Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cet article décrit une collection de bonnes pratiques pour réutiliser efficacement et efficacement les flux de données. Lisez cet article pour éviter les pièges de conception et les problèmes de performances potentiels lorsque vous développez des dataflows à des fins de réutilisation.
Séparer les dataflows de transformation de données des flux de données intermédiaires/d’extraction
Si un dataflow effectue toutes les actions, il est difficile de réutiliser ses tables dans d’autres dataflows ou à d’autres fins. Les meilleurs dataflows à réutiliser sont ces dataflows qui effectuent seulement quelques actions. La création de dataflows spécialisés dans une tâche spécifique est l’une des meilleures façons de les réutiliser. Si vous avez un ensemble de dataflows que vous utilisez comme dataflows intermédiaires, leur seule action consiste à extraire des données as-is du système source. Ces dataflows peuvent être réutilisés dans plusieurs autres dataflows.
Si vous avez des dataflows de transformation de données, vous pouvez les fractionner en dataflows qui effectuent des transformations courantes. Chaque dataflow peut effectuer quelques actions. Ces quelques actions par dataflow garantissent que la sortie de ce flux de données est réutilisable par d’autres dataflows.
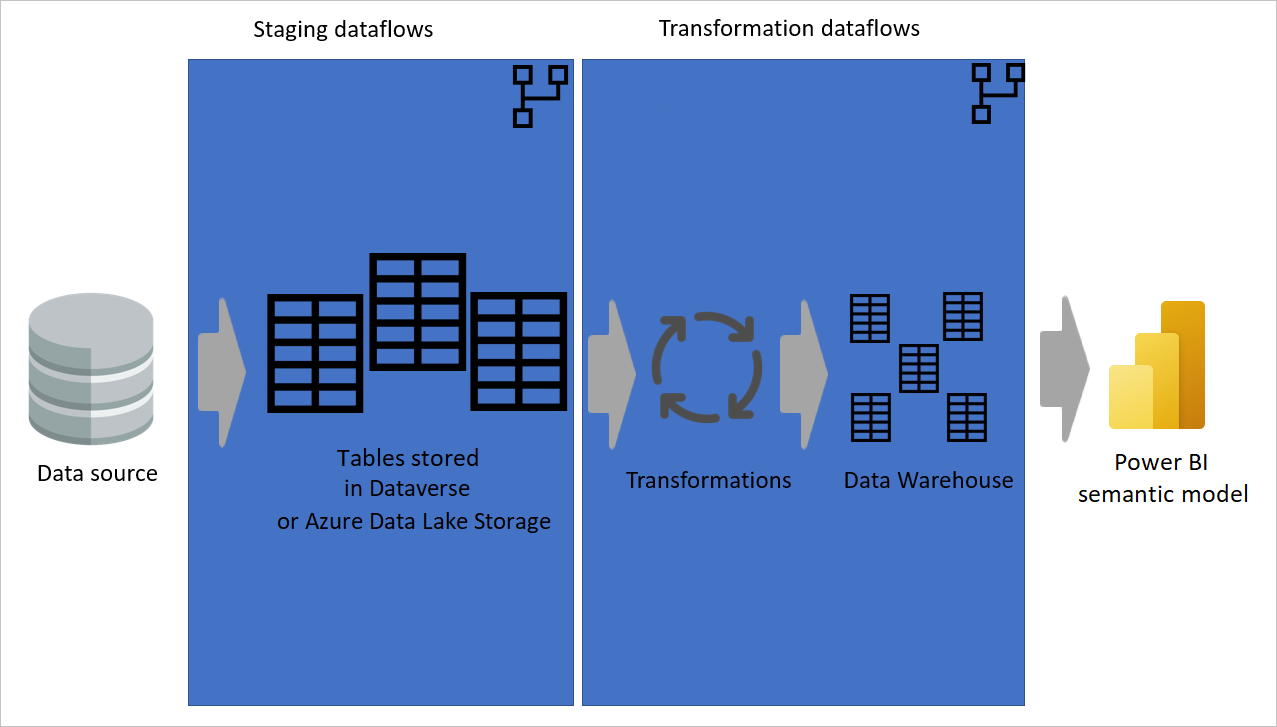
Image avec des données extraites d’une source de données vers des dataflows intermédiaires, où les tables sont stockées dans Dataverse ou Azure Data Lake Storage. Ensuite, les données sont déplacées vers des dataflows de transformation où les données sont transformées et converties en structure de l’entrepôt de données. Enfin, les données sont chargées dans un modèle sémantique Power BI.
