Les commerçants et les marques de consommateurs s’attachent à proposer aux consommateurs les produits et services qu’ils sont susceptibles d’acheter sur le marché. Les produits (ou combinaisons de produits) constituent la majeure partie de l’expérience d’achat, jouant ainsi un rôle majeur dans le développement des ventes. La disponibilité des offres (stock) est un souci constant pour les marques de consommateurs.
Le stock de produits, également appelé assortiment de références SKU, est une question complexe qui englobe la chaîne de valeurs de l’approvisionnement et de la logistique. Dans le cadre de cet article, nous nous concentrons plus particulièrement sur le problème de l’optimisation de l’assortiment des références SKU pour optimiser les recettes du point de vue des biens de consommation.
Vous pouvez résoudre le puzzle de l’optimisation de l’assortiment des références SKU en développant des algorithmes répondant aux questions suivantes :
- Quelles sont les références SKU particulièrement performantes sur un marché ou dans un magasin donné ?
- Quelles sont les références SKU qui devraient être allouées à un marché ou magasin donné en fonction de leurs performances ?
- Quelles sont les références SKU peu performantes et qui devraient être remplacées par des références plus performantes ?
- Quels autres insights pouvons-nous tirer de nos segments de consommateurs et de marché ?
Automatiser la prise de décision
Historiquement, les marques de consommateurs ont cherché à résoudre la question de la demande du consommateur en augmentant le nombre de références SKU dans le portefeuille de références. Avec l’explosion du nombre de références SKU et une concurrence plus forte, il est estimé que 90 % du chiffre d’affaires est attribué à seulement 10 % de références SKU produits dans le portefeuille. En règle générale, 80 % du chiffre d’affaires est généré par 20 % de références SKU. Un tel ratio montre que la rentabilité peut être améliorée.
Les méthodes classiques de création de rapports statiques utilisent des données historiques, ce qui limite les insights. Au mieux, les décisions sont toujours prises et implémentées manuellement. Cela suppose une intervention humaine et du temps de traitement. Avec les avancées de l’IA et du cloud computing, il est possible de faire appel à une analytique avancée pour fournir une palette de choix et de prédictions. Ce type d’automatisation améliore les résultats et la vitesse de mise sur le marché.
Optimisation de l’assortiment des références SKU
Une solution d’assortiment de références SKU doit gérer des millions de références en segmentant les données de ventes en comparaisons significatives et détaillées. L’objectif de la solution consiste à utiliser l’analytique avancée pour optimiser les ventes à chaque point de vente ou magasin en paramétrant l’assortiment des produits. Un deuxième objectif consiste à éliminer les ruptures de stocks et à améliorer les assortiments. L’objectif financier est une augmentation de 5 à 10 % des ventes. À cette fin, les insights permettent :
- De comprendre les performances du portefeuille de références SKU et de gérer les références peu performantes.
- D’optimiser la distribution des références SKU pour réduire les ruptures de stocks.
- De comprendre dans quelle mesure les nouvelles références SKU s’inscrivent dans les stratégies à court terme et à long terme.
- De créer des insights reproductibles, scalables et actionnables à partir de données existantes.
Analytique descriptive
Les modèles descriptifs agrègent des points de données et explorent les relations entre les facteurs qui peuvent influer sur les ventes de produits. Les informations peuvent être complétées de points de données externes, tels que l’emplacement, des données météorologiques et des données de recensement. Les visualisations aident les personnes à dégager des insights en interprétant les données. Ce faisant, toutefois, la compréhension est limitée à ce qui s’est passé pendant le cycle de vente précédent ou éventuellement à ce qui se passe dans le cycle actuel (selon la fréquence d’actualisation des données).
Une approche traditionnelle d’entreposage de données et de création de rapports suffit dans ce cas pour comprendre, par exemple, quelles sont les références (SKU) qui ont été les plus et moins performantes sur une période de temps.
La figure ci-dessous présente un rapport type de données de ventes historiques. Il comprend plusieurs blocs dont les cases à cocher permettent de sélectionner des critères afin de filtrer les résultats. La partie centrale montre deux graphiques à barres qui affichent les ventes au fil du temps. Le premier graphique indique les ventes moyennes par semaine. Le second montre les quantités par semaine.

