TripPin, partie 6 - Schéma
Ce tutoriel en plusieurs parties traite de la création d’une extension de source de données pour Power Query. Le tutoriel est destiné à être utilisé de manière séquentielle : chaque leçon s’appuie sur le connecteur créé dans les leçons précédentes, ajoutant de nouvelles fonctionnalités de manière incrémentielle.
Dans cette leçon, vous allez :
- Définir un schéma fixe pour une API REST
- Définir dynamiquement des types de données pour des colonnes
- Appliquer une structure de table pour éviter les erreurs de transformation en raison de colonnes manquantes
- Masquer des colonnes du jeu de résultats
L’un des principaux avantages d’un service OData par rapport à une API REST standard est sa $définition des métadonnées. Le document $metadata décrit les données trouvées sur ce service, notamment le schéma pour toutes ses entités (tables) et champs (colonnes). La fonction OData.Feed utilise cette définition de schéma pour définir automatiquement les informations de type de données. Ainsi, au lieu d’obtenir tous les champs de texte et de nombre (comme vous le feriez avec Json.Document), les utilisateurs finaux obtiennent des dates, des nombres entiers, des heures, etc., améliorant ainsi leur expérience utilisateur globale.
De nombreuses API REST n’ont aucun moyen de déterminer leur schéma par programme. Dans ces cas, vous devrez inclure des définitions de schéma dans votre connecteur. Dans cette leçon, vous allez définir un schéma simple et codé en dur pour chacune de vos tables et appliquer le schéma aux données que vous lisez à partir du service.
Remarque
L’approche décrite ici doit fonctionner pour de nombreux services REST. Les futures leçons s’appuieront sur cette approche en appliquant de manière récursive des schémas sur des colonnes structurées (enregistrement, liste, table) et fourniront des exemples d’implémentations capables de générer par programmation une table de schéma à partir de documents CSDL ou JSON Schema.
Dans l’ensemble, l’application d’un schéma sur les données retournées par votre connecteur présente plusieurs avantages, par exemple :
- Définition des types de données corrects
- Suppression de colonnes que les utilisateurs finaux n’ont pas besoin de voir (comme des ID internes ou des informations d’état)
- Garantie que chaque page de données a la même forme par l’ajout de toute colonne qui pourrait manquer dans une réponse (une manière courante pour les API REST d’indiquer qu’un champ doit être null)
Affichage du schéma existant avec Table.Schema
Le connecteur créé dans la leçon précédente affiche trois tables du service TripPin —Airlines, Airports, et People. Exécutez la requête suivante pour afficher la Airlines table :
let
source = TripPin.Contents(),
data = source{[Name="Airlines"]}[Data]
in
data
Dans les résultats, quatre colonnes sont retournées :
- @odata.id
- @odata.editLink
- AirlineCode
- Nom

Les colonnes « @odata.* » font partie du protocole OData. Ce n’est pas quelque chose que vous souhaitez nécessairement montrer aux utilisateurs finaux de votre connecteur. AirlineCode et Name sont les deux colonnes que vous souhaitez conserver. Si vous examinez le schéma de la table (avec la fonction pratique Table.Schema), vous pouvez voir que toutes les colonnes de la table ont pour type de données Any.Type.
let
source = TripPin.Contents(),
data = source{[Name="Airlines"]}[Data]
in
Table.Schema(data)
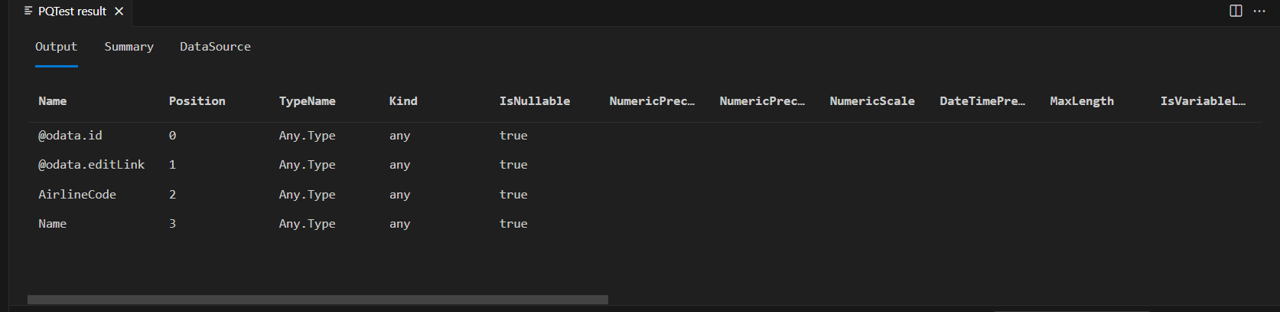
Table.Schema retourne plusieurs métadonnées sur les colonnes d’une table, dont les noms, les positions, les informations de type, ainsi que de nombreuses propriétés avancées telles que Precision, Scale et MaxLength.
