Informations de référence sur l’API REST Recherche Azure AI
azure AI Search (anciennement Recherche cognitive Azure) est un service de recherche cloud entièrement managé qui fournit une récupération d’informations sur le contenu appartenant à l’utilisateur.
Les API REST du plan de données sont utilisées pour l’indexation et les workflows de requête, et sont documentées dans cette section.
Les opérations de plan de contrôle pour l’administration de service sont couvertes dans un
Documentation de l’API avec version
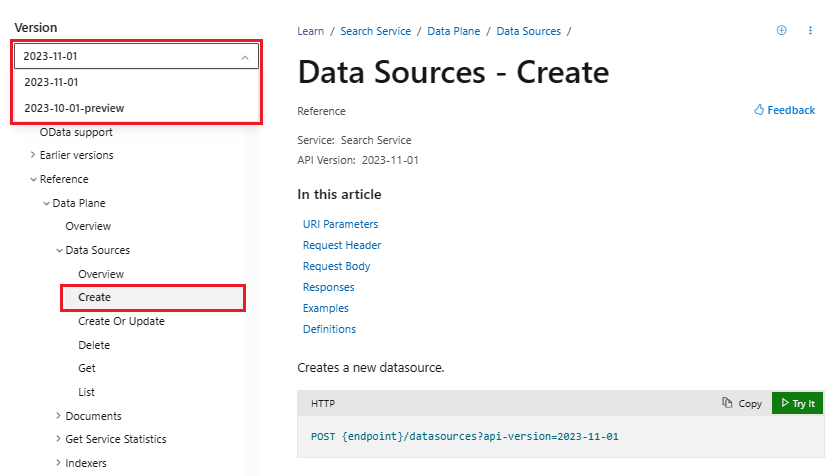
Les documents de l’API REST sont désormais versionnés. Lorsque vous ouvrez une page de référence d’API, un sélecteur de version apparaît au-dessus de la table des matières. Vérifiez que la référence de l’API provient du dossier Reference > Data Plane.
Concepts clés
Azure AI Search présente les concepts des services de recherche , des index , des documents , des indexeurs , des sources de données , des ensembles de compétences et des mappages de synonymes .
- Un service de recherche héberge des index, des indexeurs, des sources de données, des ensembles de compétences et des mappages de synonymes en tant qu’objets de niveau supérieur.
- Un index de recherche fournit un stockage persistant des documents de recherche. Les documents de recherche sont vos données, articulées sous la forme d’une collection de champs, chargées à partir de sources externes et envoyées à un index pour le rendre accessible à la recherche.
- Un indexeur de recherche ajoute l’automatisation, la lecture des données dans des formats natifs et sa sérialisation en JSON.
- Un indexeur a une source de données et pointe vers un index.
- Un indexeur peut également avoir un ensemble de compétences qui ajoute 'enrichissement par IA et de vectorisation intégrée au pipeline d’indexation. Les ensembles de compétences sont toujours attachés à un indexeur. Ils appellent le Machine Learning pour extraire ou segmenter du texte, vectoriser du contenu, déduire des fonctionnalités ou ajouter une structure au contenu pour améliorer l’indexation par un service de recherche.
Au total, vous pouvez créer les objets suivants sur un service de recherche :
| Objets | Description |
|---|---|
| Sources de données | Connexion de source de données utilisée par un indexeur pour récupérer et actualiser des documents pour l’indexation. Les sources de données ont un type. Vous pouvez utiliser les connexions fournies par Microsoft pour Azure ou les connecteurs partenaires. Consultez galerie de sources de données pour obtenir la liste complète. |
| Documents | Conceptuellement, un document est une entité dans votre index. Mappage de ce concept à des équivalents de base de données plus familiers : un index de recherche équivaut à une table et les documents sont à peu près équivalents aux lignes d’une table. Les documents existent uniquement dans un index et sont récupérés uniquement par le biais de requêtes qui ciblent la collection de documents (/docs) d’un index. Toutes les opérations effectuées sur la collection, telles que le chargement, la fusion, la suppression ou l’interrogation de documents ont lieu dans le contexte d’un index unique, de sorte que les opérations de document au format URL incluent toujours /indexes/[index name]/docs pour un nom d’index donné. |
| Index | Un index est stocké sur votre service de recherche et rempli avec des documents JSON indexés et tokenisés pour la récupération d’informations. La collection de champs d’un index définit la structure du document de recherche. Les champs ont un nom, des types de données et des attributs qui déterminent l’utilisation. Par exemple, searchable champs sont utilisés dans la recherche en texte intégral, et par conséquent tokenisés pendant l’indexation. Un index définit également d’autres constructions, telles que des profils de scoring pour le réglage de pertinence, les suggesteurs, les configurations sémantiques et les analyseurs personnalisés. |
| Indexeurs | Les indexeurs fournissent une automatisation de l’indexation. Un indexeur se connecte à une source de données, lit dans les données et le transmet à un moteur de recherche pour l’indexation dans un index de recherche cible. Les indexeurs lisent à partir d’une source externe à l’aide d’informations de connexion dans une source de données et sérialisent les données entrantes dans des documents de recherche JSON. En plus d’une source de données, un indexeur nécessite également un index. L’index spécifie les champs et attributs des documents de recherche. |
