Reconcevoir la topologie de recherche d’entreprise en fonction des exigences de performances spécifiques dans SharePoint
S’APPLIQUE À : 2013 2016 2019 Édition d’abonnement
2013 2016 2019 Édition d’abonnement  SharePoint dans Microsoft 365
SharePoint dans Microsoft 365
Si votre environnement de recherche présente des exigences de performances spécifiques qui n'ont pas été satisfaites en suivant les indications contenues dans Planifier l'architecture de recherche d'entreprise dans SharePoint Server 2016, la solution consiste à mettre à l'échelle la topologie de l'architecture de recherche de votre entreprise :
Reconcevez votre topologie (voir le présent article).
Implémentez la topologie redéfinie (Gérer la topologie de recherche dans SharePoint Server).
Connaissez-vous les composants du système de recherche dans SharePoint Server 2016 et la façon dont ils interagissent ? Lisez la rubrique Vue d'ensemble de l'architecture de recherche dans SharePoint Server et le document Architectures de recherche pour SharePoint Server 2016 (ou Architectures de recherche pour SharePoint Server 2013) avant de continuer pour apprendre à connaître l'architecture de recherche, les composants de recherche, les bases de données de recherche et la topologie de recherche.
Dans cet article, nous allons vous montrer étape par étape comment reconcevoir votre topologie de recherche pour satisfaire des exigences de performances spécifiques :
Étape 1 : Quels sont les exigences de performances spécifiques ?
Étape 2 : Quels composants de recherche dois-je mettre à l'échelle ?
Étape 3 : Choisir d'exécuter des serveurs physiques ou virtuels
Étape 5 : De quelle configuration matérielle requise dois-je tenir compte ?
Une fois que vous aurez suivi ces étapes, vous connaîtrez :
le nombre de chaque type de composant de recherche et de base de données de recherche dont votre topologie a besoin ;
les serveurs d’applications et les serveurs de base de données sur lesquels déployer chaque composant de recherche ;
les ressources matérielles dont chaque serveur d’applications et chaque serveur de base de données a besoin.
Étape 1 : Quels sont les exigences de performances spécifiques ?
Assurez-vous que vous comprenez les besoins de l’entreprise qui sous-tendent les exigences de performances spécifiques. Par exemple, une recherche sur l'actualité ou les finances exige des données récentes indexées quasiment en temps réel, tandis que les services d'assistance aux litiges nécessitent l'ingestion de lots de données indexées une seule fois. Exprimez les exigences de performances avec une ou plusieurs des méthodes suivantes :
le nombre d’éléments indexés ;
le nombre d’éléments que la solution de recherche doit analyser par seconde et avec quelle latence ;
le nombre de requêtes que la solution de recherche doit traiter par seconde et avec quelle latence.
En plus de ces exigences de performances, votre environnement peut également avoir des exigences en matière de pertinence des résultats de requête et de redondance de la topologie de recherche. Parfois, vous n'avez pas d'exigences de performances spécifiques, mais vous avez identifié un goulot d'étranglement dans l'architecture de recherche qui pourrait nuire aux performances. Nous aborderons également ce point.
Étape 2 : Quels composants de recherche dois-je mettre à l’échelle ?
Pour fournir des performances plus élevées ou supprimer un goulot d’étranglement, vous pouvez ajouter davantage de composants de recherche ou vous pouvez ajouter davantage de ressources aux serveurs hébergeant des composants de recherche. L'ajout de plus de composants de recherche est connu sous le nom de mise à l'échelle horizontale, tandis que l'ajout de plus de ressources aux serveurs est connu sous le nom de mise à l'échelle verticale. Les composants de recherche à mettre à l'échelle horizontalement ou les serveurs à mettre à l'échelle verticalement dépendent de la mesure des performances à améliorer ou du goulot d'étranglement à supprimer. Voici quelques exemples :
Si l'environnement exige un taux de requête plus élevé et que les ressources de processeur pour l'indexation forment un goulot d'étranglement, ajoutez une autre copie d'index à chaque partition de l'index. Ainsi, la recherche peut traiter davantage de requêtes en parallèle.