Utiliser plusieurs espaces de travail
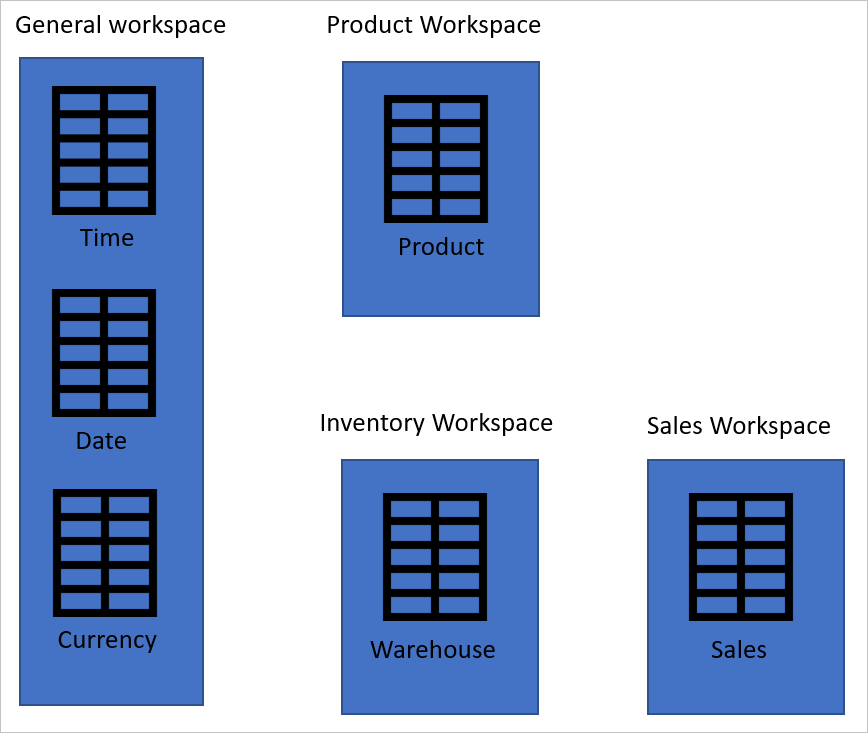
Chaque espace de travail (ou environnement) est disponible uniquement pour les membres de cet espace de travail. Si vous générez tous vos flux de données dans un espace de travail, vous réduisez la réutilisation de vos dataflows. Vous pouvez disposer d’espaces de travail génériques pour les dataflows qui traitent des tables à l’échelle de l’entreprise. Vous pouvez également disposer d’un espace de travail pour que les flux de données traitent des tables entre plusieurs services. Vous pouvez également disposer d’espaces de travail pour que les flux de données soient utilisés uniquement dans des services spécifiques.
