Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Dans Recherche Azure AI, l’enrichissement par IA désigne l’intégration à Azure AI services pour traiter du contenu qui ne peut pas faire l’objet de recherches dans sa forme brute. Grâce à l’enrichissement, l’analyse et l’inférence sont utilisées pour créer un contenu et une structure q pouvant faire l’objet d’une recherche là où il n’y en avait pas auparavant.
Étant donné que Recherche Azure AI est utilisé pour les requêtes de texte et de vecteur, l’objectif de l’enrichissement par IA est d’améliorer l’utilité de votre contenu dans les scénarios de recherche. Le contenu brut doit être du texte ou des images (vous ne pouvez pas enrichir de vecteurs), mais la sortie d’un pipeline d’enrichissement peut être vectorisée et indexée dans un index de recherche à l’aide de compétences telles que la compétence Fractionnement de texte pour la segmentation et la compétence AzureOpenAIEmbedding pour l’encodage vectoriel. Pour plus d’informations sur l’utilisation des compétences dans les scénarios vectoriels, consultez Segmentation et incorporation de données intégrées.
L’enrichissement par IA est basé sur des compétences.
Les compétences intégrées tirent parti d’Azure AI services. Elles appliquent les transformations et le traitement suivants au contenu brut :
- Traduction et détection de la langues pour la recherche multilingue
- Reconnaissance d’entité pour extraire les noms de personnes, les lieux et autres entités à partir de gros blocs de texte
- Extraction de phrases clés pour identifier et générer des termes importants
- Reconnaissance optique de caractères (OCR) pour reconnaître le texte imprimé et manuscrit dans les fichiers binaires
- Analyse d’image pour décrire le contenu d’images et générer des descriptions sous forme de champs de texte pouvant faire l’objet d’une recherche
Les compétences personnalisées exécutent votre code externe. Les compétences personnalisées peuvent être utilisées pour tout traitement personnalisé que vous souhaitez inclure dans le pipeline.
L’enrichissement par IA est une extension d’un pipeline d’indexeur qui se connecte aux sources de données Azure. Un pipeline d’enrichissement contient tous les composants d’un indexeur de pipeline (indexeur, source de données, index), ainsi qu’un ensemble de compétences qui spécifie les étapes d’enrichissement atomique.
Le diagramme suivant illustre la progression de l’enrichissement par IA :
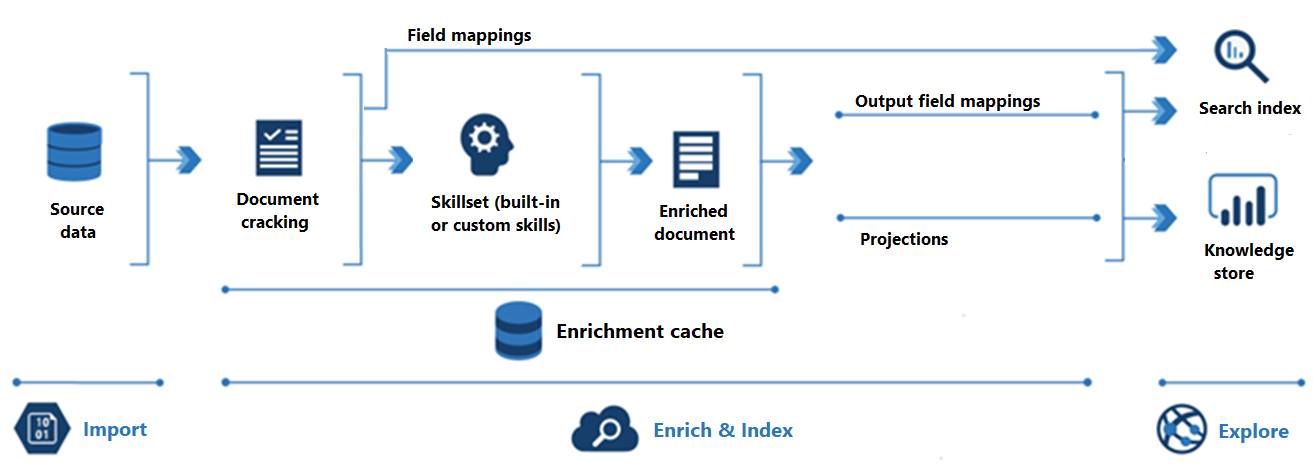
L’importation est la première étape. Ici, l’indexeur se connecte à une source de données et extrait du contenu (documents) dans le service de recherche. Stockage Blob Azure est la ressource la plus courante utilisée dans les scénarios d’enrichissement par IA, mais toute source de données prise en charge peut fournir du contenu.
