Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Conseil / Astuce
Power BI Dataflow Gen1 est désormais dans un état hérité et ne recevra pas de nouveaux investissements de fonctionnalités. Si vous configurez l’actualisation incrémentielle pour les jeux de données volumineux, envisagez Dataflow Gen2, qui prend en charge une expérience d’actualisation incrémentielle simplifiée avec des performances améliorées et des destinations de données supplémentaires. Pour en savoir plus sur la mise à niveau des dataflows existants, consultez Mise à niveau de Dataflow Gen1 vers Dataflow Gen2.
Avec les dataflows, vous pouvez importer de grandes quantités de données dans Power BI ou le stockage fourni par votre organisation. Toutefois, dans certains cas, il n’est pas pratique de mettre à jour une copie complète des données sources dans chaque actualisation. Une bonne alternative est l’actualisation incrémentielle, qui offre les avantages suivants pour les flux de données :
- L’actualisation se produit plus rapidement : seules les données modifiées doivent être actualisées. Par exemple, actualisez uniquement les cinq derniers jours d’un dataflow de 10 ans.
- L’actualisation est plus fiable : par exemple, il n’est pas nécessaire de maintenir des connexions longues aux systèmes sources volatiles.
- La consommation de ressources est réduite : moins de données à actualiser réduisent la consommation globale de mémoire et d’autres ressources.
L’actualisation incrémentielle est disponible dans les dataflows créés dans Power BI et les dataflows créés dans Power Apps. Cet article présente les écrans de Power BI, mais ces instructions s’appliquent aux flux de données créés dans Power BI ou dans Power Apps.
Note
Lorsque le schéma d’une table dans un dataflow analytique change, une actualisation complète a lieu pour s’assurer que toutes les données résultantes correspondent au nouveau schéma. Par conséquent, toutes les données stockées de manière incrémentielle sont actualisées et, dans certains cas, si le système source ne conserve pas les données historiques, celles-ci sont perdues.
L’utilisation de l’actualisation incrémentielle dans les flux de données créés dans Power BI nécessite que le flux de données réside dans un espace de travail dans une capacité Premium. L’actualisation incrémentielle dans Power Apps nécessite des plans Power Apps par application ou par utilisateur et n’est disponible que pour les flux de données avec Azure Data Lake Storage comme destination.
Dans Power BI ou Power Apps, l’actualisation incrémentielle nécessite que les données sources ingérées dans le flux de données aient un champ DateTime sur lequel l’actualisation incrémentielle peut filtrer.
Configuration de l’actualisation incrémentielle pour les flux de données
Un dataflow peut contenir de nombreuses tables. L’actualisation incrémentielle est configurée au niveau de la table, ce qui permet à un dataflow de contenir à la fois des tables entièrement actualisées et des tables actualisées de manière incrémentielle.
Pour configurer une table actualisée incrémentielle, commencez par configurer votre table comme vous le feriez pour n’importe quelle autre table.