Définir les niveaux d’accès corrects sur les espaces de travail
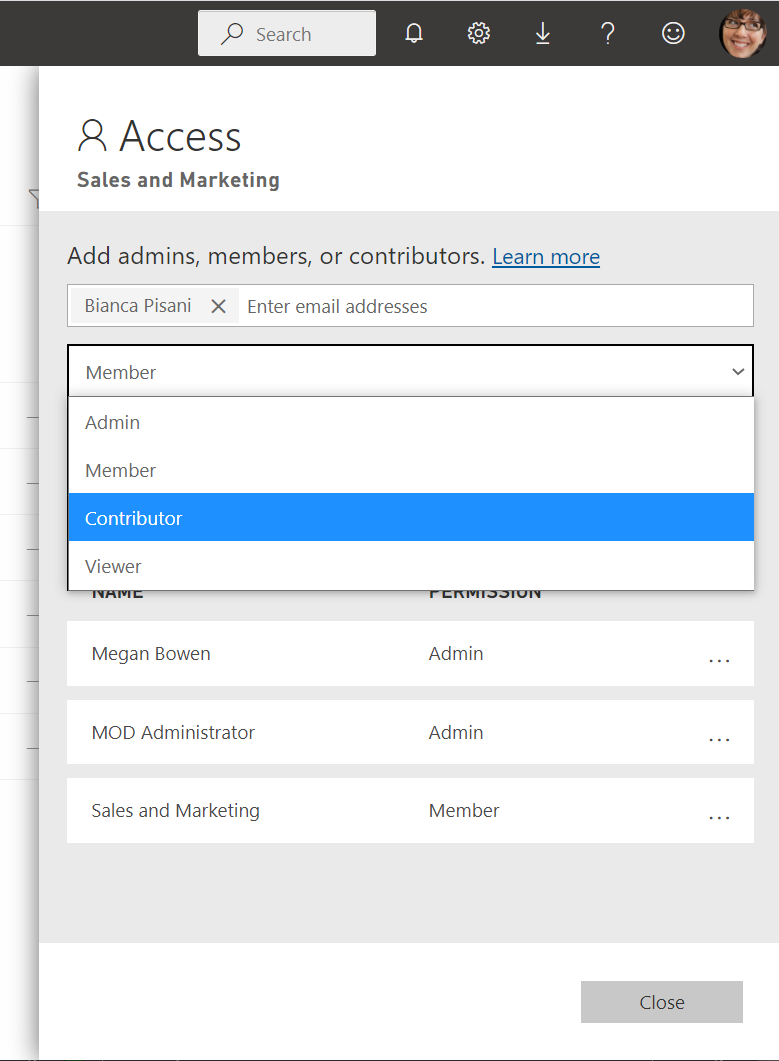
Pour accorder l’accès aux dataflows dans d’autres espaces de travail pour utiliser la sortie d’un flux de données dans un espace de travail, vous devez simplement leur accorder l’accès Affichage dans l’espace de travail. Pour en savoir plus sur d’autres rôles dans un espace de travail Power BI, accédez aux rôles dans les nouveaux espaces de travail.
Approbation sur le flux de données dans Power BI
Il peut y avoir de nombreux dataflows créés dans une organisation cliente, et il peut être difficile pour les utilisateurs de savoir quel flux de données est le plus fiable. Les auteurs d’un flux de données, ou ceux qui ont un accès en modification, peuvent approuver le flux de données à trois niveaux : aucune approbation, promotion ou certification.
Ces niveaux d’approbation aident les utilisateurs à trouver des flux de données fiables plus faciles et plus rapides. Le flux de données avec un niveau d’approbation supérieur apparaît en premier. L’administrateur Power BI peut déléguer la possibilité d’approuver des flux de données au niveau certifié à d’autres personnes. Plus d’informations : Approbation - Promotion et certification du contenu Power BI

