Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
DirectQuery dans Power BI vous permet de conserver les données dans la source et de les interroger au moment du rapport au lieu de les importer. Cet article explique quand utiliser DirectQuery, ses limitations et alternatives telles que les tables hybrides, Direct Lake et les connexions actives afin de pouvoir choisir le mode approprié.
Cet article aborde les points suivants :
- Power BI modes de connectivité des données et où s'insère DirectQuery
- Quand utiliser DirectQuery ou Importer, tables hybrides, Direct Lake ou une connexion dynamique
- Limitations, implications et considérations relatives aux performances
- Recommandations pour la modélisation et la conception de rapports
- Diagnostiquer et améliorer les performances
Note
DirectQuery est également une fonctionnalité de SQL Server Analysis Services. Bien qu’il existe des similitudes, cet article se concentre sur DirectQuery avec Power BI modèles sémantiques.
Pour plus d’informations sur les modèles composites, consultez Utilisez des modèles composites dans Power BI Desktop. Téléchargez le fichier PDF DirectQuery dans SQL Server 2016 Analysis Services à partir de Microsoft.
Guide de décision rapide
Le tableau suivant résume le mode de connectivité Power BI à prendre en compte en fonction de vos besoins. Utilisez-la comme référence rapide pour vous aider à choisir entre Importer, DirectQuery, tables hybrides, Direct Lake ou connexions actives :
| Si vous avez besoin | Envisagez d’abord | Pourquoi |
|---|---|---|
| Flexibilité maximale d’interactivité et de transformation complète | Import | Moteur en colonnes en mémoire et fonctionnalités de modélisation enrichies |
| Modifications en temps quasi réel sur les données de faits récentes et le contexte historique | Table hybride (partition Import et DirectQuery) | Interroge la source de données chaudes et met en cache les données historiques. |
| Grande échelle de lakehouse ou d’entrepôt avec des lectures à faible latence (Fabric) | Direct Lake | Contourne l’actualisation planifiée et conserve les comportements d’importation |
| Accès fédéré à plusieurs sources externes sans ingestion complète | DirectQuery (modèle composite) | Laisse les données en place et fusionne les sources. |
| Modèle d’entreprise administré central déjà publié | Connexion en direct au modèle sémantique ou aux services d'analyse | Réutilise le modèle organisé et évite la duplication. |
| Envoyer des paramètres à la source au moment de l’exécution (filtrage piloté par l’utilisateur) | DirectQuery avec des paramètres M dynamiques | Réduit les données analysées et améliore les performances. |
| Défis liés à la concurrence élevée et à la latence à distance | Importer ou agrégations avec DirectQuery | Les agrégations accélèrent les requêtes courantes |
Power BI modes de connectivité des données
Power BI se connecte à de nombreuses sources de données :
- Services en ligne tels que Salesforce et Dynamics 365
- Bases de données telles que SQL Server, PostgreSQL, MySQL, Oracle, Snowflake et Amazon Redshift
- Fichiers (Excel, CSV, JSON, Parquet)
- Moteurs Big Data et d’analytique tels que Spark et Databricks
- D’autres sources telles que des sites web et des Microsoft Exchange
Importez des données à partir de ces sources. Certains prennent également en charge DirectQuery. Pour obtenir une liste gérée, consultez Power BI sources de données. Les sources avec DirectQuery fournissent généralement des performances de requête d’agrégation interactives.
Utilisez l’importation par défaut. Il utilise le moteur en mémoire hautes performances de Power BI et fournit l'ensemble de fonctionnalités le plus riche. Passez au-delà de l’importation uniquement lorsque des contraintes spécifiques (latence, taille, gouvernance, sécurité ou architecture) l’exigent.
Améliorations modernes : tables hybrides, Direct Lake, agrégations automatiques, modèles composites et actualisation incrémentielle, réduisez la fréquence à laquelle vous avez besoin de DirectQuery pur.
Les sections suivantes couvrent les modes Import, DirectQuery et Live Connection. Le reste de l’article se concentre sur DirectQuery, tout en reconnaissant d’autres approches.
Connexions d’importation
Lorsque vous importez des données :
- Obtenir des sélections de données définissent des requêtes par jeu de tables ; vous pouvez les mettre en forme (filtre, agrégat, jointure) avant le chargement.
- Toutes les données définies par ces requêtes sont chargées dans le cache en mémoire du modèle sémantique.
- La création de visuels interroge uniquement les données mises en cache rapidement et de manière entièrement interactive.
- Les visuels ne reflètent pas les modifications sources tant que vous n’avez pas actualisé (réimporter).
- La publication charge un modèle sémantique contenant les données importées. Vous pouvez planifier l’actualisation (la fréquence dépend de la licence) et peut avoir besoin d’une passerelle de données locale.
- La création ou l’ouverture de rapports dans le service utilise les données importées.
- Les vignettes de tableau de bord épinglées se rafraîchissent lorsque le modèle sémantique est actualisé.
Connexions DirectQuery
Quand vous utilisez DirectQuery :
- Obtenir des données établit une connexion à une source prise en charge. Pour les sources relationnelles, vous pouvez toujours sélectionner des tables ou des vues ; pour les sources multidimensionnelles (par exemple SAP BW), vous sélectionnez le modèle source.
