour l’analyse | |
| Langue OCR Windows | S.O. | Chinois (simplifié), chinois (traditionnel), tchèque, danois, néerlandais, anglais, finnois, français, allemand, grec, hongrois, italien, japonais, coréen, norvégien, polonais, portugais, roumain, russe, serbe (cyrillique), serbe (latin), slovaque, espagnol, suédois, turc | Anglais | Langue du texte détecté par le moteur OCR Windows |
| Utiliser une autre langue | S.O. | Valeur booléenne | Faux | Indique s’il faut utiliser ou non une langue non mentionnée dans le champ Langue Tesseract |
| Langue Tesseract | S.O. | Anglais, allemand, espagnol, français, italien | Anglais | Langue du texte de l’image détectée par le moteur Tesseract |
| Abréviation de la langue | Non | Valeur de texte | Abréviation Tesseract de la langue à utiliser. Par exemple, si les données sont « eng.traineddata », définissez ce paramètre sur « eng » | |
| Chemin d’accès aux données de la langue | Non | Valeur de texte | Chemin d’accès du dossier qui contient les données Tesseract spécifiques à la langue | |
| Multiplicateur de la largeur de l’image | Non | Valeur numérique | 1 | Multiplicateur de la largeur de l’image |
| Multiplicateur de la hauteur de l’image | Non | Valeur numérique | 1 | Multiplicateur de la hauteur de l’image |
| Attendre l’apparition de l’image | S.O. | Valeur booléenne | Vrai | Indique s’il faut attendre ou non que l’image s’affiche à l’écran ou dans la fenêtre de premier plan |
| Délai d’attente | Non | Valeur numérique | 5 | Indique le temps d’attente de fin de l’opération avant l’échec de l’action |
| Image correspondant à l’algorithme | S.O. | De base, Avancé | De base | Quel algorithme d’image utiliser lors de la recherche d’image |
Note
L’option Variable du moteur OCR devrait être abandonnée.
Variables produites
| Argument | Type | Description |
|---|---|---|
| OcrText | Valeur de texte | Résultat après l’extraction de texte |
Exceptions
| Exception | Description |
|---|---|
| Impossible d’extraire le texte par OCR | Indique qu’une erreur s’est produite lors de la tentative d’extraction du texte par OCR à partir de la source spécifiée. |
| Fichier image introuvable | Indique que le fichier n’existe pas sur le chemin d’accès donné. |
| Image de repère introuvable | Indique que l’image de repère n’existe pas. |
| Impossible d’obtenir le texte à l’écran en mode non interactif | Indique qu’il est impossible d’obtenir le texte à l’écran en mode non-interactif |
| Impossible de créer le moteur OCR | Indique qu’une erreur s’est produite lors de la tentative de création du moteur OCR |
| Le dossier de chemin d’accès aux données n’existe pas. | Indique que le dossier spécifié pour les données de la langue n’existe pas |
| Le module linguistique Windows sélectionné n’est pas installé sur la machine | Indique que le module linguistique Windows sélectionné n’a pas été installé sur la machine |
| Le moteur OCR n’est pas actif | Indique que le moteur OCR n’est pas actif |