Les futures leçons fourniront des modèles de conception pour définir ces propriétés avancées. Pour l’instant, souciez-vous uniquement du type attribué (TypeName), du type primitif (Kind) et du caractère nullable ou non de la valeur de la colonne (IsNullable).
Définition d’une table de schéma simple
Votre table de schéma sera composée de deux colonnes :
| Colonne | Détails |
|---|---|
| Nom | Nom de la colonne. Celui-ci doit correspondre au nom dans les résultats retournés par le service. |
| Type | Type de données M que vous allez définir. Il peut s’agir d’un type primitif (text, number, datetime, etc.) ou d’un type attribué (Int64.Type, Currency.Type, etc.). |
La table de schéma codée en dur pour la table Airlines définit ses colonnes AirlineCode et Name sur text et ressemble à ceci :
Airlines = #table({"Name", "Type"}, {
{"AirlineCode", type text},
{"Name", type text}
});
La table Airports comporte quatre champs que vous souhaiterez conserver (dont un de type record) :
Airports = #table({"Name", "Type"}, {
{"IcaoCode", type text},
{"Name", type text},
{"IataCode", type text},
{"Location", type record}
});
Enfin, la table People comporte sept champs, dont des listes (Emails, AddressInfo), une colonne nullable (Gender) et une colonne avec un type attribué (Concurrency).
People = #table({"Name", "Type"}, {
{"UserName", type text},
{"FirstName", type text},
{"LastName", type text},
{"Emails", type list},
{"AddressInfo", type list},
{"Gender", type nullable text},
{"Concurrency", Int64.Type}
})
La fonction d’assistance SchemaTransformTable
La fonction d’assistance SchemaTransformTable décrite ci-dessous sera utilisée pour appliquer des schémas à vos données. Les paramètres suivants sont pris en compte :
| Paramètre | Type | Description |
|---|---|---|
| table | table | Table de données à laquelle vous souhaitez appliquer votre schéma. |
| schéma | table | Table de schéma à partir de laquelle lire les informations de colonne, avec le type suivant : type table [Name = text, Type = type]. |
| enforceSchema | number | (facultatif) Énumération contrôlant le comportement de la fonction. La valeur par défaut ( EnforceSchema.Strict = 1) garantit que la table de sortie correspond à la table de schéma fournie en ajoutant toute colonne manquante et en supprimant toute colonne supplémentaire. L’option EnforceSchema.IgnoreExtraColumns = 2 permet de conserver des colonnes supplémentaires dans le résultat. Quand EnforceSchema.IgnoreMissingColumns = 3 est utilisé, les colonnes manquantes et les colonnes supplémentaires sont ignorées. |
La logique de cette fonction ressemble à ceci :
- Déterminer si des colonnes de la table source sont manquantes.
- Déterminer s’il y a des colonnes supplémentaires.
- Ignorer les colonnes structurées (de types
list,recordettable) et les colonnes définies surtype any. - Utiliser Table.TransformColumnTypes pour définir chaque type de colonne.
- Réorganiser les colonnes en fonction de l’ordre dans lequel elles apparaissent dans la table de schéma.
- Définir le type sur la table proprement dite avec Value.ReplaceType.
Remarque
La dernière étape de définition du type de table élimine la nécessité pour l’interface utilisateur de Power Query de déduire les informations de type lors de l’affichage des résultats dans l’éditeur de requête. Cela supprime le problème de double requête que vous avez vu à la fin du tutoriel précédent.
Vous pouvez copier et coller le code d’assistance suivant dans votre extension :
EnforceSchema.Strict = 1; // Add any missing columns, remove extra columns, set table type
EnforceSchema.IgnoreExtraColumns = 2; // Add missing columns, do not remove extra columns
EnforceSchema.IgnoreMissingColumns = 3; // Do not add or remove columns
SchemaTransformTable = (table as table, schema as table, optional enforceSchema as number) as table =>
let
// Default to EnforceSchema.Strict
_enforceSchema = if (enforceSchema <> null) then enforceSchema else EnforceSchema.Strict,
// Applies type transforms to a given table
EnforceTypes = (table as table, schema as table) as table =>
let
map = (t) => if Type.Is(t, type list) or Type.Is(t, type record) or t = type any then null else t,
mapped = Table.TransformColumns(schema, {"Type", map}),
omitted = Table.SelectRows(mapped, each [Type] <> null),
existingColumns = Table.ColumnNames(table),
removeMissing = Table.SelectRows(omitted, each List.Contains(existingColumns, [Name])),
primativeTransforms = Table.ToRows(removeMissing),
changedPrimatives = Table.TransformColumnTypes(table, primativeTransforms)
in
changedPrimatives,
// Returns the table type for a given schema
SchemaToTableType = (schema as table) as type =>
let
toList = List.Transform(schema[Type], (t) => [Type=t, Optional=false]),
toRecord = Record.FromList(toList, schema[Name]),
toType = Type.ForRecord(toRecord, false)
in
type table (toType),
// Determine if we have extra/missing columns.
