Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
En tant que solution de réplication de données, la mise en miroir dans Fabric est une solution à faible coût et à faible latence pour regrouper les données de différents systèmes dans une seule plateforme d’analytique. Vous pouvez répliquer en continu votre patrimoine de données existant directement dans OneLake de Fabric, y compris les données de Azure SQL Database, Azure Cosmos DB et Snowflake.
La mise en miroir dans Fabric permet aux utilisateurs de profiter d’un produit de bout en bout conçu pour simplifier vos besoins d’analyse. La mise en miroir est une solution à faible coût et à faible latence qui vous permet de créer un réplica de vos données dans OneLake, ce qui le rend facilement disponible pour tous vos besoins analytiques. Pour plus d’informations sur la mise en miroir d’infrastructure , consultez la documentation Fabric.
Configurer la qualité des données pour une base de données mise en miroir Fabric
Activez la mise en miroir dans votre locataire Fabric. Les administrateurs Power BI peuvent activer ou désactiver la mise en miroir pour l’ensemble du organization ou pour des groupes de sécurité spécifiques, à l’aide du paramètre disponible dans le portail d’administration Power BI. La mise en miroir est activée en créant une connexion sécurisée à votre source de données opérationnelle. Vous choisissez de répliquer une base de données entière ou des tables individuelles, et la mise en miroir maintient automatiquement vos données synchronisées. Une fois configurées, les données sont répliquées en continu dans OneLake pour une consommation analytique.
Une fois la mise en miroir activée et la réplication lancée, vérifiez que la réplication de la mise en miroir se termine correctement.
Ouvrez le point de terminaison d’analyse SQL.
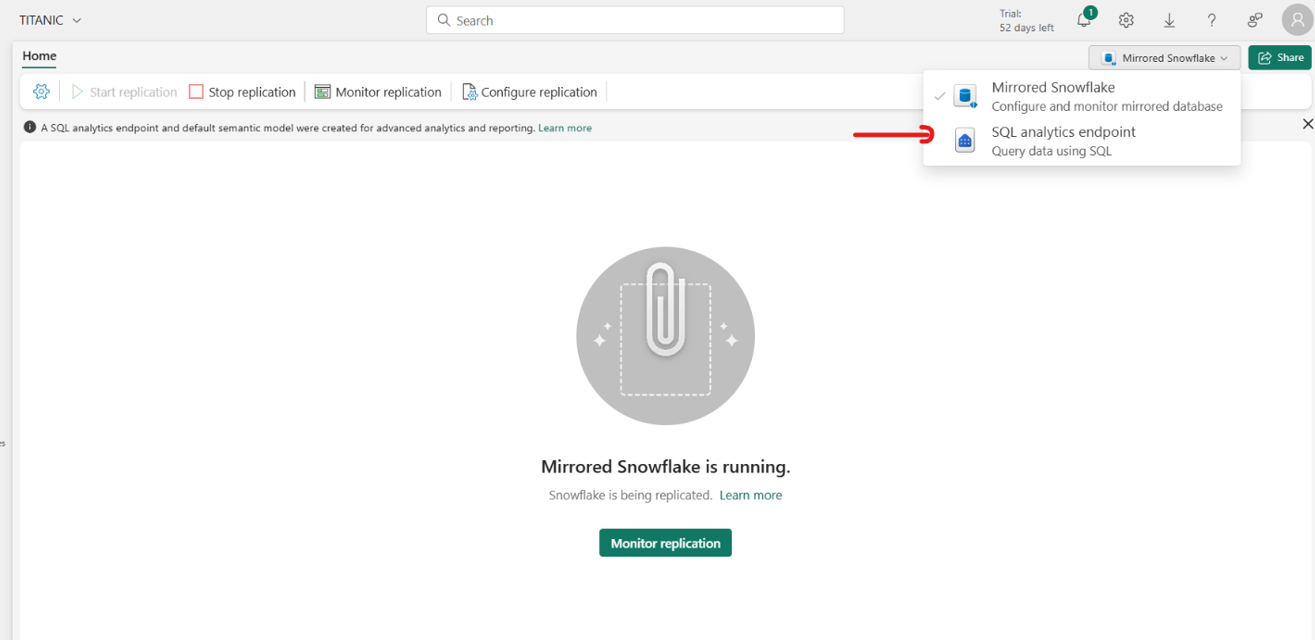
Sous l’onglet Création de rapports , sélectionnez Mettre à jour automatiquement le modèle sémantique.
