Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Les valeurs de cluster créent automatiquement des groupes avec des valeurs similaires à l’aide d’un algorithme de correspondance approximative, puis mappent la valeur de chaque colonne au groupe le plus adapté. Cette transformation est utile lorsque vous travaillez avec des données qui ont de nombreuses variantes différentes de la même valeur et que vous devez combiner des valeurs en groupes cohérents.
Considérez un exemple de tableau avec une colonne d’ID qui contient un ensemble d’ID et une colonne Person contenant un ensemble de versions orthographiques et majuscules des noms Miguel, Mike, William et Bill.
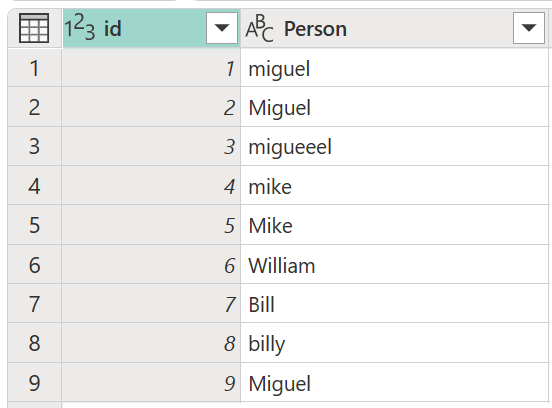
Dans cet exemple, le résultat que vous recherchez est une table avec une nouvelle colonne qui affiche les groupes de valeurs appropriés de la colonne Person et non toutes les variantes différentes des mêmes mots.
Note
La fonctionnalité valeurs du cluster est disponible uniquement pour Power Query Online.
Créer une colonne de cluster
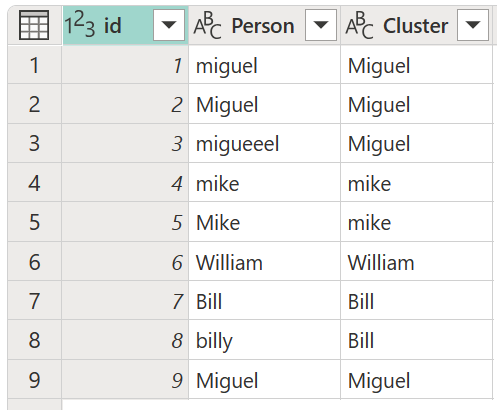
Pour les valeurs du cluster, sélectionnez d’abord la colonne Person , accédez à l’onglet Ajouter une colonne dans le ruban, puis sélectionnez l’option Valeurs du cluster .
![]()
Dans la boîte de dialogue Valeurs du cluster , confirmez la colonne à utiliser pour créer les clusters et entrez le nouveau nom de la colonne. Dans ce cas, nommez ce nouveau cluster de colonnes.
Le résultat de cette opération est illustré dans l’image suivante.
Note
Pour chaque cluster de valeurs, Power Query sélectionne l’instance la plus fréquente de la colonne sélectionnée comme instance « canonique ». Si plusieurs instances se produisent avec la même fréquence, Power Query sélectionne la première.
Utilisation des options de cluster flou
Les options suivantes sont disponibles pour le clustering de valeurs dans une nouvelle colonne :
- Seuil de similarité (facultatif) : cette option indique comment les deux valeurs similaires doivent être regroupées. Le paramètre minimal de zéro (0) entraîne le regroupement de toutes les valeurs. Le paramètre maximal de 1 autorise uniquement les valeurs qui correspondent exactement à être regroupées. La valeur par défaut est 0.8.
- Ignorer la casse : lorsque des chaînes de texte sont comparées, la casse est ignorée. Cette option est activée par défaut.
- Regrouper en combinant des parties de texte : l’algorithme tente de combiner des parties de texte (telles que la combinaison de micro et soft en Microsoft) pour regrouper les valeurs.
- Afficher les scores de similarité : affiche les scores de similarité entre les valeurs d’entrée et les valeurs représentatives calculées après le clustering flou.
- Table de transformation (facultatif) : vous pouvez sélectionner une table de transformation qui mappe des valeurs (par exemple, mapper MSFT à Microsoft) pour les regrouper.
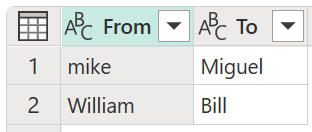
Pour cet exemple, une nouvelle table de transformation portant le nom Ma table de transformation est utilisée pour montrer comment les valeurs peuvent être mappées. Cette table de transformation comporte deux colonnes :
- De : chaîne de texte à rechercher dans votre tableau.
- À : chaîne de texte à utiliser pour remplacer la chaîne de texte dans la colonne From .
Important
Il est important que la table de transformation ait les mêmes colonnes et noms de colonnes que ceux indiqués dans l’image précédente (elles doivent être nommées « From » et « To »), sinon Power Query ne reconnaît pas cette table comme table de transformation et aucune transformation n’aura lieu.
