Importer vos données de formation dans Machine Learning Studio (classique) à partir de différentes sources de données
S’APPLIQUE À :  Machine Learning Studio (classique)
Machine Learning Studio (classique)  Azure Machine Learning
Azure Machine Learning
Important
Le support de Machine Learning Studio (classique) prend fin le 31 août 2024. Nous vous recommandons de passer à Azure Machine Learning avant cette date.
À partir du 1er décembre 2021, vous ne pourrez plus créer de nouvelles ressources Machine Learning Studio (classique). Jusqu’au 31 août 2024, vous pouvez continuer à utiliser les ressources Machine Learning Studio (classique) existantes.
- Consultez les informations sur le déplacement des projets de machine learning de ML Studio (classique) à Azure Machine Learning.
- En savoir plus sur Azure Machine Learning
La documentation ML Studio (classique) est en cours de retrait et ne sera probablement plus mise à jour.
Pour utiliser vos propres données dans Machine Learning Studio (classique) afin de développer et de tester une solution d’analyse prédictive, vous pouvez utiliser les données des ressources suivantes :
- Fichier local : chargez à l’avance les données locales à partir de votre disque dur pour créer un module de jeu de données dans votre espace de travail
- Sources de données en ligne : utilisez le module Importer les données pour accéder aux données à partir d’une des nombreuses sources en ligne pendant que votre expérience s’exécute
- Expérience Machine Learning Studio (classique) : utiliser les données qui ont été enregistrées en tant que jeu de données dans Machine Learning Studio (classique)
- Base de données SQL Server - Utiliser les données d’une base de données SQL Server sans avoir à copier les données manuellement
Remarque
Un certain nombre d’exemples de jeux de données sont disponibles dans Machine Learning Studio (classique) et vous pouvez les utiliser comme données de formation. Pour plus d’informations, consultez Utilisation des exemples de jeux de données dans Machine Learning Studio (classique).
Préparer les données
Machine Learning Studio (classique) est conçu pour travailler avec des données tabulaires ou rectangulaires, comme des données texte délimitées ou structurées à partir d’une base de données, bien que dans certains cas des données non rectangulaires puissent être utilisées.
Il est préférable que vos données soient relativement propres avant leur importation dans Studio (classique). Par exemple, vous souhaitez prendre en charge des problèmes tels que des chaînes sans guillemets.
Toutefois, des modules sont disponibles dans Studio (classique), qui permettent d’effectuer certaines manipulations de données dans votre expérience après importation de vos données. En fonction des algorithmes d’apprentissage automatique que vous allez utiliser, vous devrez décider comment gérer les problèmes structurels des données tels que des valeurs manquantes et des données fragmentées. Certains modules existent pour vous aider à régler ces problèmes. Rechercher dans la section Transformation des données de la palette des modules ceux qui exécutent ces fonctions.
À tout stade de votre expérience, vous pouvez voir ou télécharger les données générées par un module en cliquant sur le port de sortie. En fonction du module, différentes options de téléchargement peuvent être disponibles. Vous pouvez également afficher les données dans votre navigateur web dans Studio (classique).
Formats et types de données pris en charge
Vous pouvez importer un certain nombre de types de données dans votre expérience, selon le mécanisme que vous utilisez pour importer les données et l’emplacement d’où elles proviennent :
- Texte brut (.txt)
- Comma-separated values (CSV) avec un en-tête (.csv) ou sans (. nh.csv)
- Tab-separated values (TSV) avec un en-tête (.tsv) ou sans (. nh.tsv)
- Fichier Excel
- Table Azure
- Table hive
- Base de données SQL
- Valeurs OData
- Données SVMLight (.svmlight) (voir la définition SVMLight pour les informations relatives au format)
- Données Attribute Relation File Format (ARFF) (.arff) (voir la définition ARFF pour les informations relatives au format)
- Fichier zip (.zip)
- Fichier d’espace de travail ou d’objet R (.RData)
Si vous importez des données dans un format tel que ARFF qui inclut des métadonnées, Studio (classique) utilise celles-ci pour définir le titre et le type de données de chaque colonne.
