Résoudre les problèmes de connectivité des points de terminaison XMLA
Dans Power BI, les points de terminaison XMLA s’appuient sur le protocole de communication Analysis Services natif pour accéder aux modèles sémantiques Power BI. De ce fait, la résolution des problèmes de point de terminaison XMLA est pratiquement identique à celle d’une connexion Analysis Services classique. Il existe toutefois certaines différences concernant les dépendances propres à Power BI.
Avant de commencer
Avant de résoudre les problèmes d’un scénario de point de terminaison XMLA, veillez à consulter les principes de base traités dans Connectivité des modèles sémantiques avec le point de terminaison XMLA. Les cas d’utilisation de points de terminaison XMLA les plus courants sont couverts ici. D’autres guides de dépannage Power BI, notamment Résolution des problèmes liés aux passerelles – Power BI et Résolution des problèmes de la fonctionnalité Analyser dans Excel, peuvent également être utiles.
Activation du point de terminaison XMLA
Le point de terminaison XMLA peut être activé à la fois sur la capacité Power BI Premium, Premium par utilisateur et sur la capacité Power BI Embedded. Sur les capacités plus petites, comme une capacité A1 comportant seulement 2,5 Go de mémoire, il se peut que vous rencontriez une erreur dans Paramètres de capacité lorsque vous tentez de définir le point de terminaison XMLA sur Lecture/écriture, puis que vous sélectionnez Appliquer. L’erreur indique : « Un problème s’est produit concernant les paramètres de votre charge de travail. Réessayez dans quelques instants. »
Vous pouvez essayer les opérations suivantes :
- Limitez la consommation de mémoire d’autres services sur la capacité, par exemple les dataflows, à 40 % ou moins, ou désactivez complètement les services inutiles.
- Mettez à niveau la capacité en passant à une référence SKU supérieure. Par exemple, le passage d’une capacité A1 à une capacité A3 permet de résoudre ce problème de configuration sans avoir à désactiver de dataflows.
N’oubliez pas que vous devez aussi activer le paramètre Exporter des données au niveau du locataire sur le portail d’administration Power BI. Ce paramètre est également requis pour la fonctionnalité Analyser dans Excel.
Établissement d’une connexion cliente
Après avoir activé le point de terminaison XMLA, il est judicieux de tester la connectivité à un espace de travail sur la capacité. Pour plus d’informations, consultez Connexion à un espace de travail Premium. Veillez également à lire la section Exigences pour la connexion pour obtenir des conseils et des informations utiles sur les limitations actuelles de la connectivité XMLA.
Connexion avec un principal de service
Si vous avez activé les paramètres du locataire permettant aux principaux de service d’utiliser les API Power BI (cf. Activation des principaux de service), vous pouvez vous connecter à un point de terminaison XMLA à l’aide d’un principal de service. N’oubliez pas que le principal de service a besoin du même niveau d’autorisations d’accès au niveau de l’espace de travail ou du modèle sémantique que les utilisateurs standard.
Pour utiliser un principal de service, veillez à spécifier les informations d’identité de l’application dans la chaîne de connexion ainsi :
User ID=<app:appid@tenantid>Password=<application secret>
Par exemple :
Data Source=powerbi://api.powerbi.com/v1.0/myorg/Contoso;Initial Catalog=PowerBI_Dataset;User ID=app:91ab91bb-6b32-4f6d-8bbc-97a0f9f8906b@19373176-316e-4dc7-834c-328902628ad4;Password=6drX...;
Si vous recevez l’erreur suivante :
« Connexion au modèle sémantique impossible en raison d’informations de compte incomplètes. Pour les principaux de service, veillez à spécifier l’ID de locataire avec l’ID d’application en utilisant le format app:<appID>@<tenantId>, puis réessayez. »
Veillez à spécifier l’ID de locataire avec l’ID d’application au bon format.
