Utiliser l’Explorateur de travaux et la Vue des travaux pour Azure Data Lake Analytics
Important
Azure Data Lake Analytics mis hors service le 29 février 2024. Découvrez-en plus avec cette annonce.
Pour l’analytique des données, votre organization peut utiliser Azure Synapse Analytics ou Microsoft Fabric.
Le service Azure Data Lake Analytics archive les travaux soumis dans un magasin de requêtes. Dans cet article, vous allez apprendre à utiliser l’Explorateur de travaux et la Vue des travaux dans Azure Data Lake Tools pour Visual Studio pour trouver les informations d’historique des travaux.
Par défaut, le service Data Lake Analytics archive les travaux des 30 derniers jours. La période d’expiration peut être configurée à partir du portail Azure en définissant la stratégie d’expiration personnalisée. Vous ne pourrez pas accéder aux informations du travail après l’expiration.
Prérequis
Voir Data Lake Tools for Visual Studio - Composants requis.
Ouverture de l’Explorateur de travaux
Accédez à l’Explorateur de travaux en sélectionnant Explorateur de serveurs > Azure > Data Lake Analytics > Travaux dans Visual Studio. L’explorateur de travaux vous permet d’accéder au magasin de requêtes d’un compte Data Lake Analytics. Il présente le magasin des requêtes sur la gauche, lequel indique des informations de base sur les travaux, et la vue du travail sur la droite, laquelle indique des informations détaillées sur les travaux.
Vue des travaux
La Vue des travaux affiche des informations détaillées sur un travail. Pour ouvrir un travail, vous pouvez double-cliquer sur un travail dans l’Explorateur de travaux ou l’ouvrir à partir du menu Data Lake en cliquant sur Vue des travaux. Une boîte de dialogue indiquant l’URL du travail devrait apparaître.
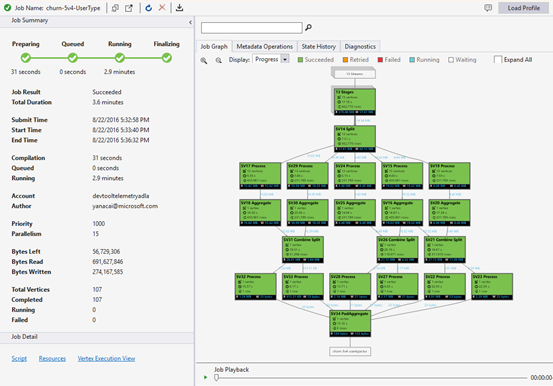
La Vue des travaux contient les éléments suivants :
Résumé des tâches
Actualisez l’affichage des travaux pour afficher les informations les plus récentes sur l’exécution des travaux.
Statut de tâche (graphique) :
Le statut de tâche indique les phases du travail :
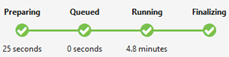
Préparation : Chargez votre script dans le cloud en le compilant et en l’optimisant à l’aide du service de compilation.
Mis en file d’attente : les travaux sont mis en file d’attente lorsqu’ils attendent suffisamment de ressources, ou les travaux dépassent la limite maximale de travaux simultanés par compte. Le paramètre de priorité détermine l’ordre des travaux mis en file d’attente : plus le numéro est faible, plus la priorité est élevée.
Running : Le travail est en cours d’exécution dans votre compte Data Lake Analytics.
Finalisation : Le travail se termine (par exemple, finalisation du fichier).
Le travail peut échouer à chaque phase. Par exemple, en cas d’erreurs de compilation dans la phase de préparation, d’erreurs d’expiration de délai lors de la phase de mise en file d’attente et d’erreurs d’exécution dans la phase d’exécution, etc.
Informations de base
Les informations de base sur le travail apparaissent dans la partie inférieure du volet Résumé des tâches.