Analytique prédictive
Les rapports historiques aident à comprendre ce qui s’est passé. Ce qui nous intéresse, c’est d’obtenir une prévision de ce qui est susceptible de se produire. Les informations passées peuvent être utiles à cet effet. Par exemple, nous pouvons identifier les tendances saisonnières. Mais ces informations ne peuvent pas être utiles pour les scénarios d’hypothèse tels que la modélisation du lancement d’un nouveau produit. Pour ce faire, nous devons concentrer notre attention sur la modélisation du comportement des clients, principal facteur déterminant les ventes.
Examen approfondi du problème : modèles de choix
Commençons par définir ce que nous recherchons et les données que nous avons :
L’optimisation de l’assortiment consiste à trouver un sous-ensemble de produits à vendre qui optimise le chiffre d’affaires attendu. C’est ce que nous recherchons.
Les données de transaction sont régulièrement collectées à des fins financières.
Les données d’assortiment peuvent comprendre tout ce qui se rapporte aux références SKU. Voici, par exemple, ce que nous voulons :
- Nombre de références SKU
- Descriptions de la référence (SKU)
- Quantités attribuées
- Référence SKU et quantité achetée
- Horodatages des événements (par exemple, achats)
- Prix des références SKU
- Prix des références SKU sur le point de vente
- Niveau de stock de chaque référence SKU à un moment quelconque
Malheureusement, ces données ne sont pas collectées de manière aussi fiable que les données de transaction.
Dans cet article, par souci de simplicité, nous prendrons en compte les données de transactions et les données de références SKU, mais pas les facteurs externes.
Même ainsi, pour un ensemble de n produits, il y a 2n assortiments possibles. Cela fait du problème d’optimisation un processus gourmand en calculs. L’évaluation de toutes les combinaisons possibles est peu pratique avec un grand nombre de produits. Ainsi, les assortiments sont généralement segmentés par catégorie (par exemple, céréales), emplacement et autres critères afin que soit réduit le nombre de variables. Les modèles d’optimisation essaient de réduire le nombre de permutations de manière à obtenir un sous-ensemble exploitable.
L’essentiel du problème réside dans la modélisation du comportement des consommateurs de façon efficace. Dans un monde parfait, les produits présentés à ces derniers correspondent à ceux qu’ils souhaitent acheter.
Des modèles mathématiques de prédiction des choix du consommateur ont été développés au cours des dernières décennies. Le choix du modèle détermine la technologie de mise en œuvre la plus appropriée. Nous allons donc récapituler les modèles et formulerons quelques considérations.
Modèles paramétriques
Les modèles paramétriques évaluent le comportement des clients à l’aide d’une fonction comportant un ensemble fini de paramètres. Nous estimons le jeu de paramètres le plus approprié compte tenu des données à notre disposition. L’un des plus anciens et les plus connus est le modèle de régression logistique multinomiale (également appelée modèle MNL, logit multi-classes ou régression softmax). Il sert à calculer les probabilités de plusieurs issues possibles dans les problèmes de classification. Dans ce cas, vous pouvez utiliser le modèle MNL pour calculer :
La probabilité qu’un consommateur (c) choisisse un article (i) à un moment donné (t), en fonction d’un ensemble d’articles de la même catégorie dans un assortiment (a) ayant une utilité connue pour le client (v).
Nous supposons également que l’utilité d’un article peut être une fonction de ses caractéristiques. Des informations externes peuvent également être incluses dans la mesure de l’utilité (par exemple, un parapluie est plus utile quand il pleut).
Nous utilisons souvent le modèle MNL comme point de référence pour d’autres modèles en raison de sa malléabilité quand il s’agit d’estimer des paramètres et d’évaluer des résultats. En d’autres termes, si vous faites pire que le modèle MNL, votre algorithme n’est d’aucune utilité.
Plusieurs modèles ont été dérivés du modèle MNL, mais leur présentation dépasse le cadre de ce document.
Il existe des bibliothèques pour les langages de programmation R et Python. Pour R, vous pouvez utiliser glm (et ses dérivés). Pour Python, il existe scikit-learn, biogeme et larch. Ces bibliothèques offrent des outils, pour spécifier des problèmes MNL, et des solveurs parallèles, pour trouver des solutions sur diverses plateformes.
Récemment, l’implémentation de modèles MNL sur des GPU a été proposée pour rendre possible le calcul de modèles complexes avec une série de paramètres.
