Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article décrit le mappage des vues de données et comment les rôles de données sont utilisés pour créer différents types de visuels. Cela explique comment spécifier des exigences conditionnelles pour les rôles de données et les différents types de dataMappings.
Chaque mappage valide génère une vue de données. Vous pouvez fournir plusieurs mappages de données sous certaines conditions. Les options de mappage prises en charge sont les suivantes :
"dataViewMappings": [
{
"conditions": [ ... ],
"categorical": { ... },
"single": { ... },
"table": { ... },
"matrix": { ... }
}
]
Power BI crée un mappage à une vue de données seulement si le mappage valide est également défini dans dataViewMappings.
En d’autres termes categorical, peut être défini dans dataViewMappings, mais d’autres mappages, tels que table ou single, peuvent ne pas l’être. Dans ce cas, Power BI produit une vue de données avec un seul mappage categorical, tandis que table et les autres mappages restent non définis. Par exemple :
"dataViewMappings": [
{
"categorical": {
"categories": [ ... ],
"values": [ ... ]
},
"metadata": { ... }
}
]
Conditions
La section conditions établit des règles pour un mappage de données particulier. Si les données correspondent à un des ensembles de conditions décrits, le visuel accepte les données comme étant valides.
Pour chaque champ, vous pouvez spécifier une valeur minimale et une valeur maximale. La valeur représente le nombre de champs qui peuvent être liés à ce rôle de données.
Notes
Si un rôle de données est omis dans la condition, il peut contenir n’importe quel nombre de champs.
Dans l’exemple suivant, category à un seul champ de données et measure est limité à deux champs de données.
"conditions": [
{ "category": { "max": 1 }, "measure": { "max": 2 } },
]
Vous pouvez aussi définir plusieurs conditions pour un rôle de données. Dans ce cas, les données sont valides si une des conditions est remplie.
"conditions": [
{ "category": { "min": 1, "max": 1 }, "measure": { "min": 2, "max": 2 } },
{ "category": { "min": 2, "max": 2 }, "measure": { "min": 1, "max": 1 } }
]
Dans l’exemple précédent, l’une des deux conditions suivantes est requise :
- Exactement un champ de catégorie et exactement deux mesures
- Exactement deux catégories et exactement une mesure
Mappage de données unique
Le mappage de données unique est la forme la plus simple du mappage de données. Il accepte un champ de mesure et retourne le total. Si le champ est numérique, il retourne la somme. Sinon, il retourne le nombre de valeurs uniques.
Pour utiliser un mappage de données unique, définissez le nom du rôle de données que vous voulez mapper. Ce mappage ne fonctionne qu’avec un seul champ de mesure. Si un deuxième champ est affecté, aucune vue de données n’est générée. Il est donc recommandé d’inclure une condition qui limite les données à un seul champ.
Notes
Ce mappage de données ne peut pas être utilisé conjointement avec d’autres mappages de données. Il est destiné à réduire les données à une seule valeur numérique.
Par exemple :
{
"dataRoles": [
{
"displayName": "Y",
"name": "Y",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"conditions": [
{
"Y": {
"max": 1
}
}
],
"single": {
"role": "Y"
}
}
]
}
La vue de données résultante contient néanmoins toujours d’autres types de mappage tels que de table, ou de catégorie, mais chaque mappage ne contient que la valeur unique. La bonne pratique consiste à accéder à la valeur uniquement en mappage unique.