Enrichir et indexer couvre une grande partie du pipeline d’enrichissement par IA :
L’enrichissement commence lorsque l’indexeur « craque les documents » et extrait les images et le texte. Le type de traitement qui se produit ensuite dépend de vos données et des compétences que vous avez ajoutées à un ensemble de compétences. Si vous avez des images, elles peuvent être transférées aux compétences qui effectuent le traitement des images. Le contenu du texte est mis en file d’attente pour le traitement du texte et du langage naturel. En interne, les compétences créent un « document enrichi » qui collecte les transformations à mesure qu’elles se produisent.
Le contenu enrichi est généré pendant l’exécution de l’ensemble de compétences, et il est temporaire à moins que vous ne le sauvegardiez. Vous pouvez permettre à un cache d’enrichissement de rendre persistants les documents et les sorties de compétence craqués pour une réutilisation ultérieure lors des exécutions ultérieures de l’ensemble de compétences.
Pour obtenir du contenu dans un index de recherche, l’indexeur doit disposer d’informations de mappage pour envoyer du contenu enrichi au champ cible. Les mappages de champs (explicites ou implicites) définissent le chemin de données des données sources vers un index de recherche. Les mappages de champs de sortie définissent le chemin des données des documents enrichis vers un index.
L’indexation est le processus dans lequel le contenu brut et enrichi est ingéré dans le structure de données physiques d’un index de recherche (ses fichiers et dossiers). L’analyse lexicale et la tokenisation se produisent dans cette étape.
L’exploration est la dernière étape. La sortie est toujours un index de recherche que vous pouvez interroger à partir d’une application cliente. La sortie peut éventuellement être une base de connaissances composée d’objets blob et de tables dans Stockage Azure accessibles via des outils d’exploration de données ou des processus en aval. Si vous créez une base de connaissances, les projections déterminent le chemin des données pour le contenu enrichi. Le même contenu enrichi peut apparaître dans les index et les bases de connaissances.
Quand utiliser l’enrichissement par IA
L’enrichissement est utile si votre contenu brut est du texte non structuré, du contenu d’image, ou du contenu qui nécessite la détection de la langue et une traduction. L’application d’IA, via les compétences intégrées, peut déverrouiller ce contenu pour la recherche en texte intégral et les applications de science des données.
Vous pouvez également créer des compétences personnalisées pour fournir un traitement externe. Du code open source, de tiers ou interne peut être intégré au pipeline en tant que compétence personnalisée. Les modèles de classification qui identifient les caractéristiques importantes de différents types de documents appartiennent à cette catégorie, mais n’importe quel package externe ajoutant de la valeur à votre contenu peut être utilisé.
Cas d’usage des compétences intégrées
Les compétences intégrées sont basées sur les API des services Azure AI : Azure AI Computer Vision et Language Service. Sauf si votre entrée de contenu est petite, attendez-vous à attacher une ressource facturable Azure AI Services pour exécuter des charges de travail plus volumineuses.
Un ensemble de compétences assemblé à l’aide de compétences intégrées convient parfaitement aux scénarios d’application suivants :
Les compétences de traitement d’image incluent la reconnaissance optique de caractères (OCR) et l’identification des caractéristiques visuelles, comme la détection des visages, l’interprétation des images, la reconnaissance des images (monuments et personnes célèbres) ou des attributs tels que l’orientation des images. Ces compétences créent des représentations textuelles du contenu d’image pour la recherche en texte intégral dans Azure AI Search.
La traduction automatique est assurée par la compétence Traduction de texte, souvent associée à la détection de la langue pour les solutions multilingues.
Le traitement du langage naturel analyse les blocs de texte. Les compétences de cette catégorie incluent la reconnaissance d’entité, la détection des sentiments (y compris l’exploration des opinions) et la détection des informations d’identification personnelle. Grâce à ces compétences, un texte non structuré est mappé sous la forme de champs pouvant être interrogés et filtrés dans un index.
Cas d’usage des compétences personnalisées
Les compétences personnalisées exécutent du code externe que vous fournissez et habillage dans l’interface web des compétences personnalisées. Vous trouverez plusieurs exemples de compétences personnalisées dans le dépôt azure-search-power-skills GitHub.
Les compétences personnalisées ne sont pas toujours complexes. Par exemple, si vous avez un package existant qui fournit la correspondance de modèles ou un modèle de classification de documents, vous pouvez l’encapsuler dans une compétence personnalisée.