Des réseaux neuronaux avec une couche de sortie softmax ont été utilisés efficacement sur des problèmes multi-classes complexes. Ces réseaux produisent un vecteur de sorties qui représentent une loi de probabilité sur une série d’issues différentes. Ils sont lents à entraîner par rapport à d’autres implémentations, mais ils peuvent gérer un grand nombre de classes et de paramètres.
Modèles non paramétriques
En dépit de sa popularité, le modèle MNL base certaines hypothèses importantes sur le comportement humain, ce qui peut limiter son utilité. En particulier, il suppose que la probabilité relative qu’une personne choisisse entre deux options est indépendante d’autres alternatives introduites dans l’ensemble ultérieurement. C’est peu pratique dans la plupart des cas.
Par exemple, si vous aimez les produits A et B autant l’un que l’autre, vous choisirez l’un plutôt que l’autre une fois sur deux. Ajoutons le produit C à l’éventail des choix. Vous pouvez toujours choisir le produit A une fois sur deux, mais désormais votre préférence va à 25 % pour le produit B et à 25 % pour le produit C. La probabilité relative a changé.
En outre, le modèle MNL et ses dérivés n’ont aucun moyen simple pour prendre en compte les substitutions dues à une rupture de stock ou à la variété de l’assortiment (situation d’indécision qui aboutit à la sélection aléatoire d’un article parmi ceux disponibles en rayon).
Les modèles non paramétriques sont conçus pour tenir compte des substitutions et imposent moins de contraintes sur le comportement des clients.
Ils introduisent le concept de classement, où les consommateurs expriment une préférence stricte pour des produits dans un assortiment. Vous pouvez ainsi modéliser leur comportement d’achat en triant les produits dans l’ordre de préférence décroissant.
Le problème de l’optimisation de l’assortiment peut être exprimé par la maximisation du chiffre d’affaires :
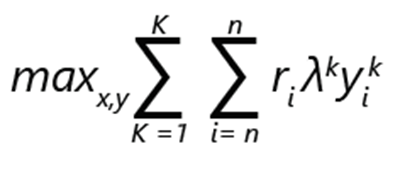
- ri désigne le chiffre d’affaires généré par le produit i.
- yik a la valeur 1 si le produit i est choisi dans le classement k. Sinon, la valeur est 0.
- λk est la probabilité que le client effectue un choix en fonction du classement k.
- xi a la valeur 1 si le produit est inclus dans l’assortiment. Sinon, la valeur est 0.
- K représente le nombre de classements.
- n représente le nombre de produits.
Notes
Il existe des contraintes :
- Il peut y avoir exactement 1 choix par classement.
- Dans le cadre d’un classement k, un produit i peut être choisi uniquement s’il fait partie de l’assortiment.
- Si un produit i est inclus dans l’assortiment, aucune des options moins préférables dans le classement k ne peut être choisie.
- L’absence d’achat étant une option, aucune des options les moins préférables dans un classement ne peut être choisie.
Dans une telle formulation, le problème peut être considéré comme une optimisation mixte en nombres entiers.
Considérons que s’il y a n produits, le nombre maximal de classements possibles, y compris l’option de l’absence de choix, est factoriel : (n+1)!
Les contraintes de formulation permettent une réduction relativement efficace des options possibles. Par exemple, seule l’option la plus préférable est choisie et définie sur 1. Le reste est défini sur 0. Vous pouvez imaginer que la scalabilité de l’implémentation sera importante, compte tenu du nombre d’alternatives possibles.
Importance des données
Nous avons mentionné plus haut que les données de ventes sont disponibles. Nous souhaitons les utiliser pour alimenter notre modèle d’optimisation de l’assortiment. En particulier, nous voulons trouver notre loi de probabilité λ.
Les données de ventes issues du système de points de vente se composent de transactions horodatées et d’un ensemble de produits qui est proposé aux clients aux moment et emplacement concernés. À partir de ces données, nous pouvons construire un vecteur de ventes réelles, dont les éléments vi,m représentent la probabilité de vente de l’article i à un client en fonction d’un assortiment Sm.