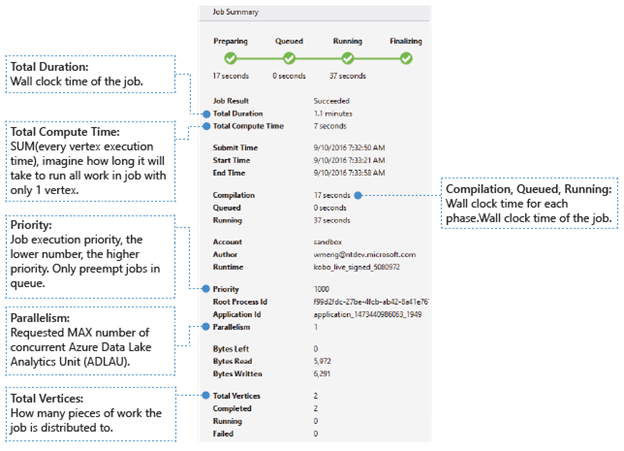
- Résultat du travail : A réussi ou a échoué. Le travail peut échouer à chaque phase.
- Durée totale : Temps écoulé (durée) entre l’heure de soumission et l’heure de fin.
- Durée totale de calcul : Somme des temps d’exécution de chaque vertex, que vous pouvez considérer comme le temps d’exécution du travail dans un seul vertex. Reportez-vous à la valeur Total des vertex pour plus d’informations sur les vertex.
- Heure de soumission/début/fin : Heure à laquelle le service Data Lake Analytics reçoit le travail soumis/commence à exécuter le travail/termine le travail avec succès ou non.
- Compilation/Mis en file d’attente/En cours d’exécution : Temps écoulé durant la phase de préparation/mise en file d’attente/en cours d’exécution.
- Compte : Compte Data Lake Analytics utilisé pour exécuter le travail.
- Auteur : Utilisateur qui a envoyé le travail. Il peut s’agit du compte d’une personne réelle ou d’un compte système.
- Priorité : Priorité du travail. Plus le numéro est faible, plus la priorité est élevée. Cette valeur affecte uniquement l’ordre des travaux dans la file d’attente. La définition d’une priorité plus élevée ne préempte pas l’exécution des travaux.
- Parallélisme : Nombre maximal demandé d’unités Azure Data Lake Analytics (ADLAU) simultanées, également appelées vertex. Actuellement, un vertex est égal à une machine virtuelle avec deux cœurs virtuels et six Go de RAM, bien que cela puisse être mis à niveau dans les futures mises à jour Data Lake Analytics.
- Octets restants : Octets qui restent à traiter jusqu'à ce que la tâche soit terminée.
- Octets lus/écrits : Octets qui ont été lus/écrits depuis le début de l’exécution du travail.
- Total des vertex : Le travail est divisé en plusieurs éléments, chaque élément étant appelé un vertex. Cette valeur indique le nombre d’éléments qui composent le travail. Vous pouvez considérer un vertex comme une unité de processus de base, également appelée Unité Azure Data Lake Analytics (ADLAU), et des vertex peuvent être exécutés dans le parallélisme.
- Terminé/En cours d’exécution/Échec : Nombre de vertex terminés/en cours d’exécution/ayant échoué. Les vertex peuvent échouer en raison d’erreurs au niveau du code utilisateur et du système, mais le système tente de relancer automatiquement plusieurs fois les vertex ayant échoué. Si le vertex échoue toujours après une nouvelle tentative, la totalité du travail échoue.
Graphique du travail
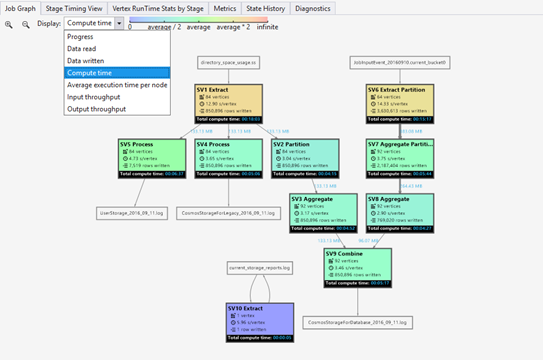
Un script SQL-U représente la logique de la transformation des données d’entrée en données de sortie. Le script est compilé et optimisé pour un plan d’exécution physique lors la phase de préparation. Graphique du travail permet d’afficher le plan d’exécution physique. Le diagramme suivant illustre ce processus :
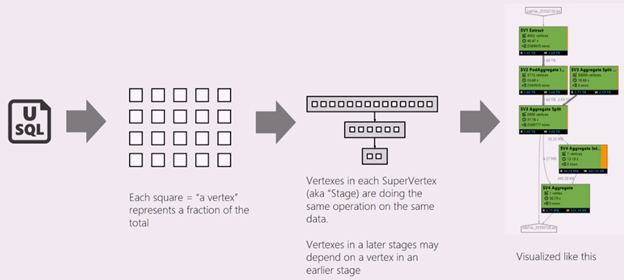
Un travail est divisé en plusieurs éléments. Chaque élément est appelé un vertex. Les vertex sont regroupés en Super Vertex (également appelé phase) et visualisés sous la forme d’un Graphique du travail. Les panneaux verts dans le graphique du travail indiquant les différentes phases.
