TripPin partie 5 - Pagination
Ce tutoriel en plusieurs parties traite de la création d’une extension de source de données pour Power Query. Le tutoriel est destiné à être utilisé de manière séquentielle : chaque leçon s’appuie sur le connecteur créé dans les leçons précédentes, ajoutant de nouvelles fonctionnalités de manière incrémentielle.
Dans cette leçon, vous allez :
- Ajouter la prise en charge de la pagination au connecteur
De nombreuses API Rest retournent des données dans des « pages », ce qui oblige les clients à effectuer plusieurs requêtes pour assembler les résultats. Bien qu’il existe certaines conventions courantes pour la pagination (par exemple , RFC 5988), elle varie généralement d’une API à l’autre. Heureusement, TripPin est un service OData et la norme OData définit un moyen de pagination à l’aide de valeurs odata.nextLink retournées dans le corps de la réponse.
Pour simplifier les itérations précédentes du connecteur, la fonction TripPin.Feed n’était pas consciente des pages. Il a simplement analysé tout ce que JSON a été retourné à partir de la demande et l’a mis en forme en tant que table. Les personnes familiarisées avec le protocole OData ont peut-être remarqué que plusieurs hypothèses incorrectes ont été formulées sur le format de la réponse (par exemple, en supposant qu’il existe un champ value contenant un tableau d’enregistrements).
Dans cette leçon, vous allez améliorer votre logique de gestion des réponses en la rendant consciente des pages. Les futurs tutoriels rendent la logique de gestion de page plus robuste et capable de gérer plusieurs formats de réponse (y compris les erreurs du service).
Remarque
Vous n’avez pas besoin d’implémenter votre propre logique de pagination avec des connecteurs basés sur OData.Feed, car il gère tout pour vous automatiquement.
Liste de contrôle de pagination
Lors de l’implémentation de la prise en charge de la pagination, vous devez connaître les éléments suivants sur votre API :
- Comment demander la page suivante des données ?
- Le mécanisme de pagination implique-t-il de calculer des valeurs ou d’extraire l’URL de la page suivante de la réponse ?
- Comment savez-vous quand arrêter la pagination ?
- Existe-t-il des paramètres liés à la pagination dont vous devez être conscient ? (par exemple, « taille de page »)
La réponse à ces questions a un impact sur la façon dont vous implémentez votre logique de pagination. Bien qu’il existe une certaine quantité de réutilisation du code dans les implémentations de pagination (par exemple, l’utilisation de Table.GenerateByPage, la plupart des connecteurs nécessitent une logique personnalisée.
Remarque
Cette leçon contient une logique de pagination pour un service OData, qui suit un format spécifique. Vérifiez la documentation de votre API pour déterminer les modifications que vous devez apporter dans votre connecteur pour prendre en charge son format de pagination.
Vue d’ensemble de la pagination OData
La pagination OData est pilotée par les annotations nextLink contenues dans la charge utile de réponse. La valeur nextLink contient l’URL de la page suivante des données. Vous pouvez savoir s’il existe une autre page de données en recherchant un champ odata.nextLink dans l’objet le plus externe dans la réponse. S’il n’y a pas de champ odata.nextLink, vous avez lu toutes vos données.
{
"odata.context": "...",
"odata.count": 37,
"value": [
{ },
{ },
{ }
],
"odata.nextLink": "...?$skiptoken=342r89"
}
Certains services OData permettent aux clients de fournir une préférence de taille de page maximale, mais il appartient au service de l’honorer ou non. Power Query doit être en mesure de gérer les réponses de n’importe quelle taille. Vous n’avez donc pas besoin de vous soucier de la spécification d’une préférence de taille de page, vous pouvez prendre en charge tout ce que le service vous envoie.
Vous trouverez plus d’informations sur la pagination pilotée par le serveur dans la spécification OData.
Test de TripPin
Avant de corriger votre implémentation de pagination, vérifiez le comportement actuel de l’extension à partir du tutoriel précédent. La requête de test suivante récupère la table People et ajoute une colonne d’index pour afficher votre nombre de lignes actuel.
let
source = TripPin.Contents(),
data = source{[Name="People"]}[Data],
withRowCount = Table.AddIndexColumn(data, "Index")
in
withRowCount
Activez Fiddler et exécutez la requête dans le Kit de développement logiciel (SDK) Power Query. Vous remarquez que la requête retourne une table avec huit lignes (index 0 à 7).
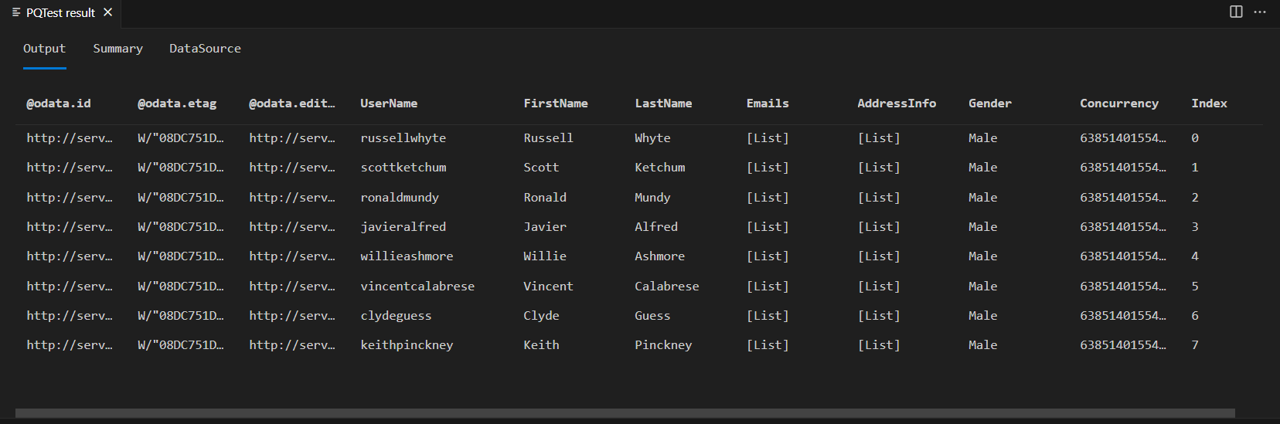
Si vous examinez le corps de la réponse de fiddler, vous verrez qu’il contient en fait un champ @odata.nextLink, indiquant qu’il existe plus de pages de données disponibles.