Il est également possible d’indiquer l’ID d’application sans l’ID de locataire. Toutefois, vous devez dans ce cas remplacer l’alias myorg dans l’URL de la source de données par l’ID de locataire réel. Power BI peut alors localiser le principal de service dans le locataire approprié. Il est cependant recommandé d’utiliser l’alias myorg et de spécifier l’ID de locataire avec l’ID d’application dans le paramètre ID d’utilisateur.
Connexion avec Microsoft Entra B2B
Avec la prise en charge de Microsoft Entra interentreprises (B2B) dans Power BI, vous pouvez fournir aux utilisateurs invités externes un accès aux modèles sémantiques via le point de terminaison XMLA. Vérifiez que le paramètre Partage de contenu avec des utilisateurs externes est activé sur le portail d’administration Power BI. Pour plus d’informations, consultez Distribution de contenu Power BI à des utilisateurs invités externes avec Microsoft Entra B2B.
Déployer un modèle sémantique
Vous pouvez déployer un projet de modèle tabulaire dans Visual Studio (SSDT) dans un espace de travail attribué à une capacité Premium comme vous le feriez sur une ressource serveur dans sur Azure Analysis Services. Toutefois, lors du déploiement, des considérations supplémentaires sont à prendre en compte. Veillez à consulter la section Déployer des projets de modèle à partir de Visual Studio (SSDT) dans l’article Connectivité des modèles sémantiques avec le point de terminaison XMLA.
Déploiement d’un modèle
Dans la configuration par défaut, Visual Studio tente de traiter le modèle dans le cadre de l’opération de déploiement consistant à charger les données dans le modèle sémantique à partir des sources de données. Comme le décrit Déploiement de projets de modèle à partir de Visual Studio (SSDT), cette opération est susceptible d’échouer parce que les informations d’identification de la source de données ne peuvent pas être spécifiées dans le cadre de l’opération de déploiement. Si, au contraire, les informations d’identification de votre source de données ne sont définies pour aucun de vos modèles sémantiques existants, vous devez indiquer les informations d’identification de la source de données dans les paramètres du modèle sémantique à l’aide de l’interface utilisateur Power BI (Modèles sémantiques>Paramètres>Informations d’identification de la source de données>Modification des informations d’identification). Une fois les informations d’identification de la source de données définies, Power BI peut les appliquer automatiquement à cette source de données pour tout nouveau modèle sémantique, lorsque le déploiement des métadonnées a réussi et que le modèle sémantique a été créé.
Si Power BI ne parvient pas à lier votre nouveau modèle sémantique aux informations d’identification de la source de données, vous recevrez un message d’erreur indiquant « Impossible de traiter la base de données ». Raison : échec de l’enregistrement des modifications sur le serveur. » avec le code d’erreur « DMTS_DatasourceHasNoCredentialError », comme indiqué ci-dessous :