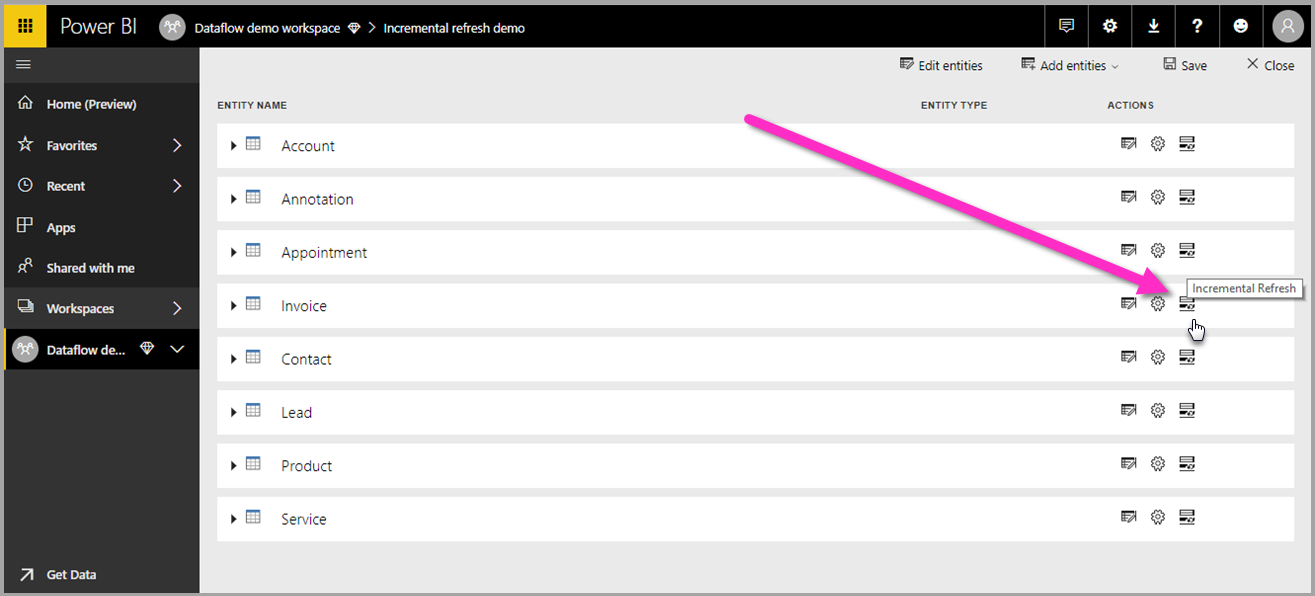
Une fois le flux de données créé et enregistré, sélectionnez Actualisation ![]() incrémentielle dans la vue table, comme illustré dans l’image suivante.
incrémentielle dans la vue table, comme illustré dans l’image suivante.
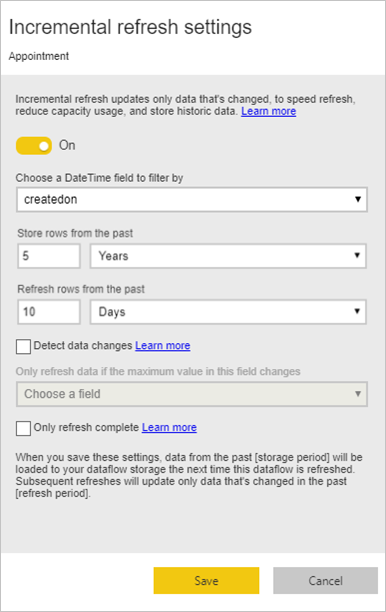
Lorsque vous sélectionnez l’icône, la fenêtre paramètres d’actualisation incrémentielle s’affiche. Activez l’actualisation incrémentielle.
La liste suivante décrit les paramètres dans la fenêtre Paramètres d’actualisation incrémentielle .
Bascule de l'actualisation incrémentielle : active ou désactive la stratégie d'actualisation incrémentielle pour la table.
Liste déroulante de champs de filtre : sélectionne le champ de requête sur lequel la table doit être filtrée pour les incréments. Ce champ contient uniquement des champs DateTime. Vous ne pouvez pas utiliser l’actualisation incrémentielle si votre table ne contient pas de champ DateTime.
Important
Choisissez un champ de date immuable pour le filtre d’actualisation incrémentielle. Si la valeur du champ change (par exemple, avec un champ de modification de date ), cette modification peut entraîner des échecs d’actualisation en raison de valeurs en double dans les données.
Stocker/actualiser les lignes du passé : l’exemple de l’image précédente illustre ces paramètres suivants.
Dans cet exemple, nous définissons une stratégie d’actualisation pour stocker cinq ans de données au total et actualiser de façon incrémentielle 10 jours de données. En supposant que la table est actualisée quotidiennement, les actions suivantes sont effectuées pour chaque opération d’actualisation :
Ajoutez un nouveau jour de données.
Actualisez 10 jours jusqu’à la date actuelle.
Supprimez les années civiles antérieures à cinq ans avant la date actuelle. Par exemple, si la date actuelle est le 1er janvier 2019, l’année 2013 est supprimée.
La première actualisation du flux de données peut prendre un certain temps pour importer toutes les cinq années, mais les actualisations suivantes sont susceptibles d’être effectuées beaucoup plus rapidement.