Créez un Lakehouse dans votre espace de travail Fabric si vous n’en avez pas créé un.
Créez un raccourci Fabric de cette base de données mise en miroir vers lakehouse.
Accédez à Mappage de données Microsoft Purview et exécutez une analyse data map sur ce lakehouse ; ignorez la base de données mise en miroir. Utilisez l’authentification du principal de service.
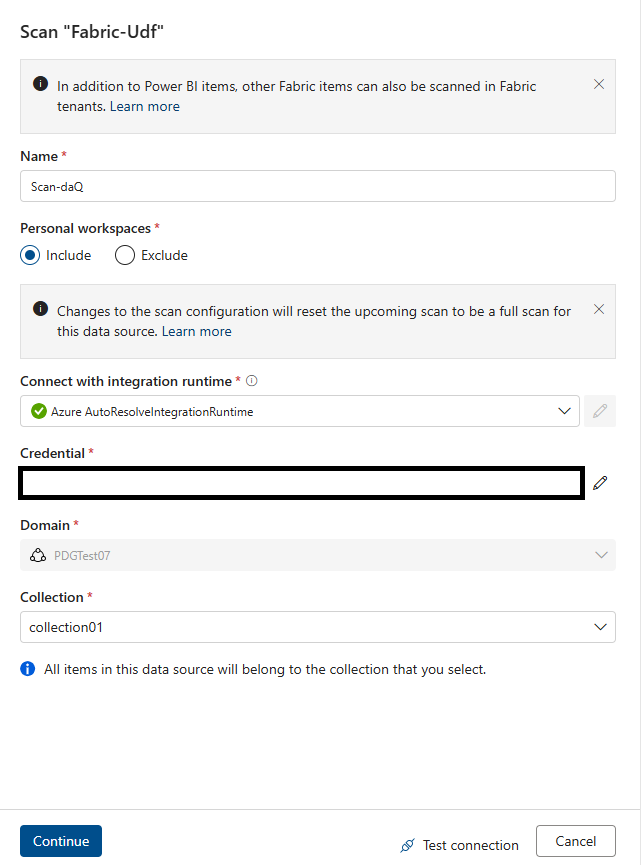
Une fois l’analyse terminée, associez les nouvelles ressources de données (tables Lakehouse) à un produit de données. Veillez à sélectionner les tables Lakehouse à associer à votre produit de données.
Après avoir associé des tables mises en miroir en tant que tables Lakehouse au produit de données, vous pouvez profiler et mesurer la qualité des données de toutes les tables mises en miroir en tant que tables Lakehouse dans Microsoft Purview.
Dans la zone Qualité des données de la gestion heath dans Catalogue unifié, exécutez une analyse de la qualité des données ou profilez vos données comme d’habitude.


Importante
- Utilisez le principal de service pour les analyses de mappage de données et utilisez une identité managée pour les analyses de qualité des données.
- Sélectionnez la base de données mise en miroir au lieu de tables individuelles.
- Mettez à jour le modèle sémantique chaque fois que vous ajoutez une nouvelle table à la base de données mise en miroir.
- Si vos tables de base de données mises en miroir ne sont pas disponibles dans Fabric Lakehouse, contactez le support fabric.
- L’analyse de la qualité des données est prise en charge uniquement pour les formats de fichiers Delta, Iceberg et Parquet Lakehouse.