// The enforceSchema parameter determines what we do about them.
schemaNames = schema[Name],
foundNames = Table.ColumnNames(table),
addNames = List.RemoveItems(schemaNames, foundNames),
extraNames = List.RemoveItems(foundNames, schemaNames),
tmp = Text.NewGuid(),
added = Table.AddColumn(table, tmp, each []),
expanded = Table.ExpandRecordColumn(added, tmp, addNames),
result = if List.IsEmpty(addNames) then table else expanded,
fullList =
if (_enforceSchema = EnforceSchema.Strict) then
schemaNames
else if (_enforceSchema = EnforceSchema.IgnoreMissingColumns) then
foundNames
else
schemaNames & extraNames,
// Select the final list of columns.
// These will be ordered according to the schema table.
reordered = Table.SelectColumns(result, fullList, MissingField.Ignore),
enforcedTypes = EnforceTypes(reordered, schema),
withType = if (_enforceSchema = EnforceSchema.Strict) then Value.ReplaceType(enforcedTypes, SchemaToTableType(schema)) else enforcedTypes
in
withType;
Mise à jour du connecteur TripPin
Vous allez maintenant apporter les modifications suivantes à votre connecteur pour utiliser le nouveau code d’application de schéma.
- Définissez une table de schéma maître (
SchemaTable) qui contient toutes vos définitions de schéma. - Mettez à jour
TripPin.Feed,GetPageetGetAllPagesByNextLinkpour accepter un paramètreschema. - Appliquez votre schéma dans
GetPage. - Mettez à jour le code de votre table de navigation pour wrapper chaque table avec un appel à une nouvelle fonction (
GetEntity). Cela vous donnera plus de flexibilité pour manipuler les définitions de table à l’avenir.
Table de schéma maître
Vous allez maintenant consolider vos définitions de schéma dans une seule table et ajouter une fonction d’assistance (GetSchemaForEntity) qui vous permet de rechercher la définition en fonction d’un nom d’entité (par exemple, GetSchemaForEntity("Airlines")).
SchemaTable = #table({"Entity", "SchemaTable"}, {
{"Airlines", #table({"Name", "Type"}, {
{"AirlineCode", type text},
{"Name", type text}
})},
{"Airports", #table({"Name", "Type"}, {
{"IcaoCode", type text},
{"Name", type text},
{"IataCode", type text},
{"Location", type record}
})},
{"People", #table({"Name", "Type"}, {
{"UserName", type text},
{"FirstName", type text},
{"LastName", type text},
{"Emails", type list},
{"AddressInfo", type list},
{"Gender", type nullable text},
{"Concurrency", Int64.Type}
})}
});
GetSchemaForEntity = (entity as text) as table => try SchemaTable{[Entity=entity]}[SchemaTable] otherwise error "Couldn't find entity: '" & entity &"'";
Ajout de la prise en charge du schéma aux fonctions de données
Vous allez maintenant ajouter un paramètre schema facultatif aux fonctions TripPin.Feed, GetPage et GetAllPagesByNextLink.
Cela vous permettra de passer le schéma (quand vous le souhaitez) aux fonctions de pagination, où il sera appliqué aux résultats récupérés du service.
TripPin.Feed = (url as text, optional schema as table) as table => ...
GetPage = (url as text, optional schema as table) as table => ...
GetAllPagesByNextLink = (url as text, optional schema as table) as table => ...
Vous mettrez également à jour tous les appels à ces fonctions afin de passer correctement le schéma.
Application du schéma
L’application réelle du schéma est effectuée dans votre fonction GetPage.
GetPage = (url as text, optional schema as table) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
data = Table.FromRecords(body[value]),
// enforce the schema
withSchema = if (schema <> null) then SchemaTransformTable(data, schema) else data
in
withSchema meta [NextLink = nextLink];
Remarque
Cette implémentation GetPage utilise Table.FromRecords pour convertir la liste des enregistrements dans la réponse JSON en table.
