Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Remarque
Il existe une nouvelle version du scanneur de protection des informations. Pour plus d’informations, consultez Mettre à niveau le scanneur Protection des données Microsoft Purview.
Utilisez les informations de cette section pour en savoir plus sur le scanneur Protection des données Microsoft Purview, puis sur la façon d’installer, de configurer, d’exécuter et, si nécessaire, de le résoudre.
Ce scanneur s’exécute en tant que service sur Windows Server et vous permet de découvrir, de classifier et de protéger des fichiers sur les magasins de données suivants :
Chemins UNC pour les partages réseau qui utilisent les protocoles SMB ou NFS (préversion).
Bibliothèques de documents SharePoint et dossier pour SharePoint Server (versions actuellement en support étendu). Pour plus d’informations, consultez la stratégie de support sharePoint Server mise à jour de la stratégie de maintenance des produits pour SharePoint Server SE.
Pour classifier et protéger vos fichiers, le scanneur utilise des étiquettes de confidentialité configurées dans le portail Microsoft Purview.
Vue d’ensemble du scanneur
L’analyseur de protection des informations peut inspecter tous les fichiers que Windows peut indexer. Si vous configurez des étiquettes de confidentialité pour appliquer la classification automatique, le scanneur peut étiqueter les fichiers découverts pour appliquer cette classification et éventuellement appliquer ou supprimer la protection. Pour plus d’informations sur les types d’informations sensibles (SIT) pris en charge par le scanneur de protection des informations, consultez Types d’informations sensibles pris en charge par Protection des données Microsoft Purview scanneur.
L’image suivante montre l’architecture du scanneur, où le scanneur découvre des fichiers sur vos serveurs locaux et SharePoint.
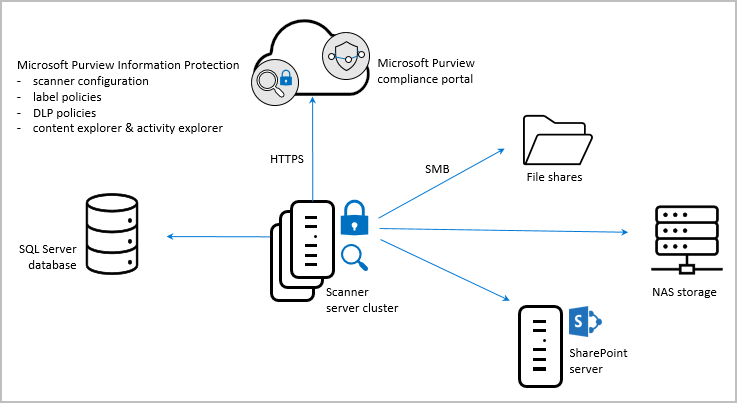
Pour inspecter vos fichiers, le scanneur utilise des IFilters installés sur l’ordinateur. Pour déterminer si les fichiers doivent être étiquetés, le scanneur utilise des types d’informations sensibles et la détection de modèles, ou des modèles d’expression régulière.
Le scanneur utilise le client Protection des données Microsoft Purview et peut classifier et protéger les mêmes types de fichiers que le client. Pour plus d’informations, consultez Types de fichiers pris en charge.
Effectuez l’une des opérations suivantes pour configurer vos analyses en fonction des besoins :
- Exécutez le scanneur en mode découverte uniquement pour créer des rapports qui case activée pour voir ce qui se passe lorsque vos fichiers sont étiquetés.
- Exécutez le scanneur pour découvrir les fichiers contenant des informations sensibles, sans configurer d’étiquettes qui appliquent la classification automatique.
- Exécutez le scanneur automatiquement pour appliquer des étiquettes comme configuré.
- Définissez une liste de types de fichiers pour spécifier des fichiers spécifiques à analyser ou à exclure.
Remarque
Le scanneur ne détecte pas et n’étiquet pas en temps réel. Il analyse systématiquement les fichiers sur les magasins de données que vous spécifiez. Configurez ce cycle pour qu’il s’exécute une seule fois ou plusieurs fois.
Conseil
Le scanneur prend en charge les clusters d’analyseur avec plusieurs nœuds, ce qui permet à votre organization de monter en puissance, ce qui permet d’obtenir des temps d’analyse plus rapides et une portée plus large.
Déployez plusieurs nœuds dès le début, ou commencez avec un cluster à nœud unique et ajoutez des nœuds supplémentaires ultérieurement au fur et à mesure de votre croissance. Déployez plusieurs nœuds en utilisant le même nom de cluster et la même base de données pour l’applet de commande Install-Scanner .
Le processus d’analyse
Lors de l’analyse des fichiers, l’analyseur de protection des informations effectue les étapes suivantes :
1. Déterminez si les fichiers sont inclus ou exclus pour analyse.
2. Inspecter et étiqueter les fichiers.
3. Étiqueter les fichiers qui ne peuvent pas être inspectés.
Pour plus d’informations, consultez Files pas étiquetés par le scanneur.
1. Déterminer si les fichiers sont inclus ou exclus pour l’analyse
Le scanneur ignore automatiquement les fichiers exclus de la classification et de la protection, tels que les fichiers exécutables et les fichiers système. Pour plus d’informations, consultez Types de fichiers exclus.