Si les ressources de processeur pour le traitement du contenu analysé forment un goulot d'étranglement, mettez à l'échelle horizontalement le nombre de composants de traitement de contenu. Vous pouvez également mettre à l'échelle verticalement les composants de traitement de contenu en les exécutant sur des serveurs avec plus de processeurs ou avec des processeurs plus rapides. Les deux méthodes de mise à l'échelle impliquent l'utilisation de plus de ressources de processeur pour le traitement de contenu.
Si les composants d'analyse ne terminent pas assez rapidement leurs analyses, mettez à l'échelle verticalement les ressources de processeur, les IOPS du disque ou la bande passante réseau sur les serveurs hébergeant les composants d'analyse.
Notez que nous ne prenons pas en charge une mise à l'échelle horizontale illimitée du nombre de composants ou de bases de données de recherche. Consultez les limites maximales dans Limites de la recherche et respectez ces limites afin d'assurer une communication rapide et robuste entre les composants de recherche et les bases de données de recherche. Si nécessaire, réduisez la capacité de votre architecture de recherche en diminuant le nombre de composants de recherche.
Les sections suivantes présentent des conseils concernant les composants ou bases de données de recherche à mettre à l’échelle afin de répondre à chaque exigence :
Augmentation du taux d'ingestion et de l'actualisation des résultats
Réduction de la latence de requête et augmentation du débit de requête
Mise en place de la redondance de vos composants et bases de données de recherche
Gestion d’éléments supplémentaires dans l’index
Lorsque la quantité d’éléments indexés augmente tandis que les éléments indexés changent à la même fréquence qu’avant, augmentez la capacité de votre topologie de recherche en mettant à l’échelle horizontalement les composants et bases de données de recherche suivants :
| Composant ou base de données de recherche | Conseil |
|---|---|
| Composant d'index | Utilisez une partition d'index par tranche de 20 millions1 d'éléments indexés. Chaque partition contient une ou plusieurs copies de la partition. Toutes les partitions doivent avoir le même nombre de copies. Un composant d'index représente une copie d'index. Par conséquent, si vous voulez deux copies de l'index, vous aurez besoin de deux fois plus de composants d'index que de partitions d'index. Par exemple, un index redondant avec 80 millions2 d'éléments exige quatre partitions. Huit composants d'index représentent les quatre partitions en cas d'utilisation de deux copies pour chaque partition. |
| Base de données d'analyse | Utilisez une base de données d'analyse par tranche de 20 millions d'éléments dans le corpus de contenu. Par exemple, un index de 100 millions d'éléments requiert cinq bases de données d'analyse. Si l'augmentation de la quantité d'éléments indexés implique un taux d'analyse plus élevé, vous avez également besoin de plus de ressources d'IOPS pour traiter les bases de données d'analyse. Si votre taux d'analyse est de un document par seconde, la base de données d'analyse a besoin d'environ 10 IOPS. |
| Base de données de liens | Utilisez une base de données de liens par tranche de 60 millions d'éléments dans le corpus de contenu. Par exemple, un index de 100 millions d'éléments requiert deux bases de données de liens. Si le contenu ajouté implique un taux d’analyse plus élevé, vous pourriez avoir besoin de plus de ressources d’IOPS pour traiter les bases de données de liens. |
| Base de données de création de rapports d'analyse | Le nombre de bases de données de rapports analytiques dont vous avez besoin dépend de la façon dont l’environnement de recherche utilise l’analytique et de la fréquence. En général, ajoutez une base de données de rapports d’analyse lorsque les performances d’analyse commencent à diminuer. Par exemple, lorsque la mise à jour nocturne de la base de données commence à prendre plus de temps. Cela peut se produire lorsque la base de données atteint une taille de 250 Go, soit 20 millions de lignes au total, ou lorsque le nombre de vues par jour atteint 500 000 éléments uniques. |
110 millions d’éléments avec SharePoint Server 2013 ou SharePoint Server 2016 s’exécutant avec moins de ressources de 500 Go de stockage, 32 Go de RAM et huit cœurs de processeur.