Stockage de la sortie
Dans Azure AI Search, l’indexeur enregistre la sortie qu’il crée. Une exécution d’indexeur unique peut créer jusqu’à trois structures de données qui contiennent une sortie enrichie et indexée.
| Magasin de données | Requis | Emplacement | Descriptif |
|---|---|---|---|
| index pouvant faire l’objet d’une recherche | Requis | Service de recherche | Utilisé pour la recherche en texte intégral et d’autres formulaires de requête. La spécification d’un index est une exigence d’indexeur. Le contenu de l’index est rempli à partir de sorties de compétence, ainsi que tous les champs sources qui sont mappés directement aux champs de l’index. |
| base de connaissances | Facultatif | Stockage Azure | Utilisé pour les applications en aval telles que l’exploration de connaissances ou la science des données. Une base de connaissances est définie dans un ensemble de compétences. Sa définition détermine si vos documents enrichis sont projetés sous forme de tables ou d’objets (fichiers ou blobs) dans Stockage Azure. |
| cache d’enrichissement | Facultatif | Stockage Azure | Utilisé pour mettre en cache les enrichissements à réutiliser dans les exécutions d’ensembles de compétences suivantes. Le cache stocke le contenu importé et non traité (documents craqués). Il stocke également les documents enrichis créés pendant l’exécution de l’ensemble de compétences. La mise en cache est utile si vous utilisez l’analyse d’images ou OCR et que vous souhaitez éviter le temps et les frais de retraitement des fichiers image. |
Les index et les bases de connaissances sont totalement indépendants les uns des autres. Bien que vous deviez joindre un index pour satisfaire aux exigences de l’indexeur, si votre seul objectif est une base de connaissances, vous pouvez ignorer l’index une fois qu’il est rempli.
Exploration du contenu
Une fois que vous avez défini et chargé un index de recherche ou une base de connaissances, vous pouvez explorer ses données.
Interroger un index de recherche
Exécutez des requêtes pour accéder au contenu enrichi généré par le pipeline. L’index est semblable à tous les autres que vous pouvez créer pour Azure AI Search : vous pouvez compléter l’analyse de texte avec des analyseurs personnalisés, appeler des requêtes de recherche approximatives, ajouter des filtres ou expérimenter des profils de scoring pour régler la pertinence de la recherche.
Utiliser des outils d’exploration de données sur une base de connaissances
Dans Stockage Azure, une base de connaissances peut adopter les formes suivantes : un conteneur d’objets blob de documents JSON, un conteneur d’objets blob d’objets image ou des tables dans Stockage Table. Vous pouvez utiliser Explorateur Stockage, Power BI ou toute autre application qui se connecte à Stockage Azure pour accéder à votre contenu.
Un conteneur d’objets blob capture les documents enrichis dans leur intégralité, ce qui est utile si vous créez un flux dans d’autres processus.
Une table est utile si vous avez besoin de secteurs de documents enrichis, ou si vous voulez inclure ou exclure des parties spécifiques de la sortie. Pour l’analyse dans Power BI, les tables sont la source de données recommandée pour l’exploration et la visualisation de données dans Power BI.
Disponibilité et tarification
L’enrichissement est disponible dans les régions qui ont des services Azure AI. Vous pouvez vérifier la disponibilité de l’enrichissement dans la page Liste des régions.
La facturation suit un modèle tarifaire Standard. Les coûts liés à l’utilisation des compétences intégrées sont transmis lorsqu’une clé de services Azure AI multirégion est spécifiée dans l’ensemble de compétences. D’autres coûts sont également associés à l’extraction d’images, tels que mesurés par Azure AI Search. L’extraction de texte et les compétences des utilitaires ne sont pas facturables. Pour plus d’informations, consultez Comment vous êtes facturé pour Azure AI Search.
Liste de vérification : un flux de travail typique
Un pipeline d’enrichissement se compose d’indexeurs dotés d’ensembles de compétences. Après l’indexation, vous pouvez interroger un index pour valider vos résultats.
Commencez par un sous-ensemble de données dans une source de données prise en charge. La conception de l’indexeur et l’ensemble de compétences est un processus itératif. Le travail va plus vite avec un petit jeu de données représentatif.
Créez une source de données qui spécifie une connexion à vos données.
Créer un ensemble de compétences. Sauf si votre projet est petit, vous devez attacher une ressource multiservices Azure AI Services. Si vous créez une base de connaissances, définissez-la dans l’ensemble de compétences.
Créez un schéma d’index qui définit un index de recherche.
Créez et exécutez un indexeur pour rassembler tous les composants ci-dessus. Cette étape récupère les données, exécute les ensembles de compétences et charge l’index.
Un indexeur est également l’endroit où vous spécifiez des mappages de champs et des mappages de champs de sortie qui configurent le chemin d’accès aux données vers un index de recherche.
Éventuellement, activez la mise en cache d’enrichissement dans la configuration de l’indexeur. Cette étape vous permet de réutiliser les enrichissements existants ultérieurement.
Exécutez des requêtes pour évaluer les résultats ou démarrer une session de débogage pour résoudre tous les problèmes liés à l’ensemble de compétences.
Pour répéter une des étapes ci-dessus, réinitialisez l’indexeur avant de l’exécuter. Vous pouvez aussi supprimer et recréer les objets à chaque exécution (recommandé si vous utilisez le niveau gratuit). Si vous avez activé la mise en cache de l’indexeur extrait le cache si les données ne sont pas modifiées à la source, et si vos modifications au pipeline n’invalident pas le cache.