{
"dataView": [
{
"metadata": null,
"categorical": null,
"matrix": null,
"table": null,
"tree": null,
"single": {
"value": 94163140.3560001
}
}
]
}
L’exemple de code suivant traite le mappage de vues de données simple :
"use strict";
import powerbi from "powerbi-visuals-api";
import DataView = powerbi.DataView;
import DataViewSingle = powerbi.DataViewSingle;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private valueText: HTMLParagraphElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.valueText = document.createElement("p");
this.target.appendChild(this.valueText);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const singleDataView: DataViewSingle = dataView.single;
if (!singleDataView ||
!singleDataView.value ) {
return
}
this.valueText.innerText = singleDataView.value.toString();
}
}
L’exemple de code précédent produit l’affichage d’une valeur unique à partir de Power BI :
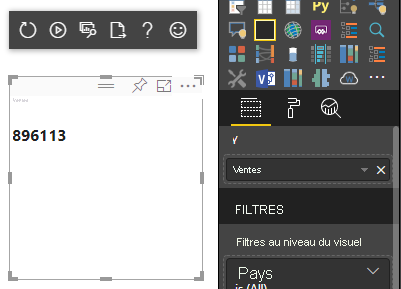
Mappage de données par catégorie
Un mappage de données de catégorie est utilisé pour obtenir des regroupements indépendants, ou des catégories de données. Les catégories peuvent aussi être regroupées en utilisant « Regrouper par » dans le mappage de données.
Mappage de données par catégorie de base
Considérez les rôles et les mappages de données suivants :
"dataRoles":[
{
"displayName": "Category",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Y Axis",
"name": "measure",
"kind": "Measure"
}
],
"dataViewMappings": {
"categorical": {
"categories": {
"for": { "in": "category" }
},
"values": {
"select": [
{ "bind": { "to": "measure" } }
]
}
}
}
L’exemple précédent affiche : « Mapper mon rôle de données category de façon à ce que pour chaque champ que je fais glisser dans category, ses données soient mappées à categorical.categories. Mapper également mon rôle de données measure à categorical.values. »
- for...in (pour ... dans) : inclue tous les éléments de ce rôle de données dans la requête de données.
- bind...to (lier ... à) : produit le même résultat que for...in (pour ... dans), mais s’attend à ce que le rôle de données ait une condition le limitant à un seul champ.
Regrouper des données de catégorie
L’exemple suivant utilise les deux mêmes rôles de données que l’exemple précédent, et ajoute deux rôles de données nommés grouping et measure2.
"dataRoles":[
{
"displayName": "Category",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Y Axis",
"name": "measure",
"kind": "Measure"
},
{
"displayName": "Grouping with",
"name": "grouping",
"kind": "Grouping"
},
{
"displayName": "X Axis",
"name": "measure2",
"kind": "Grouping"
}
],
"dataViewMappings": [
{
"categorical": {
"categories": {
"for": {
"in": "category"
}
},
"values": {
"group": {
"by": "grouping",
"select": [{
"bind": {
"to": "measure"
}
},
{
"bind": {
"to": "measure2"
}
}
]
}
}
}
}
]
La différence entre ce mappage et le mappage de base est la façon dont categorical.values est mappé. Lorsque vous mappez les rôles de données measure et measure2 au rôle de données grouping, les axes x et y peuvent être mis à l’échelle comme il faut.
Regrouper des données hiérarchiques
Dans l’exemple suivant, les données de catégories sont utilisées pour créer une hiérarchie, qui peut être utilisée pour prendre en charge des actions d’exploration.
L’exemple suivant montre les rôles et mappages de données :
"dataRoles": [
{
"displayName": "Categories",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Measures",
"name": "measure",
"kind": "Measure"
},
{
"displayName": "Series",
"name": "series",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"categorical": {
"categories": {
"for": {
"in": "category"
}
},
"values": {
"group": {
"by": "series",
"select": [{
"for": {
"in": "measure"
}
}
]
}
}
}
}
]
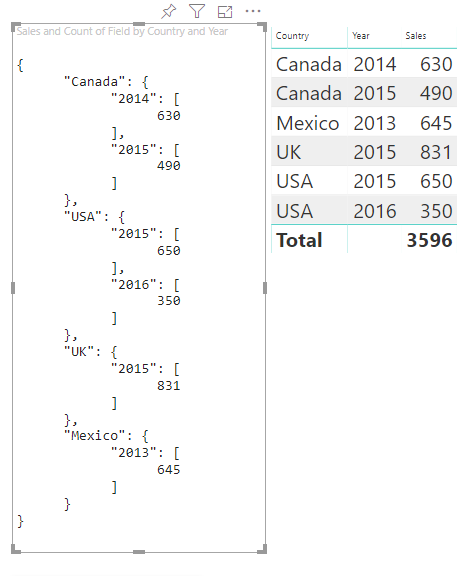
Considérons les données des catégories suivantes :
| Pays/Région | 2013 | 2014 | 2015 | 2016 |
|---|---|---|---|---|
| USA | x | x | 650 | 350 |
| Canada | x | 630 | 490 | x |
| Mexique | 645 | x | x | x |
| Royaume-Uni | x | x | 831 | x |
Power BI produit une vue de données de catégories avec l’ensemble de catégories suivant.