- Aucune donnée n’est importée au moment du chargement. Chaque visuel déclenche une ou plusieurs requêtes vers la source sous-jacente.
- La latence d’actualisation visuelle dépend entièrement des performances de la source sous-jacente (et de la surcharge réseau/passerelle le cas échéant).
- Les modifications apportées aux données sources s’affichent uniquement après des actions qui exécutent une requête secondaire (navigation, segmenter/filtre, actualisation manuelle).
- La publication crée une définition de modèle sémantique (schéma et métadonnées) sans données importées.
- Les rapports du service interrogent la source. Une passerelle peut être nécessaire pour les sources locales.
- Les vignettes de tableau de bord basées sur les modèles DirectQuery sont actualisées selon une planification pour mettre en cache les résultats des vignettes pour une ouverture rapide du tableau de bord.
- Les vignettes du tableau de bord affichent les résultats de leur dernière actualisation planifiée, sauf si elles sont actualisées manuellement.
Connexions actives
Une connexion active connecte Power BI directement à un modèle sémantique existant (par exemple Analysis Services ou un autre modèle sémantique publié Power BI). Il est similaire à DirectQuery (aucune donnée importée), mais la sémantique (comme l’application de rôle) est gérée par le modèle en amont. Lorsque vous vous connectez en direct :
- La liste complète des champs de modèle externe s’affiche : aucune définition de requête Power Query.
- Les connexions actives transmettent toujours l’identité de l’utilisateur à Analysis Services ou au modèle sémantique Power BI pour le filtrage de sécurité.
- Certaines activités de modélisation (comme l’ajout de tables calculées) ne sont pas disponibles, car le modèle est externe.
Où DirectQuery s’intègre parmi les options plus récentes
DirectQuery était la solution principale pour les données très volumineuses ou à variation rapide que vous n’avez pas pu importer efficacement. Aujourd’hui:
- Les tables hybrides vous permettent de combiner des partitions en mémoire et DirectQuery dans une table (récentes et historiques).
- Direct Lake (Fabric) permet un accès quasi en temps réel aux tables de données de type "lakehouse" sans surcharge d’actualisation traditionnelle.
- Les agrégations automatiques et les tables d’agrégation manuelle accélèrent les requêtes fréquentes.
- L’actualisation incrémentielle avec temps réel permet à la fenêtre de temps la plus récente de DirectQuery de sourcer tandis que les données plus anciennes restent importées.
Évaluez ces options avant d’adopter un modèle DirectQuery complet.
Pour les charges de travail de séries temporelles en temps réel et à haut volume sur Microsoft Fabric, un modèle courant est DirectQuery vers une base de données Fabric KQL (Intelligence en Temps Réel) en combinaison avec des agrégations côté source et des paramètres M dynamiques. Consultez les considérations relatives à la source basée sur Kusto pour obtenir des conseils sur cette charge de travail.
Cas d’usage DirectQuery
DirectQuery est le plus bénéfique quand :
- Les modifications de données sont trop fréquentes pour l’importation (même avec l’actualisation incrémentielle et la fréquence d’actualisation planifiée maximale) et vous avez besoin d’une visibilité à faible latence.
- Les contraintes de volume de données ou de gouvernance rendent l’ingestion complète irréalisable.
- La sécurité appliquée par la source (règles de ligne affinées) doit rester faisant autorité via la passe passthrough.
- La souveraineté des données ou les règles réglementaires limitent les copies complètes persistantes.
- La source est centrée sur les valeurs multidimensionnelles ou les mesures (comme SAP BW) et les mesures définies par serveur doivent être résolues pour chaque visuel.
Les modifications de données sont fréquentes et vous avez besoin de rapports quasiment en temps réel
Les modèles importés (Pro) peuvent planifier jusqu’à 8 actualisations par jour (plus déclencheurs à la demande/API). Premium et PPU prennent en charge jusqu’à 48 actualisations planifiées par jour, ainsi que l’actualisation incrémentielle et DirectQuery en temps réel sur la dernière partition (Hybride). Si votre latence requise ne peut toujours pas être remplie , ou que l’importation complète est irrécible, utilisez DirectQuery, les tables hybrides ou Direct Lake. Les tableaux de bord DirectQuery peuvent actualiser les vignettes aussi souvent que toutes les 15 minutes.
Les données sont volumineuses
L’importation complète peut dépasser la mémoire ou actualiser les fenêtres. DirectQuery interroge les données en place. Si la source est trop lente pour les performances interactives, envisagez les éléments suivants :
- Importation uniquement de sous-ensembles agrégés ou filtrés.
- Utilisation de l’actualisation incrémentielle et des agrégations.
- Utilisation de tables hybrides ou Direct Lake pour les segments récents et à valeur élevée.
Consultez les grands modèles sémantiques dans Power BI Premium pour la gestion des données volumineuses en mémoire.
Sécurité appliquée à la source
L’importation s’appuie sur les informations d’identification Power BI ainsi que la sécurité au niveau des lignes (RLS) facultative définie dans le modèle sémantique. DirectQuery peut (lorsqu’il est pris en charge) transmettre l’identité utilisateur (SSO) afin que la source applique ses propres règles de sécurité. Consultez Overview de l’authentification unique (SSO) pour les passerelles de données locales dans Power BI.