Détecter les modifications de données : une actualisation incrémentielle de 10 jours est beaucoup plus efficace qu’une actualisation complète de cinq ans, mais vous pourrez peut-être faire encore mieux. Lorsque vous activez la case à cocher Détecter les modifications de données , vous pouvez sélectionner une colonne date/heure pour identifier et actualiser uniquement les jours où les données ont changé. Cela suppose qu’une telle colonne existe dans le système source, qui est généralement à des fins d’audit. La valeur maximale de cette colonne est évaluée pour chacune des périodes définies dans la plage incrémentielle. Si ces données n’ont pas changé depuis la dernière actualisation, il n’est pas nécessaire d’actualiser la période. Dans l’exemple, cela peut réduire encore le nombre de jours actualisés de manière incrémentielle de 10 à 2.
Conseil / Astuce
La conception actuelle nécessite que la colonne utilisée pour détecter les modifications de données soit conservée et mise en cache en mémoire. Vous pouvez envisager l’une des techniques suivantes pour réduire la cardinalité et la consommation de mémoire :
- Conservez uniquement la valeur maximale de cette colonne au moment de l’actualisation, peut-être à l’aide d’une fonction Power Query.
- Réduisez la précision à un niveau acceptable en fonction de vos exigences de fréquence d’actualisation.
Actualiser uniquement les périodes complètes : imaginez que votre actualisation est planifiée pour s’exécuter à 4 h 00 tous les jours. Si les données apparaissent dans le système source pendant les quatre premières heures de ce jour, vous ne souhaiterez peut-être pas en tenir compte. Certaines mesures commerciales, telles que les barils par jour dans l’industrie pétrolière et gazière, ne sont pas pratiques ou sensibles à prendre en compte en fonction des jours partiels.
Un autre exemple où l’actualisation des périodes complètes est appropriée consiste à actualiser les données d’un système financier. Imaginez un système financier où les données du mois précédent sont approuvées le 12e jour calendrier du mois. Vous pouvez définir la plage incrémentielle sur un mois et planifier l’actualisation à exécuter le 12e jour du mois. Avec cette option sélectionnée, le système actualise les données de janvier (la période mensuelle la plus récente) le 12 février.
Note
L’actualisation incrémentielle du flux de données détermine les dates en fonction de la logique suivante : si une actualisation est planifiée, l’actualisation incrémentielle pour les flux de données utilise le fuseau horaire défini dans la stratégie d’actualisation. Si aucune planification de l’actualisation n’existe, l’actualisation incrémentielle utilise l’heure de l’ordinateur exécutant l’actualisation.
Une fois l’actualisation incrémentielle configurée, le flux de données modifie automatiquement votre requête pour inclure le filtrage par date. Si le flux de données a été créé dans Power BI, vous pouvez également modifier la requête générée automatiquement à l’aide de l’éditeur avancé dans Power Query pour affiner ou personnaliser votre actualisation. En savoir plus sur l’actualisation incrémentielle et son fonctionnement dans les sections suivantes.
Note
Lorsque vous modifiez le flux de données, l’éditeur Power Query se connecte directement à la source de données et n’affiche pas les données mises en cache ou filtrées dans le dataflow après le traitement de la stratégie d’actualisation incrémentielle. Pour vérifier les données mises en cache à l’intérieur du flux de données, connectez-vous de Power BI Desktop au flux de données après avoir configuré la stratégie d’actualisation incrémentielle et actualisé le flux de données.
Actualisation incrémentielle et tables liées par rapport aux tables calculées
Pour les tables liées , l’actualisation incrémentielle met à jour la table source. Étant donné que les tables liées sont simplement un pointeur vers la table d’origine, l’actualisation incrémentielle n’a aucun impact sur la table liée. Lorsque la table source est actualisée en fonction de sa stratégie d’actualisation définie, toute table liée doit supposer que les données de la source sont actualisées.
Les tables calculées sont basées sur des requêtes exécutées sur un stockage de données, qui peut être un autre flux de données. Par conséquent, les tables calculées se comportent de la même façon que les tables liées.