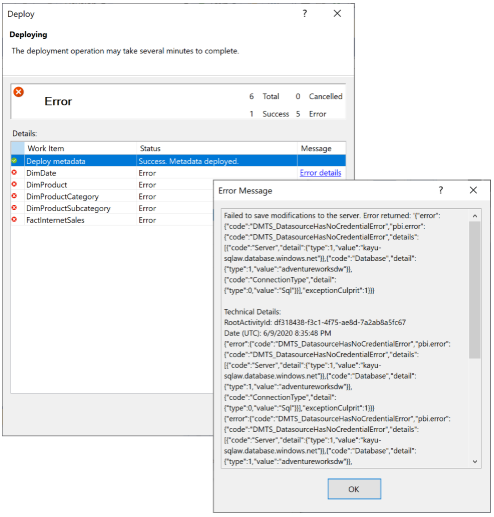
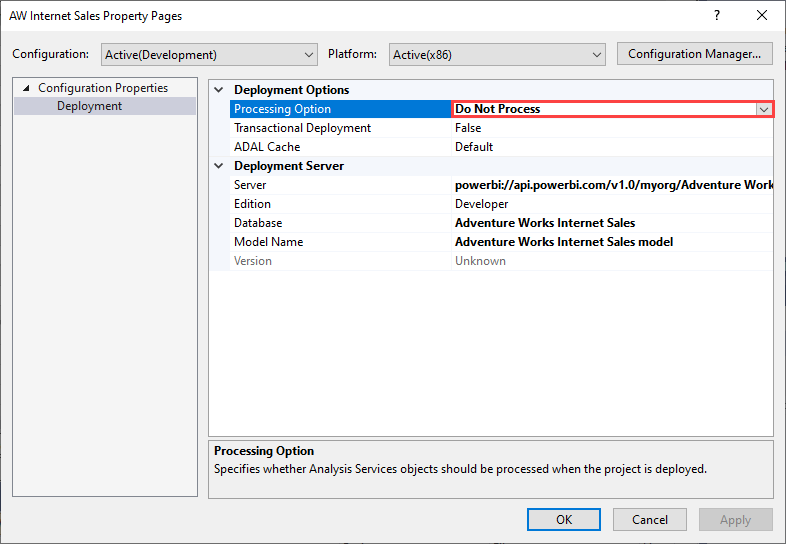
Pour éviter l’échec du traitement, définissez Options de déploiement>Options de traitement sur Ne pas traiter, comme l’illustre l’image suivante. Visual Studio déploie alors uniquement les métadonnées. Vous pouvez ensuite configurer les informations d’identification de la source de données, puis cliquer sur Actualiser maintenant pour le modèle sémantique dans l’interface utilisateur Power BI.
Nouveau projet issu d’un modèle sémantique existant
La création d’un projet tabulaire dans Visual Studio par l’importation des métadonnées à partir d’un modèle sémantique existant n’est pas prise en charge. Toutefois, vous pouvez vous connecter au modèle sémantique à l’aide de SQL Server Management Studio, exporter les métadonnées par script et les réutiliser dans d’autres projets tabulaires.
Migration d’un modèle sémantique vers Power BI
Il est recommandé de spécifier le niveau de compatibilité 1500 (au minimum) pour les modèles tabulaires. Ce niveau de compatibilité permet de gérer la plupart des fonctionnalités et des types de sources de données. Les niveaux de compatibilité ultérieurs présentent une compatibilité descendante avec les niveaux antérieurs.
Fournisseurs de données pris en charge
Au niveau de compatibilité 1500, Power BI prend en charge les types de sources de données suivants :
- Sources de données de fournisseur (héritées avec une chaîne de connexion dans les métadonnées du modèle).
- Sources de données structurées (introduites avec le niveau de compatibilité 1400).
- Déclarations Inline M de sources de données (à mesure que Power BI Desktop les déclare).
Il est recommandé d’utiliser des sources de données structurées, que Visual Studio crée par défaut dans le cadre du workflow Importer des données. Toutefois, si vous envisagez de migrer vers Power BI un modèle existant qui utilise une source de données de fournisseur, vérifiez que celle-ci s’appuie sur un fournisseur de données pris en charge, plus précisément, le pilote Microsoft OLE DB Driver pour SQL Server et les pilotes ODBC tiers. Dans le cas du pilote OLE DB Driver pour SQL Server, vous devez basculer la définition de la source de données vers le fournisseur de données .NET Framework pour SQL Server. En ce qui concerne les pilotes ODBC tiers qui risquent de ne pas être disponibles dans le service Power BI, vous devez basculer vers une définition de source de données structurées.
Il est également recommandé de remplacer le pilote Microsoft OLE DB Driver pour SQL Server (SQLNCLI11) par le fournisseur de données .NET Framework pour SQL Server dans les définitions de source de données SQL Server.