Séparer les tables dans plusieurs dataflows
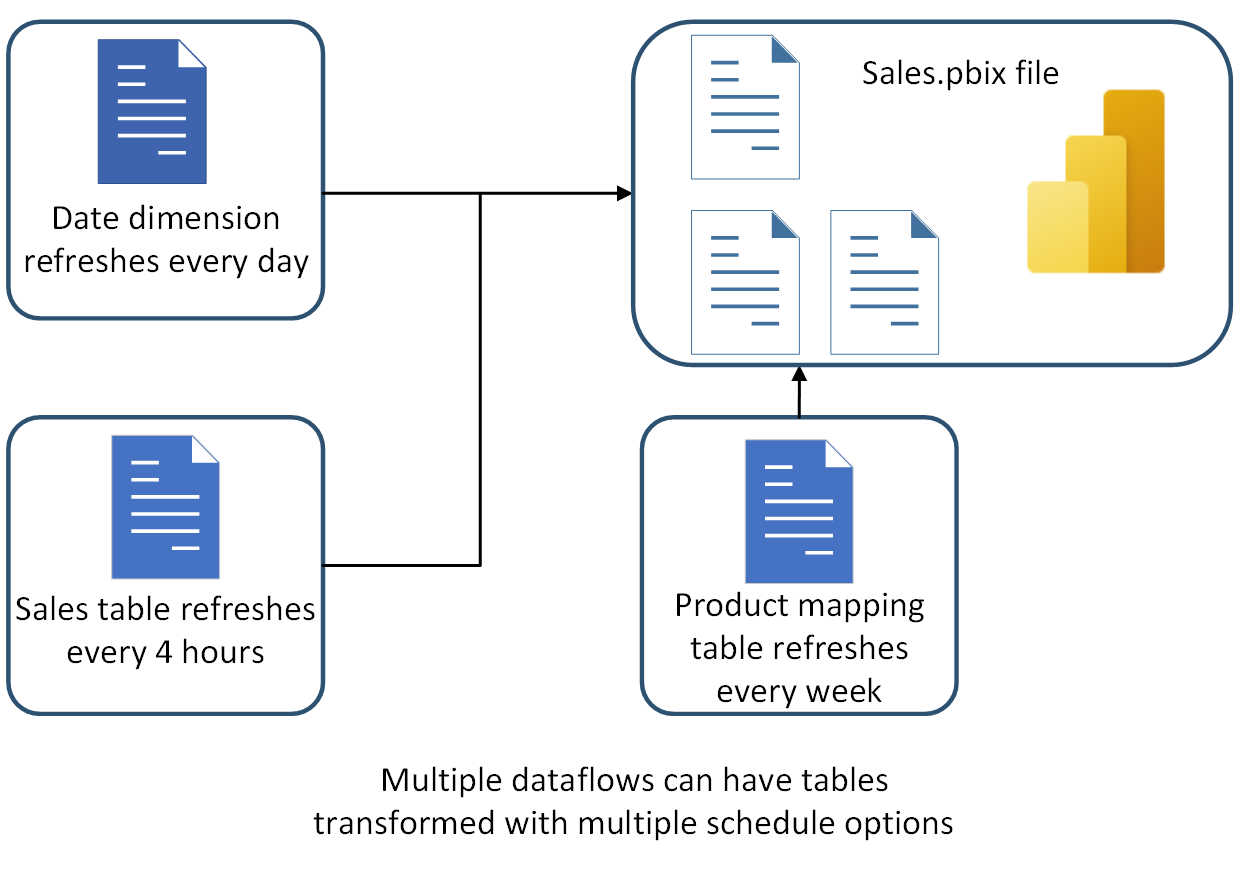
Vous pouvez avoir plusieurs tables dans un dataflow. L’une des raisons pour lesquelles vous pouvez fractionner des tables dans plusieurs dataflows est ce que vous avez appris précédemment dans cet article sur la séparation des flux de données d’ingestion et de transformation de données. Une autre bonne raison d’avoir des tables dans plusieurs dataflows est quand vous souhaitez une planification d’actualisation différente de celle d’autres tables.
Dans l’exemple illustré dans l’image suivante, la table des ventes doit être actualisée toutes les quatre heures. La table de dates doit être actualisée une seule fois par jour pour conserver l’enregistrement de date actuel mis à jour. Et une table de mappage de produit doit simplement être actualisée une fois par semaine. Si vous avez toutes ces tables dans un flux de données, vous n’avez qu’une seule option d’actualisation pour toutes ces tables. Toutefois, si vous fractionnez ces tables en plusieurs dataflows, vous pouvez planifier l’actualisation de chaque dataflow séparément.