Restrictions de souveraineté des données
Lorsque les réglementations exigent que les données restent dans une limite contrôlée, DirectQuery limite la persistance des copies. Les caches visuels et de vignettes peuvent toujours contenir des données agrégées limitées.
Source avec des mesures définies par le serveur
Certains systèmes (comme SAP BW) contiennent une logique sémantique (mesures et hiérarchies) que vous résolvez au moment de la requête. DirectQuery permet la résolution par visualisation. Consultez DirectQuery et SAP BW et DirectQuery et SAP HANA.
Considérations spécifiques à la source (y compris PostgreSQL et MySQL)
Le comportement et les performances diffèrent selon le moteur :
- PostgreSQL : Les identificateurs entre guillemets respectent la casse. Vérifiez la présence des index b-tree appropriés sur les colonnes de jointure et de filtre. Évitez les fonctions qui interrompent le repli des requêtes prématurément. Vérifiez les conversions implicites sur les jointures texte et numériques.
-
MySQL : Utilisez des classements cohérents et des modes SQL. Créez des index composites pour les modèles de filtre et de jointure courants. Les colonnes volumineuses
TEXTpeuvent réduire le pliage ou forcer le posttraitement. - Snowflake, BigQuery et Databricks : La mise à l’échelle élastique améliore la concurrence, mais la latence de démarrage à froid peut affecter la première requête. Envoyez des pings de préchauffement ou planifiez une activité périodique.
- Azure Synapse, SQL et Fabric Warehouse : les index Columnstore et la mise en cache du jeu de résultats offrent une amélioration significative des performances. Associez-les à des agrégations automatiques.
- sources Kusto (bases de données Azure Data Explorer et Fabric KQL) : L'élagage de projection est important. Sélectionnez uniquement les colonnes requises et appliquez les filtres de façon anticipée. Pour la télémétrie de série chronologique à volume élevé, utilisez l’agrégation côté source plutôt que le regroupement côté client : push
make-series,summarizeetseries_decompose_anomaliesvers le moteur KQL et retournez des résultats agrégés aux visualisations. Vérifiez que les étapes de Power Query se plient en KQL natif afin que les résultats résumés, et non les événements bruts, soient renvoyés à Power BI. - SAP BW et SAP HANA : la résolution des mesures et la sémantique des hiérarchies influencent les schémas de requête. Évitez les transformations de superposition qui bloquent le pliage.
Confirmez le pliage des requêtes (sélectionnez Afficher la requête native dans l'Éditeur Power Query) afin que les transformations soient effectuées.
Limitations de DirectQuery
L’utilisation de DirectQuery a des implications sur la cohérence, les performances, la sécurité, les transformations, la modélisation et les rapports.
Implications générales
Les implications générales suivantes s’appliquent lors de l’utilisation de DirectQuery dans Power BI :
- Actualisez pour afficher les données les plus récentes. Les caches (visuel, vignette, résultat) signifient qu’un visuel peut afficher les résultats antérieurs jusqu’à ce qu’il soit actualisé. Sélectionnez Actualiser pour forcer une nouvelle requête de tous les éléments visuels de la page.
- Les visuels ne sont pas toujours cohérents dans le temps. Différents visuels (ou requêtes internes dans un seul visuel) peuvent s’exécuter à des moments légèrement différents. Actualisez la page ou concevez des instantanés agrégés si une précision précise à un point dans le temps strict est requise.
- Les modifications de schéma nécessitent une actualisation Power BI Desktop. Le service ne détecte pas automatiquement les colonnes supprimées ou renommées. Ouvrez le modèle dans Power BI Desktop et actualisez pour rapprocher les métadonnées du modèle.
- Limite de résultat intermédiaire d’un million de lignes. Toute requête (ou opération intermédiaire) qui retourne plus de 1 000 000 lignes échoue. Les capacités Premium peuvent augmenter cette limite : voir Nombre maximal d’ensembles de lignes intermédiaires.
- La modification du mode de stockage est limitée. Vous ne pouvez pas basculer globalement un modèle Import-only vers DirectQuery. Voir la section suivante.
Important
Étant donné que le moteur qui stocke et interroge les données dans Power BI est insensible à la casse, faites preuve de prudence lorsque vous travaillez en mode DirectQuery avec une source sensible à la casse. Power BI part du principe que la source a éliminé les lignes dupliquées. Étant donné que Power BI ne respecte pas la casse, il traite deux valeurs qui diffèrent uniquement par cas comme dupliquées, tandis que la source peut ne pas les traiter comme telles. Dans ce cas, le résultat final n’est pas défini.
Pour éviter cette situation, si vous utilisez le mode DirectQuery avec une source de données sensible à la casse, normalisez la casse dans la requête source ou dans Éditeur Power Query.
Modification des modes de stockage (Importer ↔ DirectQuery)
Vous ne pouvez pas basculer l’intégralité d’un modèle d’importation vers DirectQuery. Au lieu de:
- Ajoutez une nouvelle connexion DirectQuery à la même source et mappez vers les nouvelles tables.
- Créez un modèle composite : maintenez les dimensions d’importation, ajoutez des tables de faits DirectQuery (ou inversement), et définissez éventuellement certaines tables en mode Dual.