240 millions d’éléments avec SharePoint Server 2013 ou sharePoint Server 2016 s’exécutant avec moins de ressources de 500 Go de stockage, 32 Go de RAM et huit cœurs de processeur.
Augmentation du taux d’ingestion et de l’actualisation des résultats
Dans certains cas, vous devrez peut-être augmenter le taux d’ingestion. Par exemple, si votre environnement nécessite des résultats très frais et que le volume de contenu est proche de la limite d’éléments supérieure pour votre architecture de recherche, ou si le contenu change souvent. Le contenu peut changer souvent si les utilisateurs archivent des fichiers sur un site d’équipe, mais maintenant ils stockent leurs fichiers sur OneDrive pendant qu’ils travaillent dessus. La recherche indexe toutes les modifications apportées à leurs fichiers.
Il est utile de comprendre quels facteurs influencent la rapidité avec laquelle la recherche peut recevoir des éléments :
La rapidité avec laquelle la recherche peut analyser des éléments. Celle-ci dépend des points suivants :
la vitesse de la connexion entre les composants d’analyse et les sources de contenu :
le type et la taille moyenne des éléments à analyser ;
les performances du serveur SQL qui héberge les bases de données d’analyse ;
la quantité de ressources de processeur et de mémoire détenue par les composants d’analyse.
La quantité de traitement de contenu nécessaire à chaque élément avant l’indexation.
La quantité de partitions détenues par l'index. Un nombre de partitions plus élevé permet à la recherche de répartir la charge de l'indexation.
Voici comment procéder :
Vérifiez l'actualisation des résultats dans votre batterie de serveurs en regardant la répartition par âge des éléments analysés. Sur le le site Web Administration centrale de SharePoint, accédez à Rapports d'intégrité de l'analyse et sélectionnez Analyser l'actualisation. La distribution par âge acceptable pour votre batterie de serveurs dépend des besoins de votre entreprise. Voici un exemple : si la page Analyser l'actualisation indique que quatre heures sont nécessaires pour indexer 90 % du contenu mais que vous ne disposez que de 30 minutes, augmentez le taux d'ingestion.
Sur la page Analyser l'actualisation, identifiez à quelles périodes de la journée ces résultats ne sont pas assez récents.
Suivez les conseils pour augmenter la vitesse d’ingestion à ces périodes.
Améliorer l’actualisation pour une source de contenu spécifique
Vérifiez la planification d’analyse et identifiez les sources de contenu qui recherchent des analyses aux périodes où l’actualisation est faible. Si l'actualisation est faible pour une source de contenu spécifique, envisagez les solutions suivantes :
Augmentez la vitesse de la connexion entre le serveur hébergeant le composant d'analyse et cette source de contenu. C'est le taux d'analyse, en téléchargeant des éléments à partir de sources de contenu et en transmettant des éléments au composant de traitement de contenu, qui génère le besoin en bande passante réseau pour le composant d'analyse.
Si la source de contenu est SharePoint, cette batterie de serveurs peut avoir besoin de cibles d'analyse dédiées et plus nombreuses. Pour plus d'informations sur les cibles d'analyse, voir Gérer la charge d'analyse (SharePoint Server 2010).
Améliorez les performances de la base de données de contenu. Pour savoir comment procéder, voir Meilleures pratiques pour SQL Server dans une batterie de serveurs SharePoint Server.
Augmenter les ressources de traitement pour l’analyse
Si le composant d'analyse utilise souvent la totalité des ressources de processeur, envisagez l'ajout d'un autre composant d'analyse ou l'ajout de plus de ressources de processeur pour les serveurs hébergeant les composants d'analyse. Le taux d'analyse, la découverte de liens et la gestion de l'analyse sont à l'origine du besoin en ressources de processeur. Normalement, l'analyse est suffisamment rapide lorsque vous utilisez deux composants d'analyse dans des architectures de recherche telles que les petits et moyens échantillons d'architecture de recherche estimés par Microsoft. Les architectures de recherche telles que les grands et très grands échantillons peuvent nécessiter plus de deux composants d'analyse.