Si vous importez des données dans des formats tels que TSV ou CSV qui n’incluent pas ces métadonnées, Studio (classique) déduit le type de données de chaque colonne en échantillonnant les données. Si les données n’ont pas non plus de titre de colonne, Studio (classique) fournit des noms par défaut.
Vous pouvez spécifier de manière explicite ou modifier les titres et les types de données pour les colonnes à l’aide du module Modifier les métadonnées.
Les types de données reconnus par Studio (classique) sont les suivants :
- Chaîne
- Integer
- Double
- Boolean
- Date/Heure
- TimeSpan
Studio utilise un type de données interne appelé table de données pour passer des données entre les modules. Vous pouvez convertir de manière explicite vos données dans un format de table de données à l’aide du module Convertir en jeu de données.
Tout module qui accepte des formats autres que la table de données convertit silencieusement les données en table de données avant de les passer au module suivant.
Au besoin, vous pouvez convertir à nouveau le format de table de données au format CSV, TSV, ARFF ou SVMLight à l’aide d’autres modules de conversion. Recherchez dans la section Conversion des formats de données de la palette des modules ceux qui exécutent ces fonctions.
Capacités des données
Les modules de Machine Learning Studio (classique) prennent en charge les jeux de données d’une taille maximale de 10 Go de données numériques denses pour les scénarios d’utilisation courants. Si un module accepte plusieurs entrées, le total de toutes les tailles d’entrée est de 10 Go. Vous pouvez échantillonner des jeux de données plus importants par le biais de requêtes Hive ou Azure SQL Database ou encore via un prétraitement Learning by Counts avant d'importer les données.
Les types de données suivants peuvent être développés en jeux de données plus importants au moment de la normalisation des fonctionnalités et ils sont limités à moins de 10 Go :
- Partiellement alloué
- Par catégorie
- Chaînes
- Données binaires
Les modules suivants sont limités à des jeux de données inférieurs à 10 Go :
- modules de recommandation
- Module SMOTE (Synthetic Minority Oversampling Technique)
- modules de script : R, Python, SQL
- Modules dont la taille des données de sortie peut être supérieure à la taille des données d’entrée, comme Join ou Feature Hashing
- Validation croisée, réglage des hyperparamètres de modèle, régression ordinale et plusieurs classes de un contre tous, lorsque le nombre d’itérations est très élevé
Pour les tailles de jeux de données supérieures à quelques gigaoctets, chargez les données sur Stockage Azure ou Azure SQL Database. Vous pouvez aussi utiliser Azure HDInsight au lieu d’effectuer un chargement directement à partir d’un fichier local.
Vous trouverez des informations sur les données d’image dans la référence du module Importer des Images.
Importer à partir d’un fichier local
Vous pouvez charger un fichier de données à partir de votre disque dur pour vous en servir comme données de formation dans Studio (classique). Lorsque vous importez un fichier de données, vous créez un module de jeu de données prêt à être utilisé dans des expériences au sein de votre espace de travail.
Pour importer des données à partir d’un disque dur local, procédez comme suit :
- Cliquez sur +NOUVEAU en bas de la fenêtre de Studio (classique).
- Sélectionnez JEU DE DONNÉES et DEPUIS UN FICHIER LOCAL.
- Dans la boîte de dialogue Télécharger un nouveau jeu de données , recherchez le fichier que vous souhaitez télécharger.
- Saisissez un nom, identifiez le type de données puis saisissez éventuellement une description. Une description est recommandée : elle vous permet d’enregistrer des caractéristiques relatives aux données que vous souhaitez mémoriser pour une utilisation future.
- La case à cocher Il s'agit de la nouvelle version d'un jeu de donnée existant vous permet de mettre à jour un jeu de données existant avec de nouvelles données. Pour ce faire, cliquez simplement sur cette case à cocher, puis saisissez le nom d’un jeu de données existant.