- Utilisez des tables hybrides (partitions DirectQuery récentes et importation historique) pour l’optimisation à chaud et à froid.
- Rebâtissez avec des transformations compatibles avec le repli si des étapes précédentes empêchent DirectQuery.
Note
Les tables individuelles ajoutées via une connexion compatible DirectQuery peuvent basculer entre DirectQuery, Import et Dual si toutes les transformations appliquées sont toujours pliables.
Implications en matière de performances et de charge
Les performances interactives dépendent de la latence source et de la concurrence. Visez des temps d'actualisation visuelle courants de moins de 5 secondes ; plus de 30 secondes réduisent l'utilisabilité. Chaque action utilisateur déclenche des requêtes. Un nombre élevé d’utilisateurs, de visuels et d’actualisation des vignettes peut créer une charge importante : prévoyez la capacité en conséquence.
Implications en matière de sécurité
Sauf si l’authentification unique est configurée, DirectQuery utilise des informations d’identification stockées configurées pour tous les utilisateurs. Définissez RLS dans le modèle sémantique en fonction des besoins. Plusieurs sources dans des modèles composites peuvent déplacer des données entre des sources ; évaluer le déplacement des données sensibles : consultez les implications en matière de sécurité.
Limitations de la transformation des données
Le pliage des requêtes Power Query est nécessaire pour des performances évolutives. Les transformations doivent se condenser en une seule requête native. Les étapes complexes (opérations non repliables, certaines fonctions personnalisées, logique procédurale en plusieurs étapes) peuvent entraîner des erreurs qui nécessitent une simplification ou un passage à l'importation. Les sources OLAP telles que SAP BW interdisent les transformations dans les requêtes, car l’ensemble du modèle externe est exposé. Les appels de procédure stockée et les expressions de table courantes (CTEs) ne sont pas pris en charge d’une manière qui permet le pliage dans DirectQuery.
Limitations de la modélisation
La plupart des enrichissements fonctionnent, mais certaines fonctionnalités sont réduites :
- Aucune hiérarchie de dates automatique (créer une table Date explicite).
- Précision de temps limitée à quelques secondes (supprimez les millisecondes à la source).
- Colonnes calculées limitées aux expressions de niveau ligne qui se replient ; fonctions non prises en charge exclues de l'auto-complétion.
- Aucune fonction PATH parent-enfant.
- Clustering non pris en charge.
Limitations des rapports
La plupart des visuels fonctionnent si la source est réactive. Regardez ces limitations et considérations relatives aux performances :
- Les colonnes de texte longues supérieures à 32 764 caractères ne sont pas prises en charge.
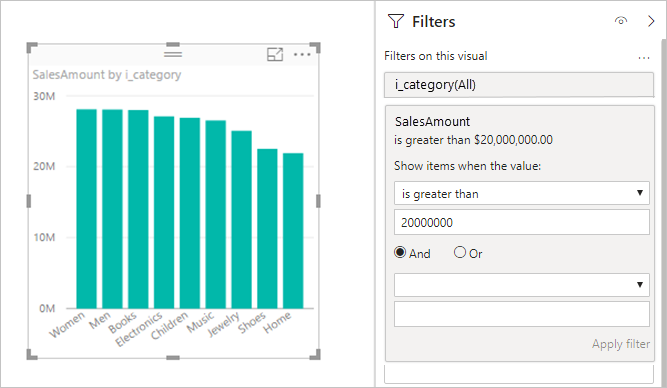
- Les filtres de mesure, les filtres TopN, les filtres avancés pour texte contenant/commençant, les segments à sélection multiple et les totaux/sous-totaux (en particulier avec
Median) peuvent ajouter des requêtes supplémentaires ou dégrader les performances. - Envisagez de simplifier la conception ou de désactiver certaines interactions.
Exemple (filtre de mesure) :
Recommandations de DirectQuery
Cette section fournit des recommandations pratiques pour la conception, l’optimisation et la résolution des problèmes des modèles DirectQuery dans Power BI. Suivez ces instructions pour améliorer les performances, la fiabilité et l’expérience utilisateur lors de l’utilisation des connexions DirectQuery.
Performances de la source de données sous-jacente
Validez les requêtes interactives de référence. S'ils sont lents, inspectez les requêtes à l'aide de Analyseur de performances et optimisez le schéma source (index, statistiques et columnstore, le cas échéant). Privilégiez les clés entières pour les jointures.
Conception de modèle
- Conservez les étapes de Power Query simples et réductibles. Aperçu « Afficher la requête native » fréquemment.
- Commencez par des mesures simples , puis effectuez une itération.
- Évitez les jointures sur les colonnes d’expression calculées , matérialisez dans la source si nécessaire.
-
Éviter les jointures sur
uniqueidentifieroù les casts interrompent l’utilisation de l’index ; matérialisez d’autres types de clés. - Masquer les clés de substitution/système ; créez des colonnes alias visibles si nécessaire.
- Passez en revue les tables/colonnes calculées qui peuvent produire des expressions non pliables.
- Limitez uniquement les filtres bidirectionnels aux cas requis. Testez l’impact sur les performances.