{
"@odata.context": "https://services.odata.org/V4/TripPinService/$metadata#People",
"@odata.nextLink": "https://services.odata.org/v4/TripPinService/People?%24skiptoken=8",
"value": [
{ },
{ },
{ }
]
}
Implémentation de la pagination pour TripPin
Vous allez maintenant apporter les modifications suivantes à votre extension :
- Importer la fonction commune
Table.GenerateByPage - Ajouter une fonction
GetAllPagesByNextLinkqui utiliseTable.GenerateByPagepour coller toutes les pages ensemble - Ajouter une fonction
GetPagequi peut lire une seule page de données - Ajouter une fonction
GetNextLinkpour extraire l’URL suivante de la réponse - Mettre à jour
TripPin.Feedpour utiliser les nouvelles fonctions du lecteur de page
Remarque
Comme indiqué précédemment dans ce tutoriel, la logique de pagination varie entre les sources de données. L’implémentation tente ici de décomposer la logique en fonctions qui doivent être réutilisables pour les sources qui utilisent les liens suivants retournés dans la réponse.
Table.GenerateByPage
Pour combiner (potentiellement) plusieurs pages retournées par la source dans une seule table, nous allons utiliser Table.GenerateByPage. Cette fonction prend comme argument une fonction getNextPage qui doit faire ce que son nom suggère : extraire la page de données suivante. Table.GenerateByPage appelle à plusieurs reprises la getNextPage fonction, chaque fois qu’elle passe les résultats générés la dernière fois qu’elle a été appelée, jusqu’à ce qu’elle retourne null pour signaler qu’aucune autre page n’est disponible.
Étant donné que cette fonction ne fait pas partie de la bibliothèque standard de Power Query, vous devez copier son code source dans votre fichier .pq.
Implémentation de GetAllPagesByNextLink
Le corps de votre function GetAllPagesByNextLink implémente getNextPage l'argument de fonction pour Table.GenerateByPage. Il appelle la fonction GetPage et récupère l’URL de la page suivante des données du champ NextLink de l’enregistrement meta à partir de l’appel précédent.
// Read all pages of data.
// After every page, we check the "NextLink" record on the metadata of the previous request.
// Table.GenerateByPage will keep asking for more pages until we return null.
GetAllPagesByNextLink = (url as text) as table =>
Table.GenerateByPage((previous) =>
let
// if previous is null, then this is our first page of data
nextLink = if (previous = null) then url else Value.Metadata(previous)[NextLink]?,
// if NextLink was set to null by the previous call, we know we have no more data
page = if (nextLink <> null) then GetPage(nextLink) else null
in
page
);
Implémentation de GetPage
Votre fonction GetPage utilise Web.Contents pour récupérer une seule page de données à partir du service TripPin et convertir la réponse en table. Elle transmet la réponse de Web.Contents à la fonction GetNextLink pour extraire l’URL de la page suivante et la définit sur l’enregistrement de la table meta retournée (page de données).
Cette implémentation est une version légèrement modifiée de l’appel TripPin.Feed à partir des didacticiels précédents.
GetPage = (url as text) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
data = Table.FromRecords(body[value])
in
data meta [NextLink = nextLink];
Implémentation de GetNextLink
Votre fonction GetNextLink vérifie simplement le corps de la réponse pour un champ @odata.nextLink et retourne sa valeur.
// In this implementation, 'response' will be the parsed body of the response after the call to Json.Document.
// Look for the '@odata.nextLink' field and simply return null if it doesn't exist.
GetNextLink = (response) as nullable text => Record.FieldOrDefault(response, "@odata.nextLink");
Exemple complet
La dernière étape pour implémenter votre logique de pagination consiste à mettre à jour TripPin.Feed pour utiliser les nouvelles fonctions. Pour l’instant, vous appelez simplement vers GetAllPagesByNextLink, mais dans les didacticiels suivants, vous allez ajouter de nouvelles fonctionnalités (telles que l’application d’un schéma et la logique de paramètre de requête).
TripPin.Feed = (url as text) as table => GetAllPagesByNextLink(url);
Si vous réexécutez la même requête de test précédemment dans le tutoriel, vous devez maintenant voir le lecteur de page en action. Vous devez également voir que vous avez 24 lignes dans la réponse plutôt que huit.

Si vous examinez les demandes dans fiddler, vous devez maintenant voir des demandes distinctes pour chaque page de données.

Remarque
Vous remarquerez les demandes en double pour la première page de données du service, ce qui n’est pas idéal. La requête supplémentaire est le résultat du comportement de vérification de schéma du moteur M. Ignorez ce problème pour l’instant et résolvez-le dans le didacticiel suivant, où vous appliquerez un schéma explicite.
Conclusion
Cette leçon vous a montré comment implémenter la prise en charge de la pagination pour une API Rest. Bien que la logique varie probablement entre les API, le modèle établi ici doit être réutilisable avec des modifications mineures.
Dans la leçon suivante, vous allez examiner comment appliquer un schéma explicite à vos données, en allant au-delà des types de données simples text et number que vous obtenez Json.Document.