Nous pouvons également construire une matrice :
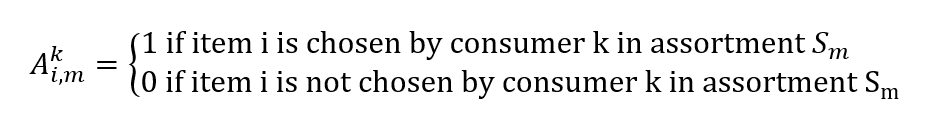
La recherche de notre loi de probabilité λ en fonction de nos données de ventes devient un autre problème d’optimisation. Nous souhaitons trouver un vecteur λ afin de réduire notre erreur d’estimation des ventes :
minλ |Λλ - v|
Notez que le calcul peut également être exprimé sous la forme d’une régression ; ainsi, les modèles tels que les arbres de décision multivariés peuvent être utilisés.
Informations d’implémentation
Comme nous pouvons le déduire de la formulation précédente, les modèles d’optimisation sont pilotés par les données et font appel à des calculs intensifs.
Des partenaires de Microsoft, tels que Neal Analytics, ont développé des architectures robustes pour satisfaire à ces conditions. Veuillez consulter la rubrique Optimisation de l’assortiment des références SKU. Nous allons utiliser ces architectures à titre d’exemple et formuler quelques considérations.
- Tout d’abord, elles s’appuient sur un pipeline de données robuste et scalable pour alimenter les modèles et une infrastructure d’exécution robuste et scalable pour les exécuter.
- En second lieu, les planificateurs peuvent aisément exploiter les résultats par le biais d’un tableau de bord.
La figure 2 montre un exemple d’architecture. Elle inclut quatre blocs principaux : capture, traitement, modélisation et opérationnalisation. Chaque bloc contient des processus majeurs. Le bloc de la capture inclut le processus de prétraitement des données. Le bloc du traitement inclut la fonction de stockage des données. Le bloc de la modélisation inclut la fonction d’entraînement du modèle de machine learning et le bloc de l’opérationnalisation inclut les options de stockage des données et de création de rapports (telles que des tableaux de bord).

Figure 2 : Architecture d’une optimisation des références SKU, fournie par Neal Analytics
Pipeline de données
L’architecture met en évidence l’importance de l’établissement d’un pipeline de données pour l’entraînement et l’exploitation du modèle. Nous orchestrons les activités du pipeline en utilisant Azure Data Factory, service ETL (extraction, transformation et chargement) managé qui vous permet de concevoir et d’exécuter vos workflows d’intégration.
Azure Data Factory est un service managé dont les composants, appelés activités, consomment et/ou produisent des jeux de données.
Les activités peuvent être divisées comme suit :
- Déplacement des données (par exemple, copie à partir de la source vers la destination)
- Transformation des données (par exemple, agrégation avec une requête SQL ou exécution d’une procédure stockée)
Les workflows qui lient les ensembles d’activités peuvent être planifiés, supervisés et gérés par le service de fabrique de données. Le workflow complet est appelé pipeline.
Dans la phase de capture, nous pouvons utiliser l’activité de copie de Data Factory pour transférer des données à partir de diverses sources (à la fois locales et dans le cloud) vers Azure SQL Data Warehouse. La documentation contient des exemples qui illustrent cette procédure :
- Copier des données depuis/vers Azure SQL Data Warehouse
- Charger des données dans Azure SQL Data Warehouse
La figure suivante présente la définition d’un pipeline. Il se compose de trois blocs successifs de taille identique. Les deux premiers sont un jeu de données et une activité reliés par des flèches indiquant les flux de données. Le troisième est étiqueté Pipeline et pointe vers les deux premiers pour indiquer l’encapsulation.

Figure 3 : concepts de base d’Azure Data Factory
Vous trouverez un exemple de format de données utilisé par la solution Neal Analytics dans la page de la Place de marché commerciale Microsoft. La solution inclut les jeux de données suivants :
- Données de l’historique des ventes pour chaque combinaison de magasin et de référence SKU
- Enregistrements des magasins et des consommateurs
- Codes et description des références SKU
- Attributs de référence SKU qui capturent les caractéristiques des produits (par exemple, la taille et le matériau). Ils sont généralement utilisés dans les modèles paramétriques pour faire la distinction entre les variantes de produit.
Si les sources de données ne sont pas exprimées dans un format particulier, Data Factory offre une série d’activités de transformation.