Étant donné que les tables calculées et les tables liées se comportent de la même façon, les exigences et les étapes de configuration sont identiques pour les deux. Une différence est que pour les tables calculées, dans certaines configurations, l’actualisation incrémentielle ne peut pas s’exécuter de manière optimisée en raison de la façon dont les partitions sont générées.
Changement entre l’actualisation incrémentielle et l’actualisation complète
Les dataflows prennent en charge la modification de la stratégie d’actualisation entre l’actualisation incrémentielle et l’actualisation complète. Lorsqu’une modification se produit dans l’une ou l’autre direction (complète à incrémentielle ou incrémentielle à complète), la modification affecte le flux de données après l’actualisation suivante.
Lorsque vous déplacez un flux de données de l’actualisation complète vers l’actualisation incrémentielle, la nouvelle logique d’actualisation met à jour le flux de données en respectant la fenêtre d’actualisation et en incrémentant comme défini dans les paramètres d’actualisation incrémentielle.
Lorsque vous déplacez un flux de données d’une actualisation incrémentielle à une actualisation complète, toutes les données accumulées dans l’actualisation incrémentielle remplacent la stratégie définie dans l’actualisation complète. Vous devez approuver cette action.
Prise en charge du fuseau horaire dans l’actualisation incrémentielle
L’actualisation incrémentielle du flux de données dépend du moment où elle s’exécute. Le filtrage de la requête dépend du jour où elle s’exécute.
Pour prendre en charge ces dépendances et garantir la cohérence des données, l’actualisation incrémentielle pour les dataflows implémente l’heuristique suivante pour les scénarios d’actualisation maintenant :
Dans le cas où une actualisation planifiée est définie dans le système, l’actualisation incrémentielle utilise les paramètres de fuseau horaire de la section d’actualisation planifiée. Ce processus garantit que quel que soit le fuseau horaire dans lequel la personne actualise le flux de données, il est toujours cohérent avec la définition du système.
Si aucune actualisation planifiée n’est définie, les flux de données utilisent le fuseau horaire à partir de l’ordinateur de l’utilisateur qui effectue l’actualisation.
L’actualisation incrémentielle peut également être appelée à l’aide d’API. Dans ce cas, l’appel d’API peut contenir un paramètre de fuseau horaire utilisé dans l’actualisation. L’utilisation d’API peut être utile à des fins de test et de validation.
Détails de l’implémentation de l’actualisation incrémentielle
Les dataflows utilisent le partitionnement pour l’actualisation incrémentielle. L’actualisation incrémentielle dans les flux de données conserve le nombre minimal de partitions pour répondre aux exigences de la stratégie d’actualisation. Les anciennes partitions qui sortent de la plage sont supprimées, ce qui maintient une fenêtre glissante. Les partitions sont fusionnées de façon opportuniste, ce qui réduit le nombre total de partitions requises. Ce nombre minimal de partitions améliore la compression et, dans certains cas, peut améliorer les performances des requêtes.