-
Considérez et assurez-vous de l’intégrité référentielle pour activer
INNER JOINl’utilisation. - Évitez d'utiliser les filtres de dates relatives dans Power Query. Implémentez plutôt une logique relative dans le modèle ou la couche de rapport.
Exemple de filtrage :
Capture d'écran d'une étape de filtrage sous Power Query pour les 14 derniers jours pour montrer comment la logique de date relative devient un littéral fixe.
La requête native résultante utilise une date littérale fixe :

Conception de rapports
Lorsque vous concevez des rapports qui utilisent DirectQuery, tenez compte des meilleures pratiques suivantes pour optimiser l’utilisation et les performances :
Utilisez les options de réduction des requêtes (utilisez le bouton Appliquer pour les trancheurs et les filtres, et désactivez la mise en surbrillance croisée lorsque la latence nuit à l’expérience).
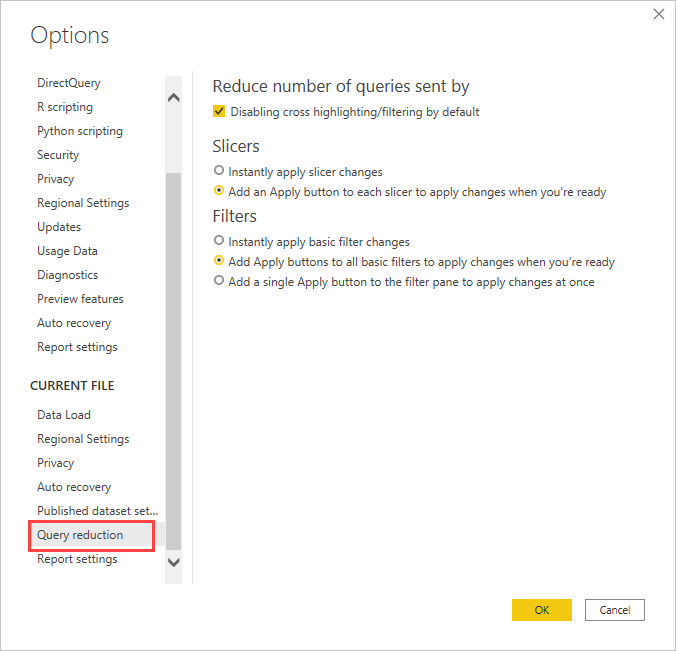
Appliquez les filtres clés tôt pour réduire le nombre de lignes intermédiaires et éviter d’atteindre les limites.
Limitez les visuels par page pour réduire les requêtes parallèles et sérialisées.
Désactivez les interactions inutiles (filtrage croisé ou mise en surbrillance) si elles déclenchent des requêtes sources coûteuses.

Nombre maximal de connexions
Ajustez dans > Options et paramètres de fichier > Options > DirectQuery la simultanéité de requêtes DirectQuery par fichier (valeur par défaut 10) pour le fichier en cours.
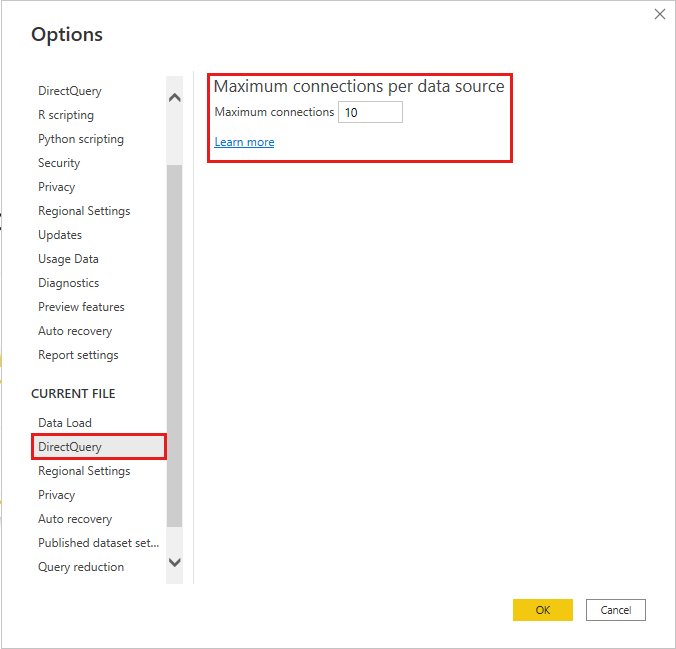
Des valeurs plus élevées peuvent améliorer le débit pour de nombreux visuels, mais elles peuvent également augmenter la charge source. Le comportement publié dépend également des limites de service ou de capacité.
| Environnement | Limite supérieure par source de données |
|---|---|
| Power BI Pro | 10 connexions actives |
| Power BI Premium | Dépend de la limitation du modèle sémantique pour l'unité de gestion des stocks (SKU) |
| Power BI Report Server | 10 connexions actives |
Note
Le paramètre maximal de connexions DirectQuery s’applique à toutes les sources DirectQuery lorsque les métadonnées améliorées sont activées (par défaut pour les nouveaux modèles).
Fonctionnalités d’atténuation des performances
Utilisez ces fonctionnalités pour améliorer les performances de DirectQuery :
- Agrégations automatiques et tables d’agrégation manuelle : Mettre en cache les données récapitulées pour réduire les requêtes sources.