Dans la phase de traitement, SQL Data Warehouse est le moteur de stockage principal. Vous pouvez exprimer une activité de transformation en tant que procédure stockée SQL, qui peut être appelée automatiquement dans le cadre du pipeline. La documentation fournit des instructions détaillées :
Notez que Data Factory ne vous limite pas aux procédures stockées SQL Data Warehouse et SQL. En fait, il s’intègre à un large éventail de plateformes. Vous pouvez, par exemple, utiliser Databricks et exécuter un script Python à la place d’une transformation. Avec cette approche, vous pouvez utiliser une même plateforme pour le stockage, la transformation et l’entraînement des algorithmes de machine learning dans la phase de modélisation suivante.
Entraînement de l’algorithme ML
Il existe plusieurs outils qui peuvent vous aider à implémenter des modèles paramétriques et non paramétriques. Votre choix dépend de vos exigences concernant la scalabilité et le niveau de performance.
Azure ML Studio est un excellent outil pour le prototypage. Il fournit un moyen simple pour générer et exécuter un workflow d’entraînement avec vos modules de code (en R ou Python) ou avec des composants ML prédéfinis (par exemple, les classifieurs multi-classes et la régression d’arbre de décision boostée) dans un environnement graphique. Il vous permet également de publier facilement un modèle entraîné en tant que service web en vue de sa consommation, générant automatiquement une interface REST.
Toutefois, la taille des données qu’il peut gérer est limitée à 10 Go, tandis que le nombre de cœurs disponibles pour chaque composant est limité à deux.
Si vous avez besoin d’affiner la mise à l’échelle, mais souhaitez bénéficier des implémentations Microsoft parallèles et rapides d’un algorithme de machine learning courant (tel que la régression logistique multinomiale), vous pouvez envisager d’utiliser Microsoft ML Server sur Azure Data Science Virtual Machine.
Pour les très grandes tailles de données (To), il est judicieux de choisir une plateforme où le stockage et l’élément de calcul peuvent :
- Être mis à l’échelle indépendamment, pour limiter les coûts quand vous n’entraînez pas les modèles.
- Répartir le calcul sur plusieurs cœurs.
- Exécuter le calcul près du stockage afin de limiter le déplacement des données.
Azure HDInsight et Databricks répondent à ces exigences. De plus, ces plateformes d’exécution sont toutes deux prises en charge dans l’éditeur d’Azure Data Factory. Il est relativement simple de les intégrer à un workflow.
Vous pouvez déployer ML Server et ses bibliothèques sur HDInsight, mais pour tirer pleinement parti des fonctionnalités de la plateforme, vous pouvez implémenter l’algorithme ML de votre choix en utilisant les bibliothèques SparkML ou Microsoft ML Spark dans Python ou tout autre résolveur de programmation linéaire spécialisé tel que TFoCS, Spark-LP ou SolveDF.
Pour démarrer le processus d’entraînement, il suffit alors d’appeler le notebook ou le script pySpark approprié à partir d’un workflow Data Factory. Cette procédure est entièrement prise en charge dans l’éditeur graphique. Pour plus d’informations, consultez Exécuter un notebook Databricks avec l’activité Databricks Notebook dans Azure Data Factory.
La figure ci-dessous présente l’interface utilisateur de Data Factory, telle qu’elle apparaît en y accédant via le portail Azure. Elle inclut les blocs des divers processus du workflow.

Figure 4 : exemple de pipeline Data Factory avec une activité de notebook Databricks
Notez également que dans notre solution d’optimisation du stock, nous proposons une implémentation de solveurs basée sur un conteneur qui est mise à l’échelle via Azure Batch. Les bibliothèques d’optimisation spécialisées comme pyomo vous donnent la possibilité d’exprimer un problème d’optimisation en utilisant le langage de programmation Python, puis en appelant des solveurs indépendants comme bonmin (open source) ou gurobi (licence commerciale) pour trouver une solution.
La documentation sur l’optimisation du stock porte sur un autre problème (quantités de commande) que l’optimisation de l’assortiment, mais l’implémentation des solveurs dans Azure s’applique de la même façon.
Bien que plus complexe que celles suggérées jusque-là, cette technique permet d’optimiser la scalabilité, principalement limitée par le nombre de cœurs que vous pouvez mettre en œuvre.
Exécution du modèle (opérationnalisation)
Une fois le modèle entraîné, son exécution nécessite généralement une infrastructure différente de celle qui est utilisée pour le déploiement. Pour le rendre facilement exploitable, vous pouvez le déployer en tant que service web avec une interface REST. Azure ML Studio et ML Server automatisent le processus de création de ces services. Dans le cas de ML Server, Microsoft fournit des modèles pour le déploiement d’une infrastructure de prise en charge. Consultez la documentation appropriée.