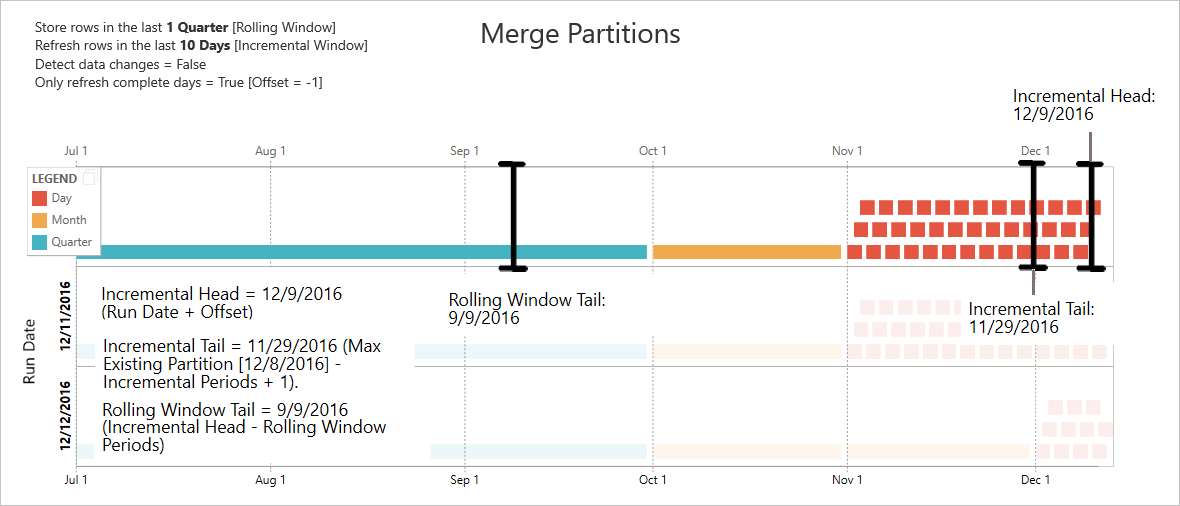
Les exemples de cette section partagent la stratégie d’actualisation suivante :
- Stocker des lignes au cours du dernier trimestre
- Actualiser les lignes des 10 derniers jours
- Détecter les modifications de données = False
- Actualiser uniquement les jours complets = True
Fusionner des partitions
Dans cet exemple, les partitions de jour sont automatiquement fusionnées à l'échelle du mois après avoir dépassé la plage incrémentielle. Les partitions de la plage incrémentielle doivent être maintenues à une granularité quotidienne pour permettre l’actualisation uniquement des jours concernés. L’opération d’actualisation avec la date d’exécution 12/11/2016 fusionne les jours en novembre, car ils sont en dehors de la plage incrémentielle.
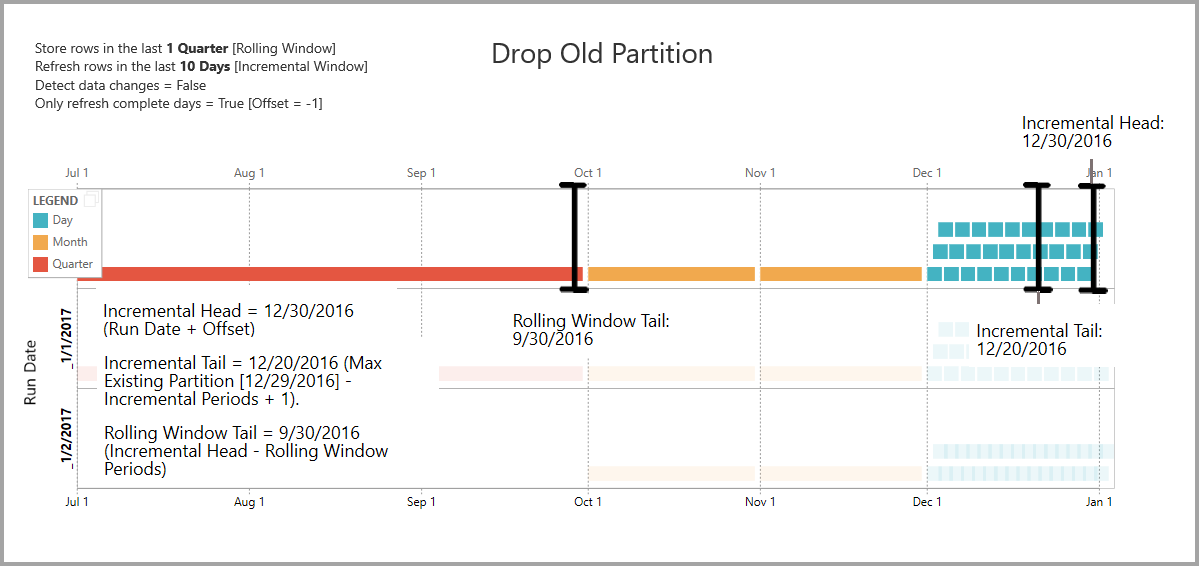
Supprimer les anciennes partitions
Les anciennes partitions qui se trouvent en dehors de la plage totale sont supprimées. L’opération d’actualisation avec la date d’exécution 1/2/2017 supprime la partition pour Q3 de 2016, car elle se situe en dehors de la plage totale.