Augmenter les ressources de traitement de la base de données d’analyse
Vérifiez que les serveurs SQL hébergeant des bases de données d'analyse disposent de ressources suffisantes. Pour savoir comment procéder, voir Meilleures pratiques pour SQL Server dans une batterie de serveurs SharePoint Server.
Si toutes les bases de données d'analyse utilisent beaucoup de ressources de processeur, envisagez d'ajouter plus de ressources de processeur sur le serveur SQL qui héberge les bases de données ou d'ajouter un autre serveur SQL avec le même nombre de bases de données d'analyse que les serveurs SQL existants. Par exemple, si vous avez deux serveurs SQL ayant chacun trois bases de données d'analyse, ajoutez un autre serveur SQL avec trois bases de données d'analyse.
Si seulement quelques bases de données d'analyse (ou une seule) utilisent une grande quantité des ressources de processeur, cela signifie que la charge est inégalement répartie entre les bases de données d'analyse. Envisagez de rééquilibrer le contenu entre toutes les bases de données d'analyse. Notez que, lors du rééquilibrage, la recherche interrompt l'analyse, donc les résultats sont moins récents au cours du rééquilibrage et jusqu'à ce que l'analyse ait rattrapé les modifications ayant eu lieu pendant l'interruption. Déclenchez le rééquilibrage à l'aide du bouton Équilibrer sur la page Bases de données. Dans Administration de la recherche, accédez à Journal d’analyse et sélectionnez Bases de données.
Augmenter les ressources de traitement et de mémoire pour le traitement du contenu
Si le composant de traitement de contenu utilise près de 100 % des ressources de processeur, envisagez l’ajout de plus de composants de traitement de contenu ou l’ajout de plus de ressources de processeur pour les serveurs hébergeant le composant de traitement de contenu.
Si vous remarquez que la mémoire redémarre souvent, pensez à augmenter la quantité de mémoire sur les serveurs hébergeant les composants de traitement de contenu. Une bonne règle de base est d’allouer 2 Go de mémoire de travail par cœur de processeur.
Augmenter le nombre de partitions d’index
Vérifiez l’activité de traitement du contenu. Pour ce faire, accédez à Administration de la recherche, sélectionnez Rapports d'intégrité de l'analyse, puis Activité de traitement du contenu. Si l'indexation est l'activité qui prend le plus de temps, envisagez de diviser l'index en plus de partitions. Un nombre plus important de partitions d'index permet à la recherche de répartir la charge de l'indexation.
Si vous ajoutez plus de partitions sur une installation en cours, l'index se repartitionne lui-même. Le repartitionnement de l'index peut prendre plusieurs heures, voire plusieurs jours. La durée dépend de l’état de la batterie de serveurs au début du repartitionnement.
Réduction de la latence de requête et augmentation du débit de requête
Le débit de requête désigne le nombre de requêtes que la recherche peut traiter par seconde. Le débit de requête dépend du temps utilisé par la recherche pour traiter une requête et du temps pendant lequel la requête est en attente parce qu'une ressource de traitement n'est pas disponible. La somme du temps de traitement et du temps d'attente est appelée latence de requête. La diminution de la latence de requête augmente le débit de requête. Pour réduire la latence de requête, suivez au moins un de ces conseils :
| Conseil |
|---|
| Réduire le temps de traitement des requêtes |
| Réduire le temps d'attente des requêtes |
Réduire le temps de traitement des requêtes
Envisagez d’ajouter d’autres partitions à l’index. Plus de partitions signifient moins d’éléments dans chaque partition. Moins d’éléments signifient que chaque partition répond plus rapidement aux requêtes. Mais trop de partitions ne sont pas bonnes non plus. Étant donné que le composant de traitement de requête doit fusionner les réponses de chaque partition pour produire une réponse à une requête, une fusion prend plus de temps lorsque l’index a plus de partitions. Toutes les partitions doivent avoir le même nombre de copies.