Le scanneur prend également en compte toutes les listes de fichiers explicitement définies pour analyser ou exclure de l’analyse. Les listes de fichiers s’appliquent par défaut à tous les référentiels de données et peuvent également être définies pour des dépôts spécifiques uniquement.
Pour définir des listes de fichiers à des fins d’analyse ou d’exclusion, utilisez le paramètre Types de fichiers à analyser dans le travail d’analyse de contenu. Par exemple :

Pour plus d’informations, consultez Déploiement du scanneur pour classifier et protéger automatiquement des fichiers.
2. Inspecter et étiqueter les fichiers
Après avoir identifié les fichiers exclus, l’analyseur de protection des informations filtre à nouveau pour identifier les fichiers pris en charge pour l’inspection.
Ces filtres sont les mêmes que ceux utilisés par le système d’exploitation pour la recherche et l’indexation Windows, et ne nécessitent aucune configuration supplémentaire. Windows IFilter est également utilisé pour analyser les types de fichiers utilisés par Word, Excel et PowerPoint, ainsi que pour les documents PDF et les fichiers texte.
Pour obtenir la liste complète des types de fichiers pris en charge pour l’inspection et d’autres instructions de configuration des filtres pour inclure des fichiers .zip et .tiff, consultez Types de fichiers pris en charge pour l’inspection.
Après inspection, les types de fichiers pris en charge sont étiquetés à l’aide des conditions spécifiées pour vos étiquettes. Si vous utilisez le mode de découverte, ces fichiers peuvent contenir les conditions spécifiées pour vos étiquettes ou contenir des types d’informations sensibles connus.
Processus du scanneur arrêtés
Si le scanneur s’arrête avant de terminer l’analyse d’un grand nombre de fichiers dans votre dépôt, vous devrez peut-être augmenter le nombre de ports dynamiques pour le système d’exploitation qui héberge les fichiers.
Par exemple, le renforcement du serveur pour SharePoint est l’une des raisons pour lesquelles le scanneur dépasse le nombre de connexions réseau autorisées et s’arrête donc.
Pour case activée si le renforcement du serveur pour SharePoint est la cause de l’arrêt du scanneur, case activée pour le message d’erreur suivant dans les journaux du scanneur à l’adresse %localappdata %\Microsoft\MSIP\Logs\MSIPScanner.iplog (plusieurs journaux sont compressés dans un fichier zip) :
Unable to connect to the remote server ---> System.Net.Sockets.SocketException: Only one usage of each socket address (protocol/network address/port) is normally permitted IP:port
Pour plus d’informations sur la façon d’afficher la plage de ports actuelle et de l’augmenter si nécessaire, consultez Paramètres qui peuvent être modifiés pour améliorer les performances réseau.
Conseil
Pour les batteries de serveurs SharePoint volumineuses, vous devrez peut-être augmenter le seuil d’affichage de liste, qui a une valeur par défaut de 5 000.
Pour plus d’informations, voir Gérer les grandes listes et bibliothèques dans SharePoint.
3. Étiqueter les fichiers qui ne peuvent pas être inspectés
Pour tous les types de fichiers qui ne peuvent pas être inspectés, le scanneur applique l’étiquette par défaut à partir de sa stratégie d’étiquette de confidentialité ou de l’étiquette par défaut configurée pour le scanneur.
Files pas étiqueté par le scanneur
Le scanneur ne peut pas étiqueter les fichiers dans les circonstances suivantes :
Lorsque le type de fichier ne prend pas en charge l’étiquetage sans chiffrement. Pour obtenir la liste des types de fichiers pris en charge pour cette configuration d’étiquette, consultez Étiquettes de confidentialité sans chiffrement.
Lorsque l’étiquette applique le chiffrement, mais que le scanneur ne prend pas en charge le type de fichier.
Par défaut, le scanneur chiffre uniquement les types de fichiers Office et les fichiers PDF lorsqu’ils sont protégés à l’aide de la norme ISO pour le chiffrement PDF.
D’autres types de fichiers peuvent être ajoutés pour le chiffrement lorsque vous modifiez les types de fichiers à protéger.
Exemple : après avoir inspecté .txt fichiers, le scanneur ne peut pas appliquer une étiquette qui n’applique pas de chiffrement, car le type de fichier .txt ne prend pas en charge les étiquettes de confidentialité sans chiffrement.
Toutefois, si l’étiquette est configurée pour appliquer le chiffrement et que le type de fichier .txt est inclus pour le scanneur à protéger, le scanneur peut étiqueter le fichier.
Étapes suivantes
Pour plus d’informations sur le déploiement du scanneur, consultez les articles suivants :
- Prérequis pour le déploiement du scanneur
- Configuration et installation du scanneur
- Exécution d’analyses à l’aide du scanneur
Vous pouvez également utiliser PowerShell pour classifier et protéger de manière interactive les fichiers de votre ordinateur de bureau. Pour plus d’informations sur ce scénario et sur d’autres scénarios qui utilisent PowerShell, consultez Configurer le client de protection des informations à l’aide de PowerShell.