- Tables hybrides : Conservez les données récentes via DirectQuery, historique via l’importation.
- Conception de mesure prenant en charge l’agrégation : Vérifiez que DAX est évalué au niveau de la couche d’agrégation lorsque cela est possible.
- Paramètres M dynamiques : Poussez dès le début les sélections utilisateur dans les prédicats sources.
- Mise en cache des requêtes et des résultats (paramètres de capacité) : Réutilisez les jeux de résultats récents pour les visuels répétés.
- Mode de stockage double pour les tables de dimension partagée : Réduisez les analyses de dimension distante répétées.
DirectQuery dans le service Power BI
Toutes les sources de données DirectQuery sont prises en charge via Power BI Desktop. Seul un sous-ensemble limité démarre directement à partir de l’interface utilisateur du service. Commencez dans Power BI Desktop pour un contrôle de modélisation et de transformation plus riche. Pour obtenir la liste actuelle des sources disponibles directement dans le service, consultez Power BI sources de données.
Les performances dans le service dépendent des éléments suivants :
- Nombre d’utilisateurs simultanés
- Complexité visuelle et nombre par page
- Présence d’une sécurité au niveau des lignes (peut réduire la réutilisation du cache)
- Horaires de rafraîchissement des tuiles
Comportement de rapport dans le service Power BI
L’ouverture d’une page de rapport exécute des requêtes pour chaque visuel (parfois plusieurs par visuel). Les interactions (changements de segment, mise en surbrillance croisée, filtres) réexécutent les requêtes. Le service met en cache certains résultats. Les requêtes répétées exactes peuvent être renvoyées instantanément, sauf si les limites de sécurité diffèrent.
Nuances de capacité :
- Insights rapides : Pas pris en charge pour les modèles sémantiques DirectQuery.
- Explore dans Excel / Analyser dans Excel : Pris en charge, mais peut sembler plus lent. Envisagez le mode d’importation ou les agrégations pour une utilisation intensive Excel.
- Hierarchies dans Excel : Certaines hiérarchies de modèles sémantiques DirectQuery n'apparaissent pas dans Excel.
Actualisation du tableau de bord
Les vignettes DirectQuery sont actualisées selon une planification. La valeur par défaut est horaire et vous pouvez la définir de toutes les 15 minutes jusqu’à toutes les semaines. Avec la sécurité au niveau des lignes, chaque utilisateur exécute des requêtes de tuiles distinctes. Un nombre élevé de vignettes multiplié par le nombre d’utilisateurs et la fréquence de rafraîchissement peut créer une charge importante ; planifier la capacité et prendre en compte les agrégations.
Délais d’expiration des requêtes
Le service applique un délai d’expiration de 4 minutes par requête. Les contenus visuels qui dépassent la limite échouent avec une erreur de délai d'expiration. Assurez-vous que les sources sous-jacentes fournissent des performances interactives avant de choisir DirectQuery.
Diagnostics des performances
Diagnostiquer les performances en premier dans Power BI Desktop.
Utilisez l’analyseur de performances pour isoler les visuels lents. Concentrez-vous sur un visuel problématique à la fois.
Utiliser SQL Server Profiler pour afficher les requêtes
Power BI Desktop écrit des traces de session, y compris DirectQuery SQL pour certaines sources, dans le fichier FlightRecorderCurrent.trc dans le dossier AnalysisServicesWorkspaces de l'utilisateur.
Pour localiser la trace :
Dans Power BI Desktop, sélectionnez Fichier > Options et paramètres > Options > Diagnostics.
Sélectionnez Ouvrir le dossier de vidage de la mémoire sur incident/traces.
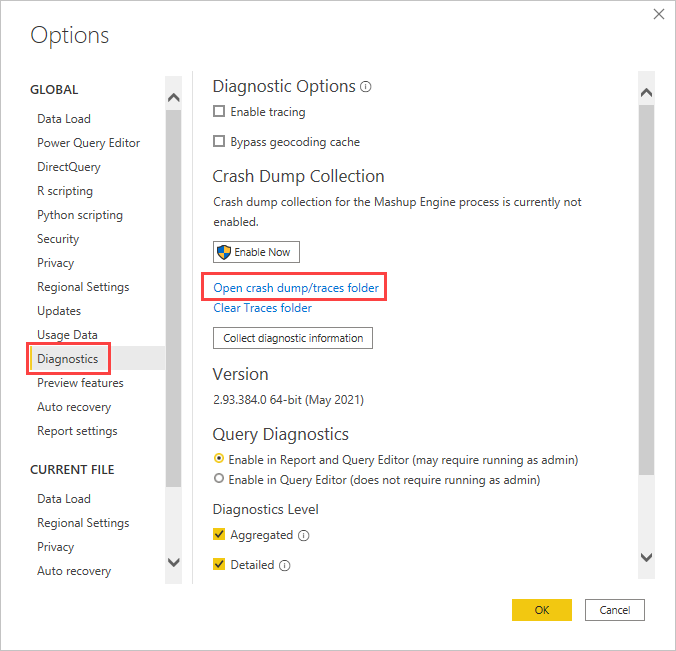
Accédez à un niveau à AnalysisServicesWorkspaces, ouvrez le dossier d’espace de travail actif, puis Data, puis recherchez FlightRecorderCurrent.trc.