Lorsque vous ajoutez plus de partitions sur une installation en cours, l'index se repartitionne lui-même. Le repartitionnement de l'index peut prendre plusieurs heures, voire plusieurs jours. La durée dépend de l’état de la batterie de serveurs au début du repartitionnement.
Réduire le temps d’attente des requêtes
Envisagez les actions suivantes :
Ajoutez davantage de copies de l'index. Lorsque vous ajoutez plus de copies, la recherche répartit les requêtes parmi les copies et travaille sur celles-ci en parallèle. Un composant d'index représente une copie d'index. Toutes les partitions doivent avoir le même nombre de copies, vous devez donc ajouter un composant d'index à chaque partition de l'index. Lorsque vous ajoutez des composants d'index aux partitions existantes en tant que copies sur une installation en cours, la recherche amorce automatiquement les nouvelles copies avec les données de la partition d'index. Plusieurs heures peuvent être nécessaires pour que les nouvelles copies soient opérationnelles.
Ajoutez davantage de mémoire aux serveurs hébergeant des composants d’index.
Sur les serveurs hébergeant des composants d’index, passez à une méthode de stockage plus rapide pour l’index, par exemple un disque SSD.
Ajoutez davantage de ressources de processeur aux serveurs hébergeant des composants d'index. Par la suite, les composants gèrent un plus grand nombre de requêtes par seconde. Par exemple, si le serveur dispose d'un processeur de 2 GHz, un seul cœur peut gérer :
5 requêtes par seconde lorsque vous avez 1 million d’éléments dans l’index.
2 requêtes par seconde lorsque vous avez 5 millions d’éléments dans l’index.
1 requête par seconde lorsque vous avez 10 millions d’éléments dans l’index.
Ajoutez davantage de ressources de processeur aux serveurs hébergeant des composants de traitement des requêtes. Par la suite, les composants gèrent un plus grand nombre de requêtes par seconde, en particulier lorsque les requêtes sont rares et complexes. Ce sont le taux de requête et le nombre de transformations de requête qui génèrent le besoin de ressources de processeur pour le composant de traitement des requêtes. Un composant de traitement des requêtes a généralement besoin d'un cœur de processeur par tranche de 4 requêtes par seconde.
Diminution du temps de traitement de l’analyse
Le traitement de l’analyse se déroule tous les nuits. Le composant de traitement d'analyse stocke des données intermédiaires sur le serveur hébergeant le composant, et stocke les résultats de l'analyse dans la base de données de création de rapports d'analyse. Si une erreur empêche le traitement de l'analyse, cela n'affectera pas l'analyse de document ou la réponse à des requêtes. Cependant, les résultats de requête ne seront pas d'une pertinence optimale.
Envisagez les actions suivantes :
Si votre environnement nécessite une pertinence optimale des résultats de requête et que le traitement de l'analyse n'est pas assez rapide pour satisfaire ce besoin, ajoutez des disques supplémentaires (piles) ou des disques plus rapides.
Si le traitement de l'analyse commence à prendre plus de temps que d'habitude, ajoutez une base de données de création de rapports d'analyse. Cela peut se produire lorsque la base de données atteint une taille de 250 Go, ou un total de 20 millions de lignes, ou lorsque le nombre de vues par jour atteint 500 000 éléments uniques.
Si le traitement d'analyse prend plus de 24 heures, ajoutez plus de composants de traitement d'analyse, ou ajoutez plus de ressources de processeur aux serveurs hébergeant des composants de traitement d'analyse. Ce sont le nombre d'éléments dans l'index et l'activité sur le site qui génèrent le besoin de ressources de processeur.
Si le traitement de l'analyse ne se termine jamais, ou si vous obtenez des alertes d'intégrité pour les disques sur les serveurs hébergeant des composants d'analyse, ajoutez plus d'espace disque sur ces serveurs. Pour que le composant d’analyse puisse traiter plus rapidement une plus grande quantité de données intermédiaires, envisagez d’ajouter davantage de composants de traitement d’analyse ou davantage de ressources de processeur sur le serveur hébergeant le composant de traitement d’analyse.