{
"categorical": {
"categories": [
{
"source": {...},
"values": [
"Canada",
"USA",
"UK",
"Mexico"
],
"identity": [...],
"identityFields": [...],
}
]
}
}
Chaque category est mappée à un ensemble de values. Chacune de ces values est regroupée par series, exprimées en années.
Par exemple, chaque tableau de values représente une année.
En outre, chaque tableau de values a quatre valeurs : Canada, USA (États-Unis), UK (Royaume-Uni) et Mexico (Mexique).
{
"values": [
// Values for year 2013
{
"source": {...},
"values": [
null, // Value for `Canada` category
null, // Value for `USA` category
null, // Value for `UK` category
645 // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2014
{
"source": {...},
"values": [
630, // Value for `Canada` category
null, // Value for `USA` category
null, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2015
{
"source": {...},
"values": [
490, // Value for `Canada` category
650, // Value for `USA` category
831, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2016
{
"source": {...},
"values": [
null, // Value for `Canada` category
350, // Value for `USA` category
null, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
}
]
}
L’exemple de code suivant est destiné au traitement du mappage de la vue de données de catégorie. Cet exemple crée la structure hiérarchique Pays/Région > Année > Valeur.
"use strict";
import powerbi from "powerbi-visuals-api";
import DataView = powerbi.DataView;
import DataViewCategorical = powerbi.DataViewCategorical;
import DataViewValueColumnGroup = powerbi.DataViewValueColumnGroup;
import PrimitiveValue = powerbi.PrimitiveValue;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private categories: HTMLElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.categories = document.createElement("pre");
this.target.appendChild(this.categories);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const categoricalDataView: DataViewCategorical = dataView.categorical;
if (!categoricalDataView ||
!categoricalDataView.categories ||
!categoricalDataView.categories[0] ||
!categoricalDataView.values) {
return;
}
// Categories have only one column in data buckets
// To support several columns of categories data bucket, iterate categoricalDataView.categories array.
const categoryFieldIndex = 0;
// Measure has only one column in data buckets.
// To support several columns on data bucket, iterate years.values array in map function
const measureFieldIndex = 0;
let categories: PrimitiveValue[] = categoricalDataView.categories[categoryFieldIndex].values;
let values: DataViewValueColumnGroup[] = categoricalDataView.values.grouped();
let data = {};
// iterate categories/countries-regions
categories.map((category: PrimitiveValue, categoryIndex: number) => {
data[category.toString()] = {};
// iterate series/years
values.map((years: DataViewValueColumnGroup) => {
if (!data[category.toString()][years.name] && years.values[measureFieldIndex].values[categoryIndex]) {
data[category.toString()][years.name] = []
}
if (years.values[0].values[categoryIndex]) {
data[category.toString()][years.name].push(years.values[measureFieldIndex].values[categoryIndex]);
}
});
});
this.categories.innerText = JSON.stringify(data, null, 6);
console.log(data);
}
}
Voici le visuel résultant :
Mappage des tables
La vue de données de tables est essentiellement une liste de points de données, où les points de données numériques peuvent être agrégés.