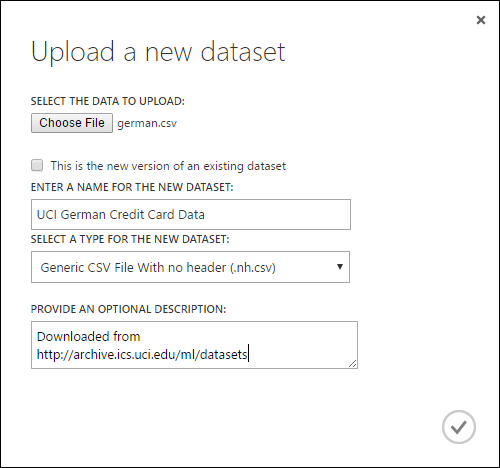
Le temps de téléchargement dépend de la taille de vos données et de la vitesse de votre connexion au service. Si vous savez que le téléchargement du fichier prendra du temps, vous pouvez faire autre chose dans Studio (classique) en attendant. Cependant, la fermeture du navigateur avant la fin du chargements entraîne l’échec de celui-ci.
Une fois que vos données sont téléchargées, elles sont stockées dans un module de jeu de données et sont disponibles pour n'importe quelle expérience dans votre espace de travail.
Quand vous éditez une expérimentation, les jeux de données que vous avez chargés apparaissent sous Mes jeux de données dans la liste Jeux de données enregistrés de la palette du module. Vous pouvez glisser-déplacer le jeu de données dans le canevas de l’expérience en vue d’affiner l’analyse et Machine Learning.
Importer à partir de sources de données en ligne
En utilisant le module Importer des données, votre expérience peut importer des données à partir de diverses sources en ligne en cours d’exécution.
Remarque
Cet article fournit des informations générales sur le module Importer les données. Pour plus d’informations sur les types de données auxquelles vous pouvez accéder, les formats, les paramètres et les réponses aux questions courantes, consultez la rubrique de référence pour le module Importer les données.
Le module Importer des données vous permet d’accéder aux données d’une des sources en ligne en cours d’expérience :
- Une URL web avec HTTP
- Hadoop avec HiveQL
- Stockage Blob Azure
- Table Azure
- Azure SQL Database. SQL Managed Instance ou SQL Server
- Un fournisseur de flux de données, actuellement, OData
- Azure Cosmos DB
Ces données d’apprentissage étant chargées en cours d’expérience, elles ne sont disponibles que dans le cadre de celle-ci. En revanche, des données stockées dans un module de jeu de données sont disponibles pour toute expérience au sein de votre espace de travail.
Pour accéder à des sources de données en ligne dans votre expérience Studio (classique), ajoutez le module Importer des données module à votre expérience. Sélectionnez ensuite Lancer l’Assistant Importation de données sous Propriétés afin d’obtenir des instructions pas à pas pour sélectionner et configurer la source de données. Vous pouvez également sélectionner manuellement une source de données sous Propriétés et fournir les paramètres nécessaires pour accéder aux données.
Les sources de données en ligne prises en charge sont détaillées dans le tableau ci-dessous. Ce tableau récapitule également les formats de fichier pris en charge et les paramètres qui sont utilisés pour accéder aux données.
Important
Actuellement, les modules Importer les données et Exporter les données peuvent lire et écrire des données uniquement à partir d’un stockage Azure créé à l’aide du modèle de déploiement classique. En d’autres termes, le nouveau type de compte de stockage d’objets blob Azure qui offre un niveau d’accès au stockage chaud ou un niveau d’accès au stockage froid n’est pas encore pris en charge.
En règle générale, les comptes de stockage Azure que vous avez peut-être créés avant que cette option de service ne soit disponible ne devraient pas être affectés. Si vous avez besoin de créer un nouveau compte, sélectionnez Classique comme modèle de déploiement, ou utilisez Resource Manager et, comme Type de compte, sélectionnez Usage général plutôt que Stockage Blob.
Pour plus d’informations, consultez Stockage des objets blob Azure : niveaux de stockage chauds et froids.
