Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Les fonctionnalités Power Query telles que la fusion approximative, les valeurs de cluster et le regroupement flou utilisent les mêmes mécanismes pour fonctionner comme correspondance approximative.
Cet article décrit de nombreux scénarios qui montrent comment tirer parti des options de correspondance approximative, avec l’objectif d’effacer « flou ».
Note
Bien que l’option valeurs de cluster soit disponible uniquement dans Power Query Online, les mécanismes présentés dans cette section s’appliquent également au regroupement flou et flou.
Ajuster le seuil de similarité
Le meilleur scénario d’application de l’algorithme de correspondance approximative est que toutes les chaînes de texte d’une colonne contiennent uniquement les chaînes qui doivent être comparées et aucun composant supplémentaire. Par exemple, la comparaison Apples par rapport 4ppl3s à des scores de similarité plus élevés que la comparaison Apples avec My favorite fruit, by far, is Apples. I simply love them!.
Étant donné que le mot Apples de la deuxième chaîne n’est qu’une petite partie de la chaîne de texte entière, cette comparaison génère un score de similarité inférieur.
Par exemple, le jeu de données suivant se compose de réponses d’une enquête qui n’avait qu’une seule question : « Quel est votre fruit préféré ? »
| Fruit |
|---|
| Bleuets |
| Les baies bleues sont simplement les meilleures |
| Fraises |
| Fraises = <3 |
| Apples |
| 'sples |
| 4ppl3s |
| Bananes |
| les fruits fav sont des bananes |
| Banas |
| Mon fruit préféré, de loin, est pommes. Je les aime tout simplement ! |
L’enquête a fourni une seule zone de texte pour entrer la valeur et n’avait aucune validation.
Vous êtes maintenant chargé de regrouper les valeurs. Pour effectuer cette tâche, chargez la table précédente des fruits dans Power Query, sélectionnez la colonne, puis sélectionnez l’option Valeurs du cluster dans l’onglet Ajouter une colonne dans le ruban.
![]()
La boîte de dialogue Valeurs du cluster s’affiche, où vous pouvez spécifier le nom de la nouvelle colonne. Nommez ce nouveau cluster de colonnes, puis sélectionnez OK.

Par défaut, Power Query utilise un seuil de similarité de 0,8 (ou 80%). La valeur minimale de 0,00 entraîne la correspondance de toutes les valeurs avec n’importe quel niveau de similarité, et la valeur maximale de 1,00 autorise uniquement les correspondances exactes. Une correspondance approximative peut ignorer les différences telles que la casse, l’ordre des mots et la ponctuation. Le résultat de l’opération précédente génère le tableau suivant avec une nouvelle colonne de cluster .
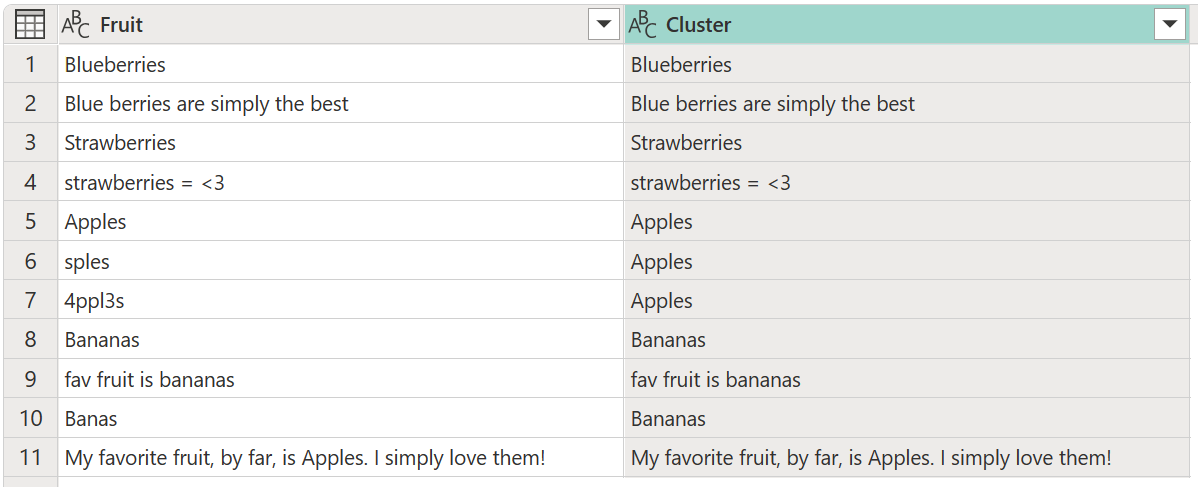
Pendant que le clustering est terminé, il ne vous donne pas les résultats attendus pour toutes les lignes. La ligne 2 (2) a toujours la valeur Blue berries are simply the best, mais elle doit être en cluster à Blueberries, et quelque chose de similaire arrive aux chaînes Strawberries = <3de texte , fav fruit is bananaset My favorite fruit, by far, is Apples. I simply love them!.
Pour déterminer ce qui provoque ce clustering, double-cliquez sur Valeurs en cluster dans le panneau Étapes appliquées pour ramener la boîte de dialogue Valeurs du cluster . Dans cette boîte de dialogue, développez les options de cluster approximatives. Activez l’option Afficher les scores de similarité , puis sélectionnez OK.