Le tableau suivant fournit un exemple de chaîne de connexion du fournisseur de données .NET Framework pour SQL Server remplaçant une chaîne de connexion correspondante pour le pilote OLE DB Driver pour SQL Server.
| OLE DB Driver pour SQL Server | Fournisseur de données .NET Framework pour SQL Server |
|---|---|
Provider=SQLNCLI11;Data Source=sqldb.database.windows.net;Initial Catalog=AdventureWorksDW;Trusted_Connection=yes; |
Data Source=sqldb.database.windows.net;Initial Catalog=AdventureWorksDW2016;Integrated Security=SSPI;Encrypt=true;TrustServerCertificate=false |
Référence croisée des sources de partition
Tout comme il existe plusieurs types de sources de données, il existe également plusieurs types de sources de partition qu’un modèle tabulaire peut inclure pour importer des données dans une table. Plus précisément, une partition peut utiliser une source de partition de requête ou une source de partition M, qui en retour peuvent faire référence à des sources de données de fournisseur ou à des sources de données structurées. Si dans Azure Analysis Services les modèles tabulaires prennent en charge les références croisées entre ces différents types de sources de données et de partitions, Power BI applique une relation plus stricte. Les sources de partition de requête doivent faire référence à des sources de données de fournisseur et les sources de partition M à des sources de données structurées. Les autres combinaisons ne sont pas acceptées dans Power BI. Si vous voulez faire migrer un modèle sémantique à référence croisée, le tableau suivant décrit les configurations prises en charge :
| Paramètres | Source de partition | Commentaires | Pris en charge avec le point de terminaison XMLA |
|---|---|---|---|
| Source de données de fournisseur | Source de partition de requête | Le moteur AS utilise la pile de connectivité basée sur cartouche pour accéder à la source de données. | Oui |
| Source de données de fournisseur | Source de partition M | Le moteur AS convertit la source de données de fournisseur en source de données structurées générique, puis utilise le Moteur Mashup pour importer les données. | Non |
| Source de données structurée | Source de partition de requête | Le moteur AS encapsule la requête native sur la source de la partition dans une expression M, puis utilise le Moteur Mashup pour importer les données. | Non |
| Source de données structurée | Source de partition M | Le moteur AS utilise le Moteur Mashup pour importer les données. | Oui |
Sources de données et emprunt d’identité
Les paramètres d’emprunt d’identité que vous pouvez définir pour les sources de données de fournisseur ne sont pas pertinents pour Power BI. Power BI utilise un mécanisme différent, qui s’appuie sur les paramètres du modèle sémantique pour gérer les informations d’identification de la source de données. Veillez donc à sélectionner Compte de service si vous créez une source de données de fournisseur.
Traitement affiné
Lorsqu’une actualisation planifiée ou à la demande est déclenchée dans Power BI, Power BI actualise généralement l’ensemble du modèle sémantique. Il existe de nombreux cas où il est plus efficace d’effectuer des actualisations plus sélectives. Vous pouvez effectuer des tâches de traitement affinées dans SQL Server Management Studio (SSMS) comme indiqué ci-dessous, ou à l’aide d’outils ou de scripts tiers.
Remplacements dans la commande Refresh TMSL
Les remplacements dans la commande Refresh (TMSL) permettent aux utilisateurs de choisir une définition de requête de partition ou une définition de source de données différente pour l’opération d’actualisation.
Abonnements par courrier
Les modèles sémantiques qui sont actualisés à l’aide d’un point de terminaison XMLA ne déclenchent pas d’abonnement par e-mail.
Erreurs sur la capacité Premium
Erreur de connexion au serveur dans SSMS
Lors de la connexion à un espace de travail Power BI avec SQL Server Management Studio (SSMS), l’erreur suivante peut s’afficher :
TITLE: Connect to Server
------------------------------
Cannot connect to powerbi://api.powerbi.com/v1.0/[tenant name]/[workspace name].
------------------------------
ADDITIONAL INFORMATION:
The remote server returned an error: (400) Bad Request.