Dans SQL Server Profiler, ouvrez le fichier : File > Ouvrir > Fichier de trace.
Profiler affiche des événements groupés.
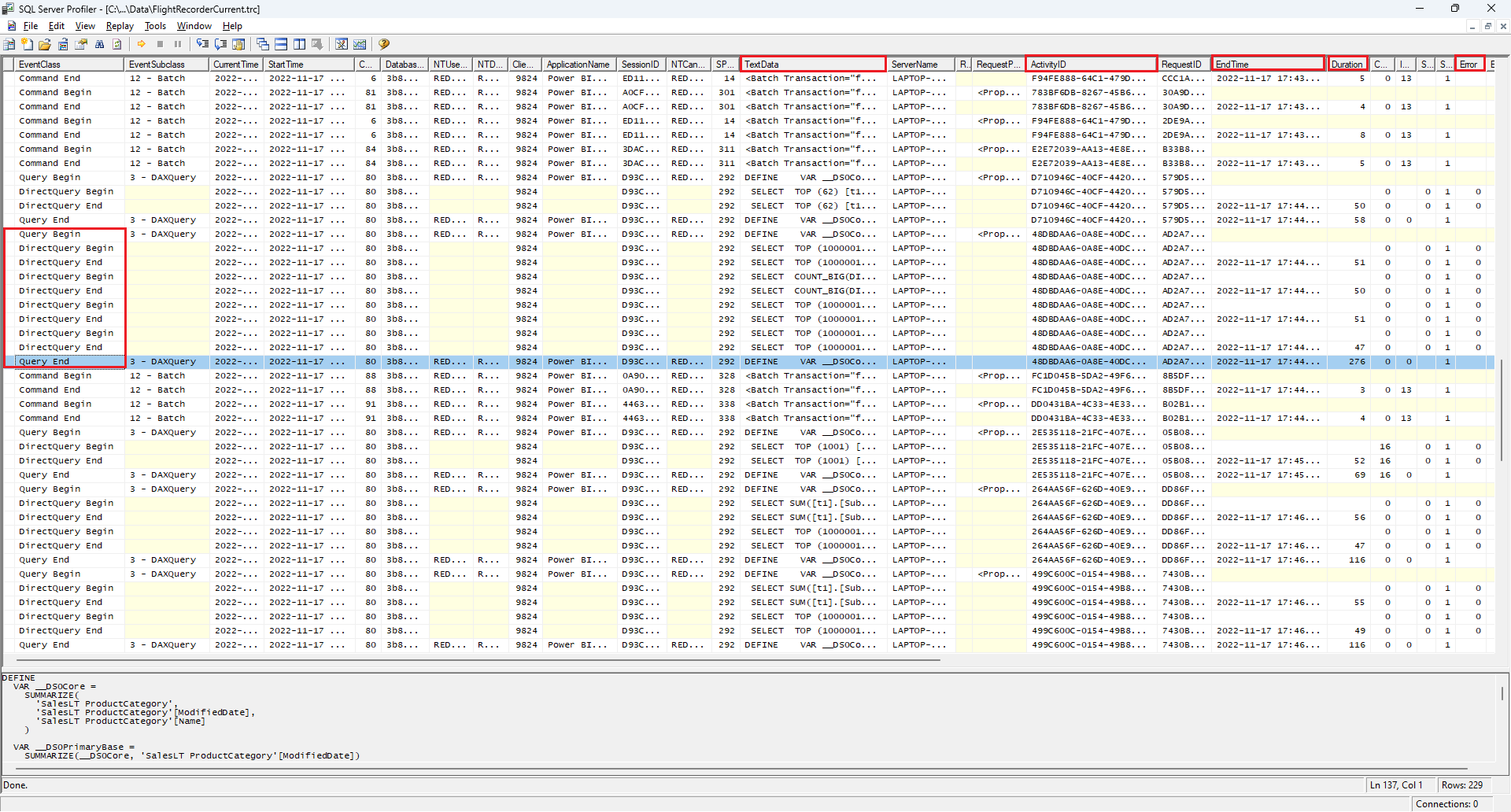
Colonnes d’événements :
- TextData : DAX (pour le début/la fin de la requête) ou SQL natif (pour DirectQuery Begin/End).
- Durée (ms) et EndTime aident à identifier les étapes lentes.
- ActivityID regroupe les événements associés.
Conseils de capture :
- Conservez les sessions courtes (≈10 secondes d’actions ciblées).
- Rouvrez le fichier de trace pour afficher les événements récemment enregistrés.
- Évitez plusieurs instances de bureau simultanées pour réduire la confusion.
Comprendre le format des requêtes
Power BI utilise souvent une sous-requête (table dérivée) pour chaque table logique référencée définie par les étapes de Power Query.