Chaque vertex d’une phase effectue le même type de travail en utilisant différentes parties des mêmes données. Par exemple, si vous avez un fichier avec des données d’un To et qu’il y a des centaines de sommets lisant à partir de celui-ci, chacun d’eux lit un bloc. Ces sommets sont regroupés dans la même phase et effectuent le même travail sur différents éléments du même fichier d’entrée.
-
Au cours d’une phase spécifique, certains nombres apparaissent dans le panneau.
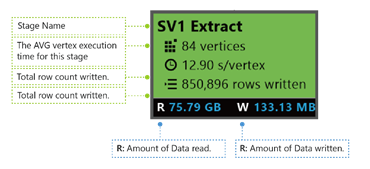
SV1 Extract : Nom d’une phase, défini par un nombre et par la méthode d’opération.
84 vertex : Nombre total de vertex dans cette phase. La figure indique le nombre d’éléments de travail divisés dans cette phase.
12.90 s/vertex : Temps d’exécution moyen du vertex pour cette phase. Ce chiffre est calculé à l’aide de la fonction SUM (temps d’exécution de chaque vertex)/(nombre de vertex). Ce qui signifie que si vous avez pu attribuer tous les vertex exécutés dans le parallélisme, la totalité de la phase s’est terminée en 12,90 s. Cela signifie également que si tout le travail de cette phase a été effectué en série, le coût équivaudrait au nombre de vertex * temps moyen.
850 895 lignes écrites : Nombre total de lignes écrites au cours de cette phase.
R/W : Quantité de données lues/écrites au cours de cette phase, en octets.
Couleurs : Couleurs utilisées dans cette phase pour indiquer le statut des différents vertex.
- Vert indique que le vertex a réussi.
- Orange indique que le vertex a été relancé. Le vertex relancé a échoué mais il a été correctement automatiquement relancé par le système et la totalité de la phase s’est terminée avec succès. Si le vertex relancé échoue toujours, la couleur passe au rouge et la totalité du travail échoue.
- Rouge indique un échec, c’est-à-dire qu’un vertex a été relancé plusieurs fois par le système mais échoue toujours. Ce scénario provoque l’échec de la totalité du travail.
- Bleu signifie qu’un vertex est en cours d’exécution.
- Blanc indique que le vertex est en attente. Le vertex peut être en attente d’être planifié une fois qu’un ADLAU devient disponible, ou il peut être en attente d’entrée, car ses données d’entrée peuvent ne pas être prêtes.
Vous trouverez plus de détails sur la phase en plaçant le curseur de la souris sur un état :
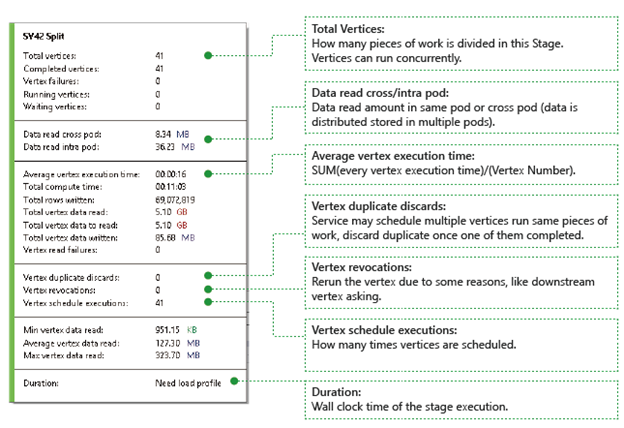
Vertex : Décrit les détails des vertex, par exemple le nombre total de vertex, le nombre de vertex terminés, ayant échoué, toujours en cours d’exécution, en attente, etc.