Technical Details:
RootActivityId:
Date (UTC): 10/6/2021 1:03:25 AM (Microsoft.AnalysisServices.AdomdClient)
------------------------------
The remote server returned an error: (400) Bad Request. (System)
Quand vous vous connectez à un espace de travail Power BI avec SSMS, vérifiez les points suivants :
- Le paramètre de point de terminaison XMLA est activé pour la capacité de votre locataire. Pour en savoir plus, consultez Activer l’accès en lecture-écriture XMLA.
- Le paramètre Autoriser les points de terminaison XMLA et l’analyse dans Excel avec les modèles sémantiques locaux est activé dans les paramètres du locataire.
- Vous utilisez la dernière version de SSMS. Téléchargez la version la plus récente.
Exécution de la requête dans SSMS
En cas de connexion à un espace de travail dans une capacité Power BI Premium ou Power BI Embedded, SQL Server Management Studio peut afficher l’erreur suivante :
Executing the query ...
Error -1052311437: We had to move the session with ID '<Session ID>' to another Power BI Premium node. Moving the session temporarily interrupted this trace - tracing will resume automatically as soon as the session has been fully moved to the new node.
Ceci est un message d’information qui peut être ignoré dans SSMS 18.8 et ultérieur, car les bibliothèques de client vont se reconnecter automatiquement. Notez que les bibliothèques de client installées avec SSMS 18.7.1 ou antérieur ne prennent pas en charge le suivi de session. Téléchargez la dernière version de SSMS.
Exécution d’une commande volumineuse à l’aide du point de terminaison XMLA
Lors de l’exécution d’une commande volumineuse à l’aide du point de terminaison XMLA, vous pouvez rencontrer l’erreur suivante :
Executing the query ...
Error -1052311437:
The remote server returned an error: (400) Bad Request.
Technical Details:
RootActivityId: 3716c0f7-3d01-4595-8061-e6b2bd9f3428
Date (UTC): 11/13/2020 7:57:16 PM
Run complete
Si vous utilisez SSMS v18.7.1 ou antérieur pour effectuer une opération d’actualisation durable (>1 min) sur un modèle sémantique dans une capacité Power BI Premium ou Power BI Embedded, SSMS peut afficher cette erreur, même si l’opération d’actualisation réussit. Cela est dû à un problème connu dans les bibliothèques de client où l’état de la demande d’actualisation est incorrectement suivi. Cela est résolu dans SSMS 18.8 et versions ultérieures. Téléchargez la dernière version de SSMS.
Cette erreur peut également se produire lorsqu’une requête très volumineuse doit être redirigée vers un autre nœud dans le cluster Premium. Cela se produit souvent lorsque vous essayez de créer ou de modifier un modèle sémantique à l’aide d’un script TMSL volumineux. Dans ce cas, l’erreur peut généralement être évitée en spécifiant le catalogue initial sur le nom de la base de données avant d’exécuter la commande.
Lors de la création d’une nouvelle base de données, vous pouvez créer un modèle sémantique vide, par exemple :
{
"create": {
"database": {
"name": "DatabaseName"
}
}
}
Après avoir créé le nouveau modèle sémantique, spécifiez le catalogue initial, puis apportez des modifications au modèle sémantique.
Autres applications et outils clients
Les applications et outils clients tels qu’Excel, Power BI Desktop, SSMS ou les outils externes qui se connectent aux modèles sémantiques et les utilisent dans les capacités Power BI Premium peuvent provoquer l’erreur suivante : Le serveur distant a rapporté une erreur : (400) Requête incorrecte.. L’erreur peut se produire en particulier si une requête DAX sous-jacente ou une commande XMLA est durable. Pour atténuer les erreurs potentielles, veillez à utiliser les applications et les outils les plus récents qui installent les versions récentes des bibliothèques clientes Analysis Services avec des mises à jour régulières. Indépendamment de l’application ou de l’outil, les versions minimales de la bibliothèque de client requises pour se connecter et utiliser des modèles sémantiques dans une capacité Premium via le point de terminaison XMLA sont les suivantes :
| Bibliothèque de client | Version |
|---|---|
| MSOLAP | 15.1.65.22 |
| AMO | 19.12.7.0 |
| ADOMD | 19.12.7.0 |
Modification des appartenances à des rôles dans SSMS
Lorsque vous utilisez SQL Server Management Studio (SSMS) v18.8 pour modifier l’appartenance à un rôle sur un modèle sémantique, SSMS peut afficher l’erreur suivante :
Failed to save modifications to the server.