À l’aide de la requête créée précédemment, double-cliquez sur l’étape valeurs groupées, puis, dans la boîte de dialogue Valeurs groupées, développez les options de cluster floues. Sous options de cluster flou, activez l’option Afficher les scores de similarité . Pour la table transformation (facultatif), sélectionnez la requête qui contient la table de transformation.
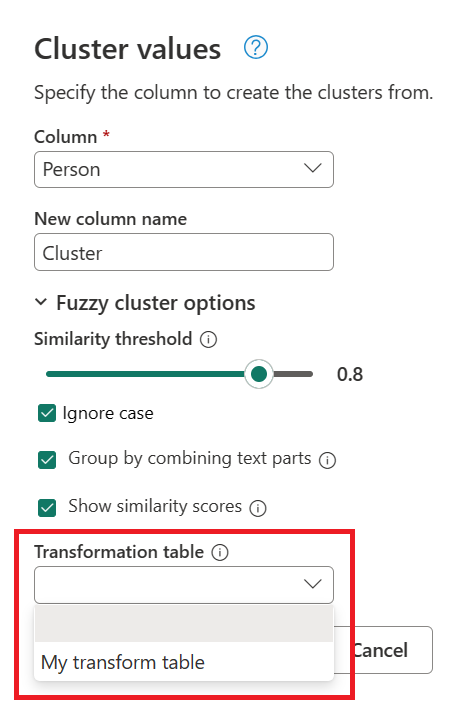
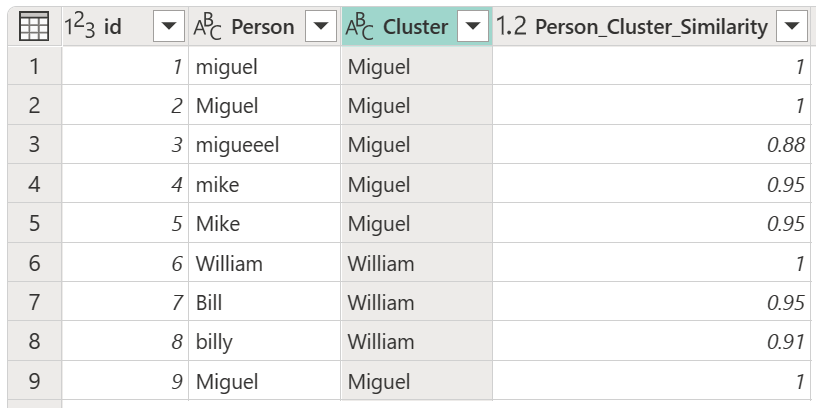
Après avoir sélectionné votre table de transformation et activé l’option Afficher les scores de similarité , sélectionnez OK. Le résultat de cette opération vous donne une table qui contient les mêmes colonnes ID et Personne que la table d’origine, mais inclut également deux nouvelles colonnes appelées Cluster et Person_Cluster_Similarity. La colonne Cluster contient les versions correctement orthographiques et majuscules des noms Miguel pour les versions de Miguel et Mike, et William pour les versions de Bill, Billy et William. La colonne Person_Cluster_Similarity contient les scores de similarité pour chacun des noms.
Precepts de table de transformation
Vous remarquerez peut-être que le tableau de transformation de la section précédente semblait indiquer que les instances de Mike sont modifiées en Miguel et que les instances de William sont remplacées par Bill. Toutefois, dans la table résultante, les instances de Bill et de « billy » ont été remplacées par William. Dans la table de transformation, au lieu d’être un chemin direct de From à To, la table de transformation est symétrique pendant le clustering, ce qui signifie que « mike » est équivalent à « Miguel » et vice versa. Le résultat des équivalents donnés dans la table de transformation dépend des règles suivantes :
- S’il existe une majorité de valeurs identiques, ces valeurs sont prioritaires sur les valeurs nonidentiques.
- S’il n’existe aucune majorité de valeurs, la valeur qui apparaît en premier est prioritaire.
Par exemple, dans le tableau d’origine utilisé dans cet article, les versions de Miguel (à la fois « miguel » et Miguel) dans la colonne Person constituent la majorité des instances du nom Miguel et Mike. En outre, le nom Miguel avec des majuscules initiales constitue la majorité du nom Miguel. Par conséquent, l’association de Miguel et de ses dérivés et Mike et ses dérivés dans la table de transformation entraîne l’utilisation du nom Miguel dans la colonne Cluster .
Toutefois, pour les noms William, Bill et « billy », il n’y a pas de majorité de valeurs, car les trois sont uniques. Étant donné que William apparaît en premier, William est utilisé dans la colonne Cluster . Si « billy » était apparu en premier dans la table, alors « billy » serait utilisé dans la colonne Cluster . En outre, étant donné qu’il n’existe aucune majorité de valeurs, le cas utilisé par les noms individuels est utilisé. Autrement dit, si William est en premier, William avec une majuscule « W » est utilisé comme valeur de résultat ; si « billy » est en premier, « billy » avec une minuscule « b » est utilisé.