Lecture des données dans un ou plusieurs pods : Les fichiers et les données sont stockés dans plusieurs pods dans un système de fichiers distribués. Cette valeur décrit la quantité de données lues dans le même pod ou dans plusieurs pods.
Durée totale de calcul : Somme des temps d’exécution de chaque vertex au cours de la phase, que vous pouvez considérer comme le temps nécessaire si la totalité du travail de cette phase est exécutée dans un seul vertex.
Données et lignes écrites/lues : Indique la quantité de données ou de lignes qui ont été lues/écrites ou qui doivent être lues.
Échecs de lecture de vertex : Indique le nombre de vertex qui ont échoué lors de la lecture de données.
Abandons des doublons de vertex : si un vertex s’exécute trop lentement, le système peut planifier plusieurs sommets pour exécuter le même élément de travail. Les sommets redondants sont ignorés une fois l’un des sommets terminé avec succès. Cette option enregistre le nombre de vertex qui ont été ignorés car représentant des doublons dans la phase.
Révocations de vertex : Le vertex a réussi, mais a été réexécuté ultérieurement pour certaines raisons. Par exemple, si un vertex en aval perd des données d’entrée intermédiaires, il demandera au vertex en amont de s’exécuter à nouveau.
Exécutions de planifications de vertex : Durée totale de planification des vertex.
Données minimales/moyennes/maximales lues : Valeur minimale/moyenne/maximale des données lues pour chaque vertex.
Durée : Temps écoulé d’une phase. Vous devez charger le profil pour afficher cette valeur.
Lecture de travail
Data Lake Analytics exécute les travaux et archive les informations d’exécution des sommets des travaux, telles que le démarrage, l’arrêt, l’échec et la façon dont ils sont retentés, etc. Toutes les informations sont automatiquement enregistrées dans le magasin de requêtes et stockées dans son profil de travail. Vous pouvez télécharger le profil de travail via l’option « Charger le profil » de la Vue des travaux, et vous pouvez afficher l’option Lecture de travail après avoir téléchargé le profil de travail.
Lecture de travail est une visualisation symbolique des opérations effectuées dans le cluster. Elle vous permet de surveiller la progression de l'exécution du travail et de détecter visuellement les anomalies de performance et les goulots d'étranglement très rapidement (moins de 30 s généralement).
Affichage du tableau (Heat Map) du travail
Le tableau du travail peut être sélectionné dans la liste déroulante Affichage du menu Graphique du travail.
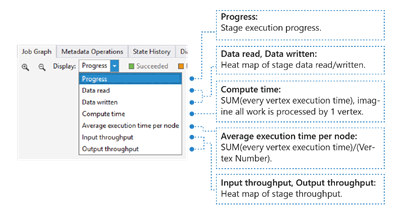
Cette option indique les valeurs d’E/S, de temps et de débit d’un travail, vous permettant d’identifier les zones où le travail passe le plus de temps, ou si votre travail est un travail avec des limites d’E/S et ainsi de suite.
- Progression : Progression de l’exécution du travail. Pour en savoir plus, consultez les informations de la phase.
- Données lues/écrites : Tableau des données totales lues/écrites à chaque phase.
- Temps de calcul : carte thermique de SOMME (chaque temps d’exécution de vertex), vous pouvez considérer cela comme le temps nécessaire si tout le travail de la phase est exécuté avec un seul vertex.
- Temps d’exécution moyen par nœud : Tableau de la fonction SUM (temps d’exécution de chaque vertex)/(nombre de vertex). Ce qui signifie que si vous avez pu attribuer tous les vertex exécutés dans le parallélisme, la totalité de la phase sera effectuée dans ce laps de temps.
- Débit d’entrée/sortie : Tableau du débit d’entrée/sortie de chaque phase, vous permettant de vérifier si votre travail comporte des limites d’E/S.