Par exemple, utilisez les mêmes données que dans la section précédente, mais avec les fonctionnalités suivantes :
"dataRoles": [
{
"displayName": "Column",
"name": "column",
"kind": "Grouping"
},
{
"displayName": "Value",
"name": "value",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"table": {
"rows": {
"select": [
{
"for": {
"in": "column"
}
},
{
"for": {
"in": "value"
}
}
]
}
}
}
]
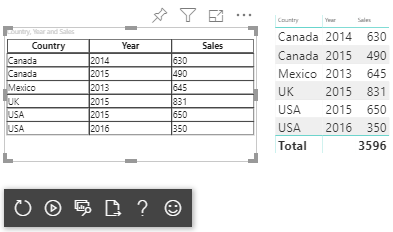
Visualisez la vue de données de tables comme dans cette exemple :
| Pays/Région | Year | Sales |
|---|---|---|
| USA | 2016 | 100 |
| USA | 2015 | 50 |
| Canada | 2015 | 200 |
| Canada | 2015 | 50 |
| Mexique | 2013 | 300 |
| Royaume-Uni | 2014 | 150 |
| USA | 2015 | 75 |
Liaison de données :
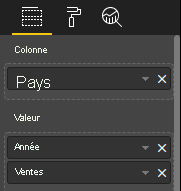
Power BI affiche vos données en tant que vue de données de table. Ne partez pas du principe que les données sont triées.
{
"table" : {
"columns": [...],
"rows": [
[
"Canada",
2014,
630
],
[
"Canada",
2015,
490
],
[
"Mexico",
2013,
645
],
[
"UK",
2014,
831
],
[
"USA",
2015,
650
],
[
"USA",
2016,
350
]
]
}
}
Pour agréger les données, sélectionnez le champ souhaité, puis sélectionnez Somme.
Exemple de code pour traiter un mappage de vues de données de tables.
"use strict";
import "./../style/visual.less";
import powerbi from "powerbi-visuals-api";
// ...
import DataViewMetadataColumn = powerbi.DataViewMetadataColumn;
import DataViewTable = powerbi.DataViewTable;
import DataViewTableRow = powerbi.DataViewTableRow;
import PrimitiveValue = powerbi.PrimitiveValue;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private table: HTMLParagraphElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.table = document.createElement("table");
this.target.appendChild(this.table);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const tableDataView: DataViewTable = dataView.table;
if (!tableDataView) {
return
}
while(this.table.firstChild) {
this.table.removeChild(this.table.firstChild);
}
//draw header
const tableHeader = document.createElement("th");
tableDataView.columns.forEach((column: DataViewMetadataColumn) => {
const tableHeaderColumn = document.createElement("td");
tableHeaderColumn.innerText = column.displayName
tableHeader.appendChild(tableHeaderColumn);
});
this.table.appendChild(tableHeader);
//draw rows
tableDataView.rows.forEach((row: DataViewTableRow) => {
const tableRow = document.createElement("tr");
row.forEach((columnValue: PrimitiveValue) => {
const cell = document.createElement("td");
cell.innerText = columnValue.toString();
tableRow.appendChild(cell);
})
this.table.appendChild(tableRow);
});
}
}
Le fichier de styles visuels style/visual.less contient la disposition du tableau :
table {
display: flex;
flex-direction: column;
}
tr, th {
display: flex;
flex: 1;
}
td {
flex: 1;
border: 1px solid black;
}
Le visuel résultant se présente comme ceci :
Mappage de données de matrice
Le mappage de données de matrice est similaire au mappage de données de table, mais les lignes sont présentées de façon hiérarchique. Toutes les valeurs de rôle de données peuvent être utilisées comme valeur d’en-tête de colonne.
{
"dataRoles": [
{
"name": "Category",
"displayName": "Category",
"displayNameKey": "Visual_Category",
"kind": "Grouping"
},
{
"name": "Column",
"displayName": "Column",
"displayNameKey": "Visual_Column",
"kind": "Grouping"
},
{
"name": "Measure",
"displayName": "Measure",
"displayNameKey": "Visual_Values",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"matrix": {
"rows": {
"for": {
"in": "Category"
}
},
"columns": {
"for": {
"in": "Column"
}
},
"values": {
"select": [
{
"for": {
"in": "Measure"
}
}
]
}
}
}
]
}
Structure hiérarchique des données de matrice
Power BI crée une structure de données hiérarchique. La racine de la hiérarchie d’arborescence contient les données de la colonne Parents du rôle de données Category, avec des enfants de la colonne Enfants de la table de rôles de données.