| Ensembles de compétences | Un ensemble de compétences ajoute des étapes de traitement externes à l’exécution de l’indexeur et est utilisé pour appliquer des modèles IA ou Deep Learning pour analyser ou transformer du contenu pour améliorer la recherche dans un index. Le contenu d’un ensemble de compétences est un ou plusieurs compétences, qui peuvent être compétences intégrées créées par Microsoft, des compétences personnalisées ou une combinaison des deux. Les compétences intégrées existent pour l’analyse d’images, y compris l’OCR et le traitement du langage naturel. D’autres exemples de compétences intégrées incluent la reconnaissance d’entité, l’extraction d’expressions clés, la segmentation de texte dans des pages logiques, entre autres. Un ensemble de compétences est un objet autonome de haut niveau qui existe sur un niveau équivalent aux index, indexeurs et sources de données, mais il est opérationnel uniquement dans le traitement de l’indexeur. En tant qu’objet de haut niveau, vous pouvez concevoir un ensemble de compétences une seule fois, puis le référencer dans plusieurs indexeurs. |
| Mappages de synonymes | Une carte de synonymes est un objet de niveau service qui contient des synonymes définis par l’utilisateur. Cet objet est géré indépendamment des index de recherche. Une fois chargé, vous pouvez pointer n’importe quel champ pouvant faire l’objet d’une recherche vers la carte de synonymes (un par champ). |
Autorisations et contrôle d’accès
Vous pouvez utiliser l’authentification basée sur des clés ou un rôle par le biais de l’ID Microsoft Entra.
l’authentification par clé s’appuie sur des clés API générées pour le service de recherche. La présence d’une clé valide établit l’approbation, par requête, entre l’application qui envoie la demande et le service qui le gère. Vous pouvez utiliser une clé API d’administration pour les opérations en lecture-écriture ou une clé API de requête pour l’accès en lecture à la collection de documents d’un index de recherche.
l’authentification d’ID Microsoft Entra et le contrôle d’accès en fonction du rôle nécessite que vous ayez un locataire établi dans Microsoft Entra ID, avec des principaux de sécurité et des attributions de rôles. Les membres des rôles suivants ont accès au plan de données. Vous pouvez créer des rôles personnalisés si les rôles intégrés sont insuffisants.
Rôle Accès Contributeur de service de recherche Accès aux objets, mais aucun accès au contenu d’index. Ce rôle crée un index de recherche et d’autres objets de niveau supérieur, mais ne peut pas interroger un index de recherche ou ajouter, supprimer ou mettre à jour des documents dans un index de recherche. Ce rôle est destiné aux développeurs qui créent, mettent à jour et suppriment des définitions d’objets. Il s’agit également pour les administrateurs qui doivent gérer des objets, mais sans avoir la possibilité d’afficher ou d’accéder aux données d’objet. Contributeur d’index de données de recherche Accès en lecture-écriture au contenu d’index. Ce rôle est destiné aux développeurs ou aux propriétaires d’index qui doivent importer, actualiser ou interroger la collection de documents d’un index. Lecteur d’index de données de recherche Accès en lecture au contenu d’index. Ce rôle est destiné aux applications et aux utilisateurs qui exécutent des requêtes.
Lorsque vous utilisez des rôles sur la connexion, votre application cliente présente un jeton du porteur dans l’en-tête d’autorisation. Consultez Autoriser l’accès à une application de recherche à l’aide de Microsoft Entra ID pour obtenir de l’aide sur la configuration.
Vous pouvez désactiver l’authentification basée sur des clés ou l’authentification basée sur des rôles. Si vous désactivez l’authentification basée sur des rôles, elle s’applique uniquement aux opérations de plan de données. Les opérations de plan de contrôle, telles que l’administration de service, utilisent toujours l’authentification basée sur les rôles. Pour plus d’informations, consultez l’authentification Microsoft Entra ID et le contrôle d’accès en fonction du rôle pour Azure AI Search.
Appel des API
Les API documentées dans cette section fournissent l’accès aux opérations sur les données de recherche, telles que la création d’index et la population, le chargement de documents et les requêtes. Lorsque vous appelez des API, gardez à l’esprit les points suivants :
Les demandes doivent être émises via HTTPS (sur le port par défaut 443).
Les URI de requête doivent inclure le
api version . La valeur doit être définie sur une version prise en charge, mise en forme comme indiqué dans cet exemple : GET https://[search service name].search.windows.net/indexes?api-version=2023-11-01les en-têtes de requête doivent inclure un de clé APIou un jeton du porteur pour les connexions authentifiées. Si vous le souhaitez, vous pouvez définir l’en-tête Accept HTTP. Si l’en-tête de type de contenu n’est pas défini, la valeur par défaut est supposée être application/json.