Un inconvénient majeur de l’utilisation de Table.FromRecords est qu’il suppose que tous les enregistrements de la liste ont le même ensemble de champs.
Cela fonctionne pour le service TripPin, car les enregistrements OData contiennent toujours les mêmes champs, mais cela peut ne pas être le cas pour toutes les API REST.
Pour une implémentation plus robuste, combinez Table.FromList et Table.ExpandRecordColumn.
Les prochains tutoriels modifieront l’implémentation pour obtenir la liste des colonnes à partir de la table de schéma. De cette façon, aucune colonne ne sera perdue ou manquante lors de la traduction de JSON en M.
Ajout de la fonction GetEntity
La fonction GetEntity wrappe votre appel à TripPin.Feed.
Elle recherche une définition de schéma basée sur le nom de l’entité et génère l’URL de requête complète.
GetEntity = (url as text, entity as text) as table =>
let
fullUrl = Uri.Combine(url, entity),
schemaTable = GetSchemaForEntity(entity),
result = TripPin.Feed(fullUrl, schemaTable)
in
result;
Vous mettez ensuite à jour votre fonction TripPinNavTable pour appeler GetEntity, au lieu de passer tous les appels en ligne.
L’avantage principal, c’est que vous pouvez continuer à modifier votre code de génération d’entités sans avoir à changer la logique de votre table de navigation.
TripPinNavTable = (url as text) as table =>
let
entitiesAsTable = Table.FromList(RootEntities, Splitter.SplitByNothing()),
rename = Table.RenameColumns(entitiesAsTable, {{"Column1", "Name"}}),
// Add Data as a calculated column
withData = Table.AddColumn(rename, "Data", each GetEntity(url, [Name]), type table),
// Add ItemKind and ItemName as fixed text values
withItemKind = Table.AddColumn(withData, "ItemKind", each "Table", type text),
withItemName = Table.AddColumn(withItemKind, "ItemName", each "Table", type text),
// Indicate that the node should not be expandable
withIsLeaf = Table.AddColumn(withItemName, "IsLeaf", each true, type logical),
// Generate the nav table
navTable = Table.ToNavigationTable(withIsLeaf, {"Name"}, "Name", "Data", "ItemKind", "ItemName", "IsLeaf")
in
navTable;
Exemple complet
Une fois toutes les modifications de code apportées, compilez et réexécutez la requête de test qui appelle Table.Schema pour la table Airlines.
let
source = TripPin.Contents(),
data = source{[Name="Airlines"]}[Data]
in
Table.Schema(data)
Vous voyez maintenant que votre table Airlines n’a que les deux colonnes que vous avez définies dans son schéma :

Si vous exécutez le même code sur la table People...
let
source = TripPin.Contents(),
data = source{[Name="People"]}[Data]
in
Table.Schema(data)
Vous pouvez voir que le type attribué que vous avez utilisé (Int64.Type) est également défini correctement.

Une chose importante à noter est que cette implémentation de SchemaTransformTable ne modifie pas les types des colonnes list et record. Les colonnes Emails et AddressInfo sont toujours de type list. Cela est dû au fait que Json.Document mappe correctement les tables JSON aux listes M et les objets JSON aux enregistrements M. Si vous développiez la liste ou la colonne d’enregistrements dans Power Query, vous verriez que toutes les colonnes développées sont de type any. Les prochains tutoriels amélioreront l’implémentation pour définir de manière récursive les informations de type pour les types complexes imbriqués.
Conclusion
Ce tutoriel a mis à votre disposition un exemple d’implémentation pour appliquer un schéma sur les données JSON retournées par un service REST. Bien que cet exemple utilise un format de table de schéma codé en dur simple, l’approche peut être étendue en créant dynamiquement une définition de table de schéma à partir d’une autre source, comme un fichier de schéma JSON ou un service/point de terminaison de métadonnées exposé par la source de données.
En plus de modifier les types de colonne (et les valeurs), votre code définit également les bonnes informations de type sur la table elle-même. La définition de ces informations de type améliore les performances en cas d’exécution dans Power Query, car l’expérience utilisateur tente toujours de déduire les informations de type pour afficher les files d’attente d’IU appropriées à l’utilisateur final, et les appels d’inférence peuvent finir par déclencher des appels supplémentaires aux API de données sous-jacentes.
Si vous affichez la table People avec le connecteur TripPin de la leçon précédente, vous verrez que toutes les colonnes ont une icône « type any » (même celles qui contiennent des listes) :

Si vous exécutez la même requête avec le connecteur TripPin de cette leçon, vous voyez maintenant que les informations de type s’affichent correctement.