Sources de données en ligne prises en charge
Le module Importer les données de Machine Learning Studio (classique) prend en charge les sources de données suivantes :
| Source de données | Description | Paramètres |
|---|---|---|
| URL web via HTTP | Lit les données au format CSV (valeurs séparées par des virgules), TSV (valeurs séparées par des tabulations), ARFF (format de fichier de relation d’attribut) et SVM-light (Machines vectorielles (SVM clair)), à partir de n’importe quelle URL web qui utilise le protocole HTTP | URL : indique le nom complet du fichier, notamment l'URL du site et le nom de fichier, avec n'importe quelle extension. Format de données : spécifie un des formats de données pris en charge : CSV, TSV, ARFF ou SVM-light. Lorsque les données ont une ligne d’en-tête, elle est utilisée pour attribuer des noms de colonne. |
| Hadoop/HDFS | Lit les données à partir d’un stockage distribué dans Hadoop. Spécifiez les données souhaitées à l’aide de HiveQL, langage de requête de type SQL. Vous pouvez également utiliser HiveQL pour agréger et effectuer un filtrage des données avant d’ajouter les données à Studio (classique). | Requête de base de données Hive : spécifie la requête Hive utilisée pour générer les données. URI du serveur HCatalog : spécifie le nom de votre cluster en utilisant le format <nom de votre cluster>. azurehdinsight.net. Nom du compte utilisateur Hadoop : spécifie le nom du compte utilisateur Hadoop utilisé pour configurer le cluster. Mot de passe du compte utilisateur Hadoop : spécifie les informations d’identification utilisées lors de la configuration du cluster. Pour plus d’informations, consultez Création de clusters Hadoop dans HDInsight. Emplacement des données de sortie : indique si les données sont stockées dans un système de fichiers distribué Hadoop (HDFS) ou dans Azure.
Si vous stockez vos données de sortie dans Azure, vous devez spécifier le nom du compte de stockage Azure, la clé d’accès au stockage et le nom du conteneur de stockage. |
| Base de données SQL | Lit les données stockées dans Azure SQL Database, SQL Managed Instance ou dans une base de données SQL Server s’exécutant sur une machine virtuelle Azure. | Nom du serveur de base de données : spécifie le nom du serveur sur lequel la base de données s’exécute.
Dans le cas d’un serveur SQL hébergé sur une machine virtuelle Azure, entrez tcp:<Virtual Machine DNS Name>, 1433 Nom de la base de données : spécifie le nom de la base de données sur le serveur. Nom du compte utilisateur du serveur : spécifie un nom d’utilisateur pour un compte disposant des autorisations d’accès à la base de données. Mot de passe du compte utilisateur du serveur : spécifie le mot de passe du compte utilisateur. Requête de base de données : entrez une instruction SQL qui décrit les données que vous souhaitez lire. |
| Base de données SQL locale | Lit les données stockées dans une base de données SQL. | Passerelle de données : spécifie le nom de la passerelle de gestion de données installée sur un ordinateur à partir duquel elle peut accéder à votre base de données SQL Server. Pour plus d’informations sur la configuration de la passerelle, consultez Exécuter une analytique avancée avec Machine Learning Studio (classique) en utilisant les données d’un serveur SQL. Nom du serveur de base de données : spécifie le nom du serveur sur lequel la base de données s’exécute. Nom de la base de données : spécifie le nom de la base de données sur le serveur. Nom du compte utilisateur du serveur : spécifie un nom d’utilisateur pour un compte disposant des autorisations d’accès à la base de données. Nom d’utilisateur et mot de passe : cliquez sur Entrer les valeurs pour saisir les informations d’identification de votre base de données. Vous pouvez utiliser l'Authentification Windows intégrée ou l'Authentification SQL Server en fonction de la configuration de votre instance de SQL Server. Requête de base de données : entrez une instruction SQL qui décrit les données que vous souhaitez lire. |
| table Azure | Lit les données du service de tableau dans le stockage Azure. Si vous lisez rarement de grandes quantités de données, utilisez le Service de Tableau Azure. Il fournit une solution de stockage ultra disponible, flexible, non relationnelle (NoSQL), économique et hautement évolutive. |
Les options du module Importer les données changent selon que vous accédez à des informations publiques ou à un compte de stockage privé qui nécessite des informations d’identification de connexion. Cela est déterminé par le Type d'authentification qui peut avoir la valeur « PublicOrSAS » ou « Compte », chacun d'entre eux possède son propre ensemble de paramètres. URI de signature d’accès partagé (SAP) ou public : les paramètres sont :
Spécifier les lignes à balayer pour les noms de propriété : les valeurs sont TopN pour analyser le nombre spécifié de lignes ou ScanAll pour obtenir toutes les lignes de la table. Si les données sont homogènes et prévisibles, nous vous recommandons de sélectionner TopN et d’entrer un chiffre pour N. Pour les tables volumineuses, ceci peut accélérer les temps de lecture. Si les données sont structurées avec des ensembles de propriétés qui varient en fonction de la profondeur et la position de la table, choisissez l’option ScanAll pour analyser toutes les lignes. Cela garantit l’intégrité de la propriété obtenue et de la conversion des métadonnées.