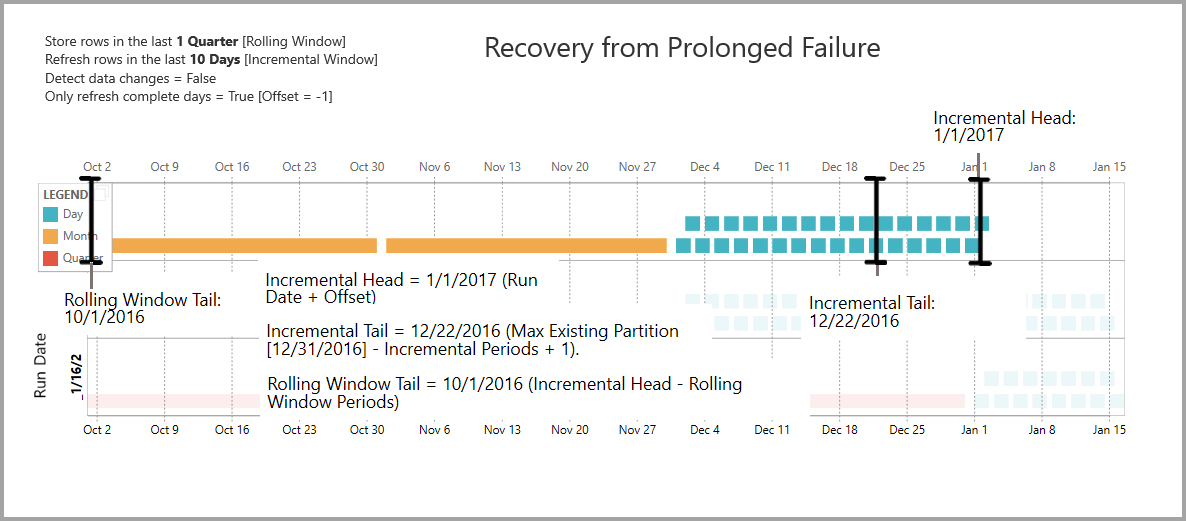
Récupération à partir d’une défaillance prolongée
Cet exemple montre comment le système récupère correctement après une défaillance prolongée. Supposons que l’actualisation ne s’exécute pas correctement, car les informations d’identification de la source de données ont expiré et que le problème prend 13 jours pour résoudre. La plage d'augmentation n’est que de 10 jours.
L’opération d’actualisation réussie suivante, avec la date d’exécution 1/15/2017, doit recomposer les 13 jours manquants et les actualiser. Il doit également actualiser les neuf jours précédents, car ils n’ont pas été actualisés selon la planification normale. Autrement dit, la plage incrémentielle passe de 10 à 22 jours.
L’opération d’actualisation suivante, avec la date d’exécution 1/16/2017, permet de fusionner les jours en décembre et les mois du trimestre 2016.
Actualisation incrémentielle du flux de données et jeux de données
L’actualisation incrémentielle du flux de données et l’actualisation incrémentielle du jeu de données sont conçues pour fonctionner en tandem. Il est acceptable et pris en charge de disposer d’une table d’actualisation incrémentielle dans un dataflow, entièrement chargé dans un jeu de données ou d’une table entièrement chargée dans un flux de données chargé de manière incrémentielle dans un jeu de données.
Les deux approches fonctionnent en fonction de vos définitions spécifiées dans les paramètres d’actualisation. Plus d’informations : Actualisation incrémentielle dans Power BI Premium
Contenu connexe
Cet article a décrit l’actualisation incrémentielle pour les flux de données. Voici quelques articles supplémentaires qui peuvent être utiles :
- Préparation des données en libre-service dans Power BI
- Création de tables calculées dans des flux de données
- Se connecter à des sources de données pour les flux de données
- Lier des tables entre des dataflows
- Créer et utiliser des dataflows dans Power BI
- Utilisation de dataflows avec des sources de données locales
- Ressources de développeur pour les dataflows Power BI
Pour plus d’informations sur Power Query et l’actualisation planifiée, vous pouvez lire ces articles :
Pour plus d’informations sur Common Data Model, vous pouvez lire son article de vue d’ensemble :