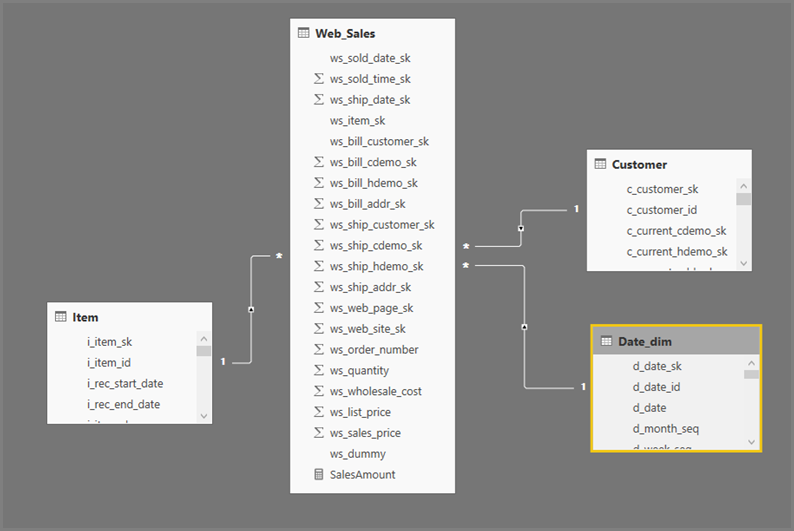
Exemple de logique de requête :
SalesAmount (SUMX(Web_Sales, [ws_sales_price]*[ws_quantity]))
by Item[i_category]
for Date_dim[d_year] = 2000
Visuel résultant :
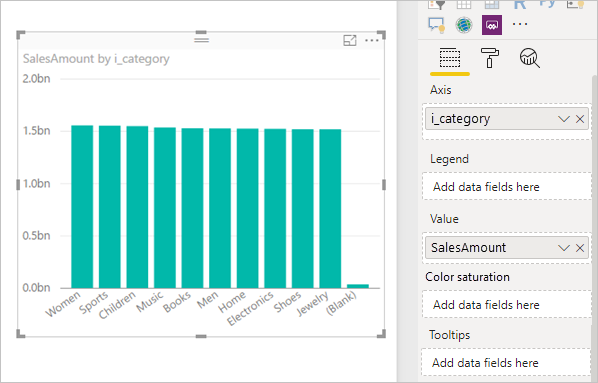
SQL généré avec des sous-sélections :
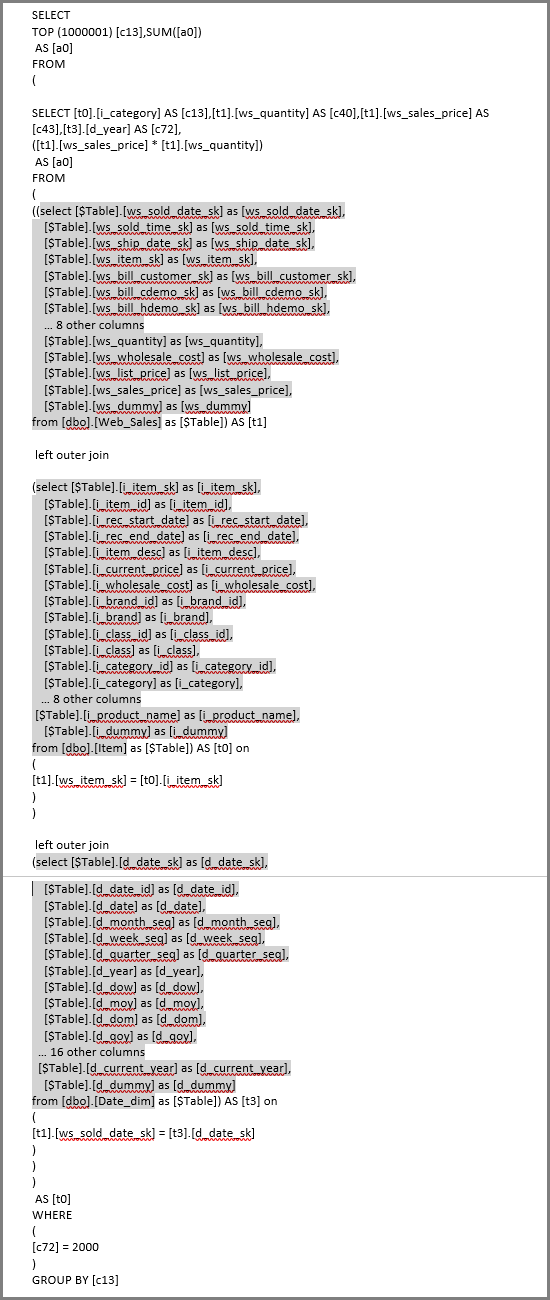
Les modèles de requête de sous-sélection ne nuisent généralement pas aux performances sur les moteurs pris en charge, car les optimiseurs éliminent les colonnes inutilisées. Hiérarchiser la pliabilité.
Note
Cet article fournit des conseils généraux sur DirectQuery dans Power BI. Validez toujours les performances et le comportement directQuery avec vos exigences spécifiques en matière de source de données, de schéma, d’index, de charge de travail et d’accès concurrentiel avant le déploiement en production.
Contenu connexe
- Use DirectQuery dans Power BI Desktop
- DirectQuery et SAP HANA
- DirectQuery et SAP BW
- Utilisez DirectQuery pour les modèles sémantiques de Power BI et Analysis Services
- Aggregations dans Power BI
- Analyseur de performances
- Modèles composites
- Vue d’ensemble de la sécurité au niveau des lignes
- Authentification unique (SSO)