Bonnes tables candidates pour les tables de flux de données
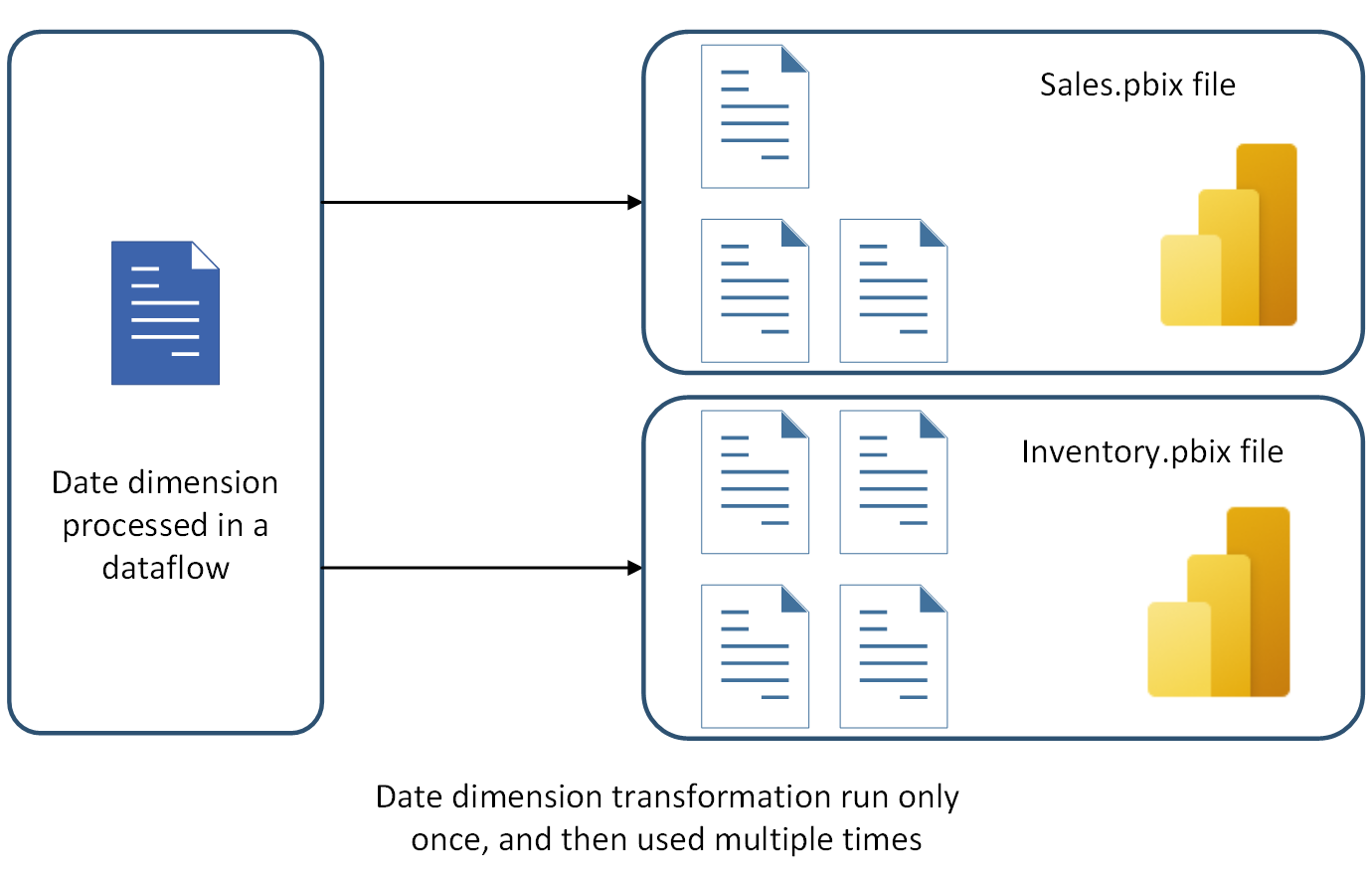
Lorsque vous développez des solutions à l’aide de Power Query dans les outils de bureau, vous pouvez vous demander ; Parmi ces tables, quels sont les bons candidats à déplacer vers un dataflow ? Les meilleures tables à déplacer vers le flux de données sont celles qui doivent être utilisées dans plusieurs solutions, ou plusieurs environnements ou services. Par exemple, le tableau Date indiqué dans l’image suivante doit être utilisé dans deux fichiers Power BI distincts. Au lieu de dupliquer cette table dans chaque fichier, vous pouvez générer la table dans un flux de données en tant que table et la réutiliser dans ces fichiers Power BI.