Modèle sémantique :
| Parents | Children | Petits-enfants | Colonnes | Valeurs |
|---|---|---|---|---|
| Parent 1 | Enfant 1 | Petit-enfant 1 | Col1 | 5 |
| Parent 1 | Enfant 1 | Petit-enfant 1 | Col2 | 6 |
| Parent 1 | Enfant 1 | Petit-enfant 2 | Col1 | 7 |
| Parent 1 | Enfant 1 | Petit-enfant 2 | Col2 | 8 |
| Parent 1 | Enfant 2 | Petit-enfant 3 | Col1 | 5 |
| Parent 1 | Enfant 2 | Petit-enfant 3 | Col2 | 3 |
| Parent 1 | Enfant 2 | Petit-enfant 4 | Col1 | 4 |
| Parent 1 | Enfant 2 | Petit-enfant 4 | Col2 | 9 |
| Parent 1 | Enfant 2 | Petit-enfant 5 | Col1 | 3 |
| Parent 1 | Enfant 2 | Petit-enfant 5 | Col2 | 5 |
| Parent 2 | Enfant 3 | Petit-enfant 6 | Col1 | 1 |
| Parent 2 | Enfant 3 | Petit-enfant 6 | Col2 | 2 |
| Parent 2 | Enfant 3 | Petit-enfant 7 | Col1 | 7 |
| Parent 2 | Enfant 3 | Petit-enfant 7 | Col2 | 1 |
| Parent 2 | Enfant 3 | Petit-enfant 8 | Col1 | 10 |
| Parent 2 | Enfant 3 | Petit-enfant 8 | Col2 | 13 |
Le visuel de matrice principale de Power BI affiche les données sous forme de table.
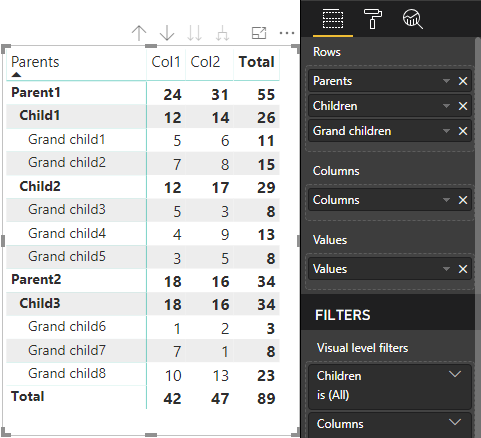
Le visuel obtient sa structure de données comme décrit dans le code suivant (seules les deux premières lignes de la table sont présentées ici) :
{
"metadata": {...},
"matrix": {
"rows": {
"levels": [...],
"root": {
"childIdentityFields": [...],
"children": [
{
"level": 0,
"levelValues": [...],
"value": "Parent1",
"identity": {...},
"childIdentityFields": [...],
"children": [
{
"level": 1,
"levelValues": [...],
"value": "Child1",
"identity": {...},
"childIdentityFields": [...],
"children": [
{
"level": 2,
"levelValues": [...],
"value": "Grand child1",
"identity": {...},
"values": {
"0": {
"value": 5 // value for Col1
},
"1": {
"value": 6 // value for Col2
}
}
},
...
]
},
...
]
},
...
]
}
},
"columns": {
"levels": [...],
"root": {
"childIdentityFields": [...],
"children": [
{
"level": 0,
"levelValues": [...],
"value": "Col1",
"identity": {...}
},
{
"level": 0,
"levelValues": [...],
"value": "Col2",
"identity": {...}
},
...
]
}
},
"valueSources": [...]
}
}
Développer et réduire les en-têtes de ligne
Pour la version API 4.1.0 ou ultérieure, les données de matrice prennent en charge le développement et la réduction des en-têtes de ligne. À partir de l’API 4.2, vous pouvez développer/réduire l’intégralité du niveau par programmation. La fonctionnalité de développement et de réduction optimise l’extraction des données vers le dataView en permettant à l’utilisateur de développer ou de réduire une ligne sans récupérer toutes les données pour le niveau suivant. Elle extrait uniquement les données de la ligne sélectionnée. L’état de développement de l’en-tête de ligne reste cohérent dans tous les signets et même dans les rapports enregistrés. Il n’est pas propre à chaque visuel.