Clé du compte : spécifie la clé de stockage associée au compte. Nom de la table : spécifie le nom de la table contenant les données à lire. Lignes à balayer pour les noms de propriété : les valeurs sont TopN pour analyser le nombre spécifié de lignes ou ScanAll pour obtenir toutes les lignes de la table. Si les données sont homogènes et prévisibles, nous vous recommandons de sélectionner TopN et d’entrer un chiffre pour N. Pour les tables volumineuses, ceci peut accélérer les temps de lecture. Si les données sont structurées avec des ensembles de propriétés qui varient en fonction de la profondeur et la position de la table, choisissez l’option ScanAll pour analyser toutes les lignes. Cela garantit l’intégrité de la propriété obtenue et de la conversion des métadonnées. |
| Stockage Blob Azure | Lit les données stockées dans le service d'objet Blob dans le stockage Azure, notamment les images, le texte non structuré ou les données binaires. Vous pouvez utiliser le service Blob pour exposer publiquement des données ou pour stocker en privé des données d'application. Vous pouvez accéder à vos données depuis n’importe où grâce à des connexions HTTP ou HTTPS. |
Les options du module Importer les données changent selon que vous accédez à des informations publiques ou à un compte de stockage privé qui nécessite des informations d’identification de connexion. Cela est déterminé par le Type d’authentification qui peut avoir la valeur « PublicOrSAS » ou « Compte ». URI de signature d’accès partagé (SAP) ou public : les paramètres sont :
Format du fichier : spécifie le format des données dans le service Blob. Les formats pris en charge sont CSV, TSV et ARFF.
Clé du compte : spécifie la clé de stockage associée au compte. Chemin d’accès au conteneur, répertoire ou Blob : spécifie le nom de l’objet Blob contenant les données à lire. Format du fichier Blob : spécifie le format des données dans le service Blob. Les formats de données pris en charge sont CSV, TSV, ARFF, CSV avec un codage spécifié et Excel.
Vous pouvez utiliser l'option Excel pour lire des données à partir de classeurs Excel. Dans l'option format de données Excel, indiquez si les données se trouvent dans une plage de feuille de calcul Excel ou un tableau Excel. Dans l’option Feuille de calcul Excel ou table intégrée, spécifiez le nom de la feuille ou table à lire. |
| Fournisseur de flux de données | Lit les données d’un fournisseur de flux pris en charge. Actuellement, seul le protocole Open Data Protocol (OData) est pris en charge. | Type de contenu de données : spécifie le format OData. URL source : spécifie l’URL complète du flux de données. Par exemple, l’URL suivante lit dans l’exemple de base de données Northwind : https://services.odata.org/northwind/northwind.svc/ |
Importer à partir d’une autre expérience
Il se peut que vous ayez parfois besoin d’obtenir un résultat intermédiaire à partir d’une expérience et de l’utiliser dans le cadre d’une autre expérience. Pour ce faire, vous enregistrez le module en tant que jeu de données :
- Cliquez sur la sortie du module que vous souhaitez enregistrer en tant que jeu de données.
- Cliquez sur Enregistrer comme jeu de données.
- Lorsque vous y êtes invité, saisissez un nom et une description qui vous permet d'identifier facilement le jeu de données.
- Cliquez sur la coche OK .
Lorsque l'enregistrement est terminé, le jeu de données sera disponible pour être utilisé dans n'importe quelle expérience dans votre espace de travail. Vous pouvez le trouver dans la liste Jeux de données enregistrés dans la palette des modules.