La figure suivante présente l’architecture du déploiement. Elle inclut les représentations de serveurs qui exécutent les langages R et Python. Les deux serveurs communiquent avec une sous-section de nœuds web qui effectuent des calculs. Un grand magasin de données est connecté au bloc de calcul.

Figure 5 : Exemple de déploiement ML Server
Les modèles créés sur HDInsight ou Databricks dépendent de l’environnement Spark (bibliothèques, fonctionnalités parallèles, etc.). Vous pouvez envisager de les exécuter sur un cluster. Vous trouverez des conseils ici. Ainsi, le modèle opérationnel peut lui-même être appelé par le biais d’une activité de pipeline Data Factory à des fins de scoring.
Pour utiliser des conteneurs, vous pouvez empaqueter vos modèles et les déployer sur Azure Kubernetes Service. Les prototypes nécessitent l’utilisation d’Azure Data Science VM. Vous devez également installer les outils en ligne de commande Azure ML sur la machine virtuelle.
Sortie des données et création de rapports
Une fois déployé, le modèle peut traiter les workflows des transactions financières et les relevés de stock pour générer des prédictions d’assortiment optimal. Les données ainsi produites peuvent être stockées dans Azure SQL Data Warehouse pour une analyse plus approfondie. En particulier, il est possible d’étudier l’historique des performances des différentes références SKU, de manière à identifier celles qui génèrent les chiffres d’affaires les plus élevés et celles qui sont source de perte. Vous pouvez alors comparer ces données aux assortiments qui sont suggérés par les modèles ainsi qu’évaluer les performances et la nécessité d’effectuer un nouvel entraînement.
Power BI permet d’analyser et d’afficher les données générées au cours du processus.
La figure ci-dessous présente un tableau de bord Power BI type. Elle inclut deux graphes qui affichent des informations sur les stocks des références SKU.
Considérations relatives à la sécurité
Une solution qui traite des données sensibles contient des données financières, des niveaux de stock et des informations de prix. Ces données sensibles doivent être protégées. Vous pouvez répondre aux préoccupations concernant la sécurité et la confidentialité des données des manières suivantes :
- Vous pouvez exécuter une partie du pipeline Azure Data Factory localement en utilisant Azure Integration Runtime. Le runtime exécute les activités de déplacement des données vers et depuis les sources locales. Il répartit également les activités afin qu’elles soient exécutées localement.
- Vous pouvez développer une activité personnalisée pour anonymiser les données à transférer vers Azure et l’exécuter localement.
- Tous les services mentionnés prennent en charge le chiffrement en transit et au repos. Si vous choisissez de stocker les données en utilisant Azure Data Lake, le chiffrement est activé par défaut. Si vous utilisez Azure SQL Data Warehouse, vous pouvez activer le chiffrement transparent des données (TDE).
- Tous les services mentionnés à l’exception de ML studio, prennent en charge l’intégration à Microsoft Entra ID pour l’authentification et l’autorisation. Si vous écrivez votre propre code, vous devez générer cette intégration à votre application.
Pour plus d’informations sur le Règlement général sur la protection des données (RGPD), règlement sur la protection et la confidentialité des données au sein l’Union européenne, consultez notre page de conformité.
Composants
Les technologies mentionnées dans cet article sont les suivantes :
- Azure Batch
- Microsoft Entra ID
- Azure Data Factory.
- HDInsight
- Databricks
- Machines virtuelles Data Science
- Azure Kubernetes Service
- Microsoft Power BI
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Scott Seely | Architecte logiciel
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
- Présentation d’Azure Data Factory
- Runtime d’intégration dans Azure Data Factory
- Qu’est-ce qu’un pool SQL dédié (anciennement SQL DW) dans Azure Synapse Analytics ?
- Microsoft Machine Learning Studio (classique)
- Qu’est-ce que Machine Learning Server ?
- Langage de modélisation de l’optimisation Pyomo
- Solveur Bonmin
- Solveur TFoCS pour Spark
Ressources associées
Conseils relatifs à la vente au détail :
- Solutions pour le secteur de la vente au détail
- Migrer votre solution e-commerce vers Azure
- Recherche visuelle dans le commerce de détail avec Azure Cosmos DB
Architectures connexes :