Error returned: ‘Metadata change of current operation cannot be resolved, please check the command or try again later.’
Cela est dû à un problème connu dans l’API REST App Services. Ce problème sera résolu dans une prochaine version. En attendant, pour contourner cette erreur, dans Propriétés du rôle, cliquez sur Script, puis entrez et exécutez la commande TMSL suivante :
{
"createOrReplace": {
"object": {
"database": "AdventureWorks",
"role": "Role"
},
"role": {
"name": "Role",
"modelPermission": "read",
"members": [
{
"memberName": "xxxx",
"identityProvider": "AzureAD"
},
{
"memberName": “xxxx”
"identityProvider": "AzureAD"
}
]
}
}
}
Erreur de publication : Modèle sémantique connecté en direct
Lors de la republication d’un modèle sémantique connecté en direct à l’aide du connecteur Analysis Services, l’erreur suivante «Il existe un rapport/modèle sémantique portant le même nom. Veuillez supprimer ou renommer le modèle sémantique existant et réessayez.» peut s’afficher.
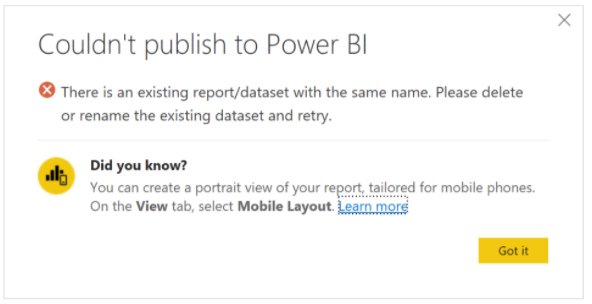
Cela est dû au fait que le modèle sémantique publié comporte une chaîne de connexion différente, mais porte le même nom que le modèle sémantique existant. Pour résoudre ce problème, supprimez ou renommez le modèle sémantique existant. De même, veillez à republier toutes les applications qui dépendent du rapport. Si nécessaire, les utilisateurs en aval doivent être informés de la mise à jour des signets éventuels avec la nouvelle adresse du rapport de telle sorte qu’ils accèdent au rapport le plus récent.
Alias d’espace de travail/de serveur
Contrairement à Azure Analysis Services, les alias de nom de serveur ne sont pas pris en charge pour les espaces de travail Premium.
DISCOVER_M_EXPRESSIONS
La vue de gestion de données (DMV) DISCOVER_M_EXPRESSIONS n’est actuellement pas pris en charge dans Power BI à l’aide du point de terminaison XMLA. Les applications peuvent utiliser le modèle d’objet tabulaire (TOM) pour obtenir les expressions M utilisées par le modèle de données.
Gestion des ressources : Limite de mémoire des commandes dans Premium
Les capacités Premium utilisent la gestion des ressources pour garantir qu’aucune opération de modèle sémantique ne dépasse la quantité de ressources mémoire disponibles pour la capacité (déterminée par la référence SKU). Par exemple,la limite de mémoire effective par élément est de 25 Go pour un abonnement P1, de 50 Go pour un abonnement P2 et de 100 Go pour un abonnement P3. En plus de la taille du modèle sémantique (base de données), la limite de mémoire effective s’applique aux opérations de commande de modèle sémantique sous-jacente, comme Créer, Modifier et Actualiser.
La limite de mémoire effective pour une commande est basée sur la valeur la plus petite entre la limite de mémoire de la capacité (déterminée par la référence SKU) et la valeur de la propriété XMLA DbpropMsmdRequestMemoryLimit.