-
Opérations sur les métadonnées
Vous pouvez effectuer certaines opérations sur les métadonnées dans votre script SQL-U, notamment créer une base de données, supprimer une table, etc. Ces opérations sont affichées dans Opération sur les métadonnées après compilation. Vous pouvez trouver des assertions, créer des entités, supprimer des entités ici.

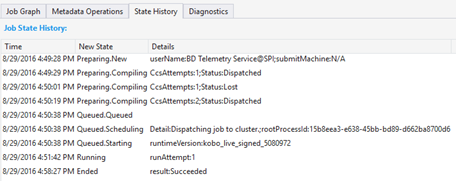
Historique de l'état
L’historique de l’état est également affiché dans le Résumé des tâches, mais vous pouvez obtenir plus de détails ici. Vous trouverez des informations détaillées telles l’heure à laquelle le travail a été préparé, mis en attente, démarré et terminé. Vous trouverez également le nombre de fois que le travail a été compilé (CcsAttempts : 1), quand le travail est réellement réparti sur le cluster (Détail : Répartition du travail sur le cluster), etc.
Diagnostics
L’outil diagnostique automatiquement l’exécution du travail. Vous recevrez des alertes en cas d’erreurs ou de problèmes de performances dans vos travaux. Veuillez noter que vous devez télécharger le profil pour obtenir ici des informations complètes.
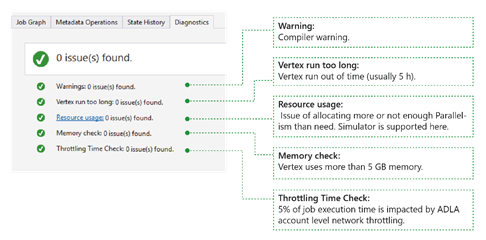
- Avertissements : Une alerte apparaît ici avec un avertissement du compilateur. Vous pouvez sélectionner le lien « x problème(s) » pour obtenir plus de détails une fois l’alerte affichée.
- Le vertex s’exécute trop longtemps : si un sommet manque de temps (par exemple 5 heures), les problèmes se trouvent ici.
- Utilisation des ressources : Si vous avez alloué trop ou pas assez de parallélisme par rapport à ce qui est nécessaire, les problèmes sont décrits ici. Vous pouvez également sélectionner Utilisation des ressources pour afficher plus de détails et effectuer des scénarios de simulation afin de trouver une meilleure allocation de ressources (pour plus d’informations, consultez ce guide).
- Vérification de la mémoire : Si un vertex utilise plus de 5 Go de mémoire, les problèmes sont décrits ici. L’exécution du travail peut être supprimée par le système s’il utilise plus de mémoire que la limitation du système.
Détail du travail
L’option Détail de la tâche affiche des informations détaillées sur le travail, y compris le script, les ressources et la vue d’exécution du vertex.
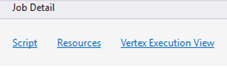
Script
Le script SQL-U du travail est stocké dans le magasin de requêtes. Vous pouvez afficher le script U-SQL d’origine et le renvoyer si nécessaire.
Ressources
Les sorties de compilation du travail sont stockés dans le magasin de requêtes via l’option Ressources. Par exemple, vous pouvez rechercher ici l’expression « algebra.xml », utilisée pour afficher le graphique du travail, les assemblys que vous avez enregistrés, etc.
Vue d’exécution du vertex
Affiche des détails sur l’exécution des vertex. Le profil du travail archive chaque journal d’exécution du vertex, notamment le total des données lues/écrites, le temps d’exécution, l’état, etc. Dans cette vue, vous pouvez obtenir plus d’informations sur la façon dont un travail a été exécuté. Pour plus d’informations, consultez Utilisation de la vue d’exécution du vertex dans Azure Data Lake Tools pour Visual Studio.
Étapes suivantes
- Pour consigner les informations de diagnostic, consultez Accès aux journaux de diagnostic d’Azure Data Lake Analytics
- Pour voir une requête plus complexe, consultez Analyse de journaux d’activité des sites web à l’aide d’Azure Data Lake Analytics.
- Pour utiliser la vue d’exécution du vertex, consultez Utilisation de la vue d’exécution du vertex dans Data Lake Tools pour Visual Studio