Vous pouvez ajouter des commandes de développement et de réduction au menu contextuel en fournissant le paramètre dataRoles à la méthode showContextMenu.
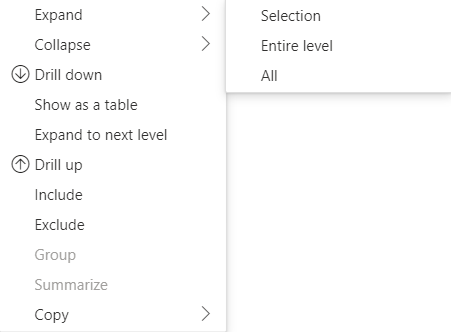
Pour développer un grand nombre de points de données, utilisez l’API d’extraction de données supplémentaires avec l’API de développement/réduction.
Fonctionnalités de l’API
Les éléments suivants ont été ajoutés à la version d’API 4.1.0 pour activer le développement et la réduction des en-têtes de ligne :
L’indicateur
isCollapseddansDataViewTreeNode:interface DataViewTreeNode { //... /** * TRUE if the node is Collapsed * FALSE if it is Expanded * Undefined if it cannot be Expanded (e.g. subtotal) */ isCollapsed?: boolean; }La méthode
toggleExpandCollapsedans l’interfaceISelectionManger:interface ISelectionManager { //... showContextMenu(selectionId: ISelectionId, position: IPoint, dataRoles?: string): IPromise<{}>; // dataRoles is the name of the role of the selected data point toggleExpandCollapse(selectionId: ISelectionId, entireLevel?: boolean): IPromise<{}>; // Expand/Collapse an entire level will be available from API 4.2.0 //... }L’indicateur
canBeExpandeddans DataViewHierarchyLevel :interface DataViewHierarchyLevel { //... /** If TRUE, this level can be expanded/collapsed */ canBeExpanded?: boolean; }
Exigences pour les visuels
Pour activer la fonctionnalité de développement et de réduction dans un visuel à l’aide de la vue de données de matrice :
Ajoutez le code suivant dans le fichier capabilities.json :
"expandCollapse": { "roles": ["Rows"], //”Rows” is the name of rows data role "addDataViewFlags": { "defaultValue": true //indicates if the DataViewTreeNode will get the isCollapsed flag by default } },Vérifiez que les rôles sont détectables :
"drilldown": { "roles": ["Rows"] },Pour chaque nœud, créez une instance du générateur de sélection en appelant la méthode
withMatrixNodedans le niveau de hiérarchie du nœud sélectionné et en créant unselectionId. Par exemple :let nodeSelectionBuilder: ISelectionIdBuilder = visualHost.createSelectionIdBuilder(); // parantNodes is a list of the parents of the selected node. // node is the current node which the selectionId is created for. parentNodes.push(node); for (let i = 0; i < parentNodes.length; i++) { nodeSelectionBuilder = nodeSelectionBuilder.withMatrixNode(parentNodes[i], levels); } const nodeSelectionId: ISelectionId = nodeSelectionBuilder.createSelectionId();Créez une instance du gestionnaire de sélection et utilisez la méthode
selectionManager.toggleExpandCollapse()avec le paramètre duselectionIdque vous avez créé pour le nœud sélectionné. Par exemple :// handle click events to apply expand\collapse action for the selected node button.addEventListener("click", () => { this.selectionManager.toggleExpandCollapse(nodeSelectionId); });
Notes
- Si le nœud sélectionné n’est pas un nœud de ligne, PowerBI ignore les appels de développement et de réduction et les commandes de développement et de réduction seront supprimées du menu contextuel.
- Le paramètre
dataRolesest obligatoire pour la méthodeshowContextMenuuniquement si le visuel prend en charge les fonctionnalitésdrilldownouexpandCollapse. Si le visuel prend en charge ces fonctionnalités alors que dataRoles n’est fourni, une erreur est générée dans la console lors de l’utilisation du visuel du développeur ou si le débogage d’un visuel public est activé avec le mode débogage.