Par exemple, pour une capacité P1, si :
DbpropMsmdRequestMemoryLimit = 0 (ou valeur non spécifiée), la limite de mémoire effective pour la commande est de 25 Go.
DbpropMsmdRequestMemoryLimit = 5 Go, la limite de mémoire effective pour la commande est de 5 Go.
DbpropMsmdRequestMemoryLimit = 50 Go, la limite de mémoire effective pour la commande est de 25 Go.
En général, la limite de mémoire effective pour une commande est calculée sur la base de la mémoire autorisée pour le modèle sémantique par la capacité (25 Go, 50 Go, 100 Go) et de la quantité de mémoire déjà consommée par le modèle sémantique au début de l’exécution de la commande. Par exemple, un modèle sémantique qui utilise 12 Go sur une capacité P1 autorise une limite de mémoire effective pour une nouvelle commande de 13 Go. Toutefois, la limite de mémoire effective peut être davantage limitée par la propriété XMLA DbPropMsmdRequestMemoryLimit quand elle est éventuellement spécifiée par une application. Dans l’exemple précédent, si 10 Go sont spécifiés dans la propriété DbPropMsmdRequestMemoryLimit, la limite effective de la commande est alors réduite à 10 Go.
Si l’opération de commande tente d’utiliser plus de mémoire que ce qui est autorisé par la limite, l’opération peut échouer et une erreur est retournée. Par exemple, l’erreur suivante indique qu’une limite de mémoire effective de 25 Go (capacité P1) a été dépassée, parce que le modèle sémantique a déjà consommé 12 Go (12288 Mo) au début de l’exécution de la commande et qu’une limite effective de 13 Go (13312 Mo) a été appliquée pour l’opération de commande :
« Gestion des ressources : Cette opération a été annulée, car il n’y avait pas assez de mémoire pour terminer son exécution. Augmentez la mémoire de la capacité Premium sur laquelle ce modèle sémantique est hébergé ou réduisez l’empreinte mémoire de votre modèle sémantique en limitant, par exemple, la quantité de données importées. Plus de détails : mémoire consommée 13 312 Mo, limite de mémoire 13 312 Mo, taille de la base de données avant exécution de la commande 12 288 Mo. Pour en savoir plus, consultez : https://go.microsoft.com/fwlink/?linkid=2159753. »
Dans certains cas, comme indiqué dans l’erreur suivante, la « mémoire consommée » est égale à 0, mais la quantité indiquée pour la « taille de la base de données avant exécution de la commande » est déjà supérieure à la limite de mémoire effective. Cela signifie que l’opération n’a pas pu commencer l’exécution, car la quantité de mémoire déjà utilisée par le modèle sémantique est supérieure à la limite de mémoire pour la référence SKU.
« Gestion des ressources : Cette opération a été annulée, car il n’y avait pas assez de mémoire pour terminer son exécution. Augmentez la mémoire de la capacité Premium sur laquelle ce modèle sémantique est hébergé ou réduisez l’empreinte mémoire de votre modèle sémantique en limitant, par exemple, la quantité de données importées. Plus de détails : mémoire consommée 0 Mo, limite de mémoire 25 600 Mo, taille de la base de données avant l’exécution de la commande 26 000 Mo. Pour en savoir plus, consultez : https://go.microsoft.com/fwlink/?linkid=2159753. »
Pour potentiellement éviter le dépassement de la limite de mémoire effective :
- Passez à une capacité Premium (SKU) plus grande pour le modèle sémantique.
- Réduisez l’empreinte mémoire de votre modèle sémantique en limitant la quantité de données chargées à chaque actualisation.
- Pour les opérations d’actualisation par le biais du point de terminaison XMLA, réduisez le nombre de partitions traitées en parallèle. Le traitement en parallèle d’un trop grand nombre de partitions avec une seule commande peut entraîner un dépassement de la limite de mémoire effective.