L’activation de l’option Afficher les scores de similarité crée une colonne dans votre table. Cette colonne indique le score de similarité exacte entre le cluster défini et la valeur d’origine.

Lors d’une inspection plus approfondie, Power Query n’a pas trouvé d’autres valeurs dans le seuil de similarité pour les chaînes Blue berries are simply the bestde texte ,Strawberries = <3fav fruit is bananas et My favorite fruit, by far, is Apples. I simply love them!.
Revenez à la boîte de dialogue Valeurs du cluster une fois de plus en double-cliquant sur Valeurs cluster dans le panneau Étapes appliquées . Modifiez le seuil de similarité de 0,8 à 0,6, puis sélectionnez OK.
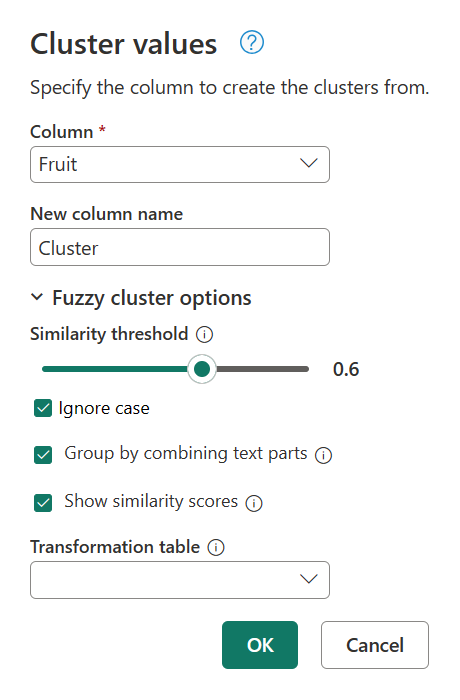
Cette modification vous rapproche du résultat que vous recherchez, à l’exception de la chaîne My favorite fruit, by far, is Apples. I simply love them!de texte . Lorsque vous avez modifié la valeur de seuil de similarité de 0,8 à 0,6, Power Query a maintenant pu utiliser les valeurs avec un score de similarité qui commence de 0,6 jusqu’à 1.

Note
Power Query utilise toujours la valeur la plus proche du seuil pour définir les clusters. Le seuil définit la limite inférieure du score de similarité acceptable pour affecter la valeur à un cluster.
Vous pouvez réessayer en modifiant le score Similarity de 0,6 à un nombre inférieur jusqu’à obtenir les résultats que vous recherchez. Dans ce cas, remplacez le score de similarité par 0,5. Cette modification génère le résultat exact que vous attendez avec la chaîne My favorite fruit, by far, is Apples. I simply love them! de texte maintenant affectée au cluster Apples.

Note
Actuellement, seule la fonctionnalité valeurs de cluster dans Power Query Online fournit une nouvelle colonne avec le score de similarité.
Considérations spéciales relatives à la table de transformation
La table de transformation vous permet de mapper des valeurs de votre colonne à de nouvelles valeurs avant d’effectuer l’algorithme de correspondance approximative.
Voici quelques exemples de la façon dont la table de transformation peut être utilisée :
- Table de transformation dans les valeurs du cluster
- Table de transformation dans les requêtes de fusion approximatives
- Table de transformation dans le groupe par
Important
Lorsque la table de transformation est utilisée, le score de similarité maximale pour les valeurs de la table de transformation est 0,95. Cette pénalité délibérée de 0,05 est en place pour distinguer que la valeur d’origine de cette colonne n’est pas égale aux valeurs auxquelles elle a été comparée depuis qu’une transformation s’est produite.
Pour les scénarios où vous souhaitez d’abord mapper vos valeurs, puis effectuer la correspondance approximative sans la pénalité 0,05, nous vous recommandons de remplacer les valeurs de votre colonne, puis d’effectuer la correspondance approximative.