Observations et limitations
- Après avoir développé un nœud, de nouvelles limites de données sont appliquées au DataView. Le nouveau DataView risque de ne pas inclure certains des nœuds présentés dans le DataView précédent.
- Quand vous utilisez développer et réduire, des totaux sont ajoutés même si le visuel ne les a pas demandés.
- Le développement et la réduction des colonnes ne sont pas pris en charge.
Conserver toutes les colonnes de métadonnées
Pour la version API 5.1.0 ou ultérieure, la conservation de toutes les colonnes de métadonnées est prise en charge. Cette fonctionnalité permet au visuel de recevoir les métadonnées de toutes les colonnes, quelles que soient leurs projections actives.
Ajoutez les lignes suivantes dans votre fichier capabilities.json :
"keepAllMetadataColumns": {
"type": "boolean",
"description": "Indicates that visual is going to receive all metadata columns, no matter what the active projections are"
}
La définition de cette propriété sur true entraîne la réception de toutes les métadonnées, y compris des colonnes réduites. Le fait de la définir sur false ou de la laisser non définie entraîne la réception de métadonnées uniquement sur les colonnes avec des projections actives (développées, par exemple).
Algorithme de réduction des données
L’algorithme de réduction de données contrôle les données et la quantité de données reçues dans la vue de données.
Le nombre est défini sur le nombre maximal de valeurs que la vue de données peut accepter. S’il y a plus de valeurs que count, l’algorithme de réduction des données détermine les valeurs qui doivent être reçues.
Types d’algorithmes de réduction des données
Il existe quatre types de paramètres d’algorithme de réduction des données :
top: Les premières valeurs de count sont extraites du modèle sémantique.bottom: Les dernières valeurs de count sont extraites du modèle sémantique.sample: le premier et le dernier éléments sont inclus, et un nombre count d’éléments avec des intervalles égaux entre eux. Par exemple, si vous avez un modèle sémantique [0, 1, 2, ... 100] et un count de 9, vous obtiendrez les valeurs [0, 10, 20 ... 100].window: charge une fenêtre de points de données à la fois contenant count éléments. Actuellement,topetwindowsont équivalents. À l’avenir, un paramètre de fenêtrage sera entièrement pris en charge.
Par défaut, tous les visuels Power BI ont l’algorithme de réduction des données appliqué avec la valeur count définie sur 1000 points de données. Ce paramètre par défaut équivaut à définir les propriétés suivantes dans le fichier capabilities.json :
"dataReductionAlgorithm": {
"top": {
"count": 1000
}
}
Vous pouvez affecter à count n’importe quelle valeur entière allant jusqu’à 30 000. Les visuels Power BI basés sur R peuvent prendre en charge jusqu’à 150000 lignes.
Utilisation d’un algorithme de réduction des données
Vous pouvez utiliser l’algorithme de réduction des données dans le mappage de vue de données de table, de matrice ou par catégorie.
Dans le mappage de données de catégorie, vous pouvez ajouter l’algorithme à la section « catégories » et/ou « groupe » de values pour le mappage de données de catégorie.
"dataViewMappings": {
"categorical": {
"categories": {
"for": { "in": "category" },
"dataReductionAlgorithm": {
"window": {
"count": 300
}
}
},
"values": {
"group": {
"by": "series",
"select": [{
"for": {
"in": "measure"
}
}
],
"dataReductionAlgorithm": {
"top": {
"count": 100
}
}
}
}
}
}
Dans le mappage de vue de données de tables, appliquez l’algorithme de réduction des données à la section rows de la table des mappages de la vue de données.
"dataViewMappings": [
{
"table": {
"rows": {
"for": {
"in": "values"
},
"dataReductionAlgorithm": {
"top": {
"count": 2000
}
}
}
}
}
]
Vous pouvez appliquer l’algorithme de réduction des données aux sections rows et columns de la matrice de mappage des vues de données.