Mise en place de la redondance de vos composants et bases de données de recherche
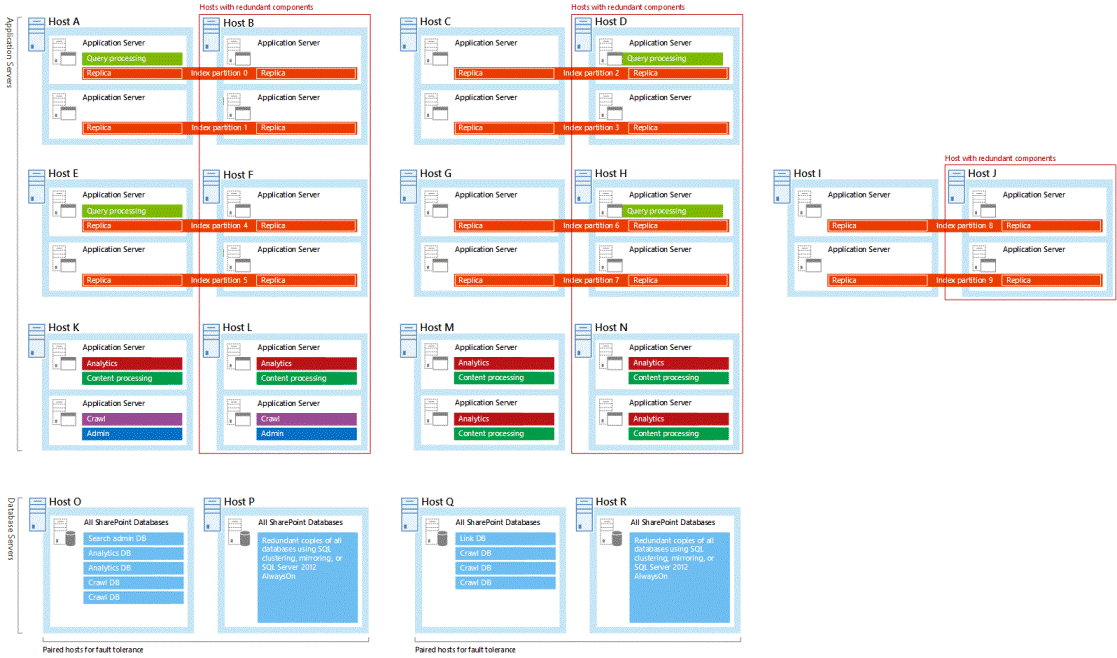
Votre architecture de recherche prend en charge la haute disponibilité quand vous hébergez des bases de données et des composants de recherche redondants sur des domaines d'erreur distincts. Nous vous recommandons de concevoir votre topologie de recherche avec des bases de données et des composants de recherche redondants. Tous les exemples d’architectures de recherche testés par Microsoft ont des bases de données et des composants de recherche redondants. Il peut être utile d’étudier ces exemples lorsque vous travaillez sur votre propre topologie (voir Enterprise Search Architectures for SharePoint 2016).
Suivez les conseils suivants :
Rendre redondant l’index
Votre index est redondant s’il a au moins deux copies d’index par partition d’index. En cas de défaillance d'un serveur hébergeant une copie d'index, cela peut réduire les performances mais la recherche peut tout de même traiter des requêtes et des éléments d'index. Cependant, si l'environnement doit délivrer des performances constantes à tous moments, la recherche a besoin de composants d'index plus redondants. Par exemple : vous avez conçu votre topologie de recherche avec deux copies par partition afin de réduire le temps d'attente pour les requêtes et votre environnement nécessite un court temps d'attente pour les requêtes en permanence. Augmentez le nombre de copies d'index par partition.
Toutes les partitions doivent avoir le même nombre de copies. Un composant d'index représente une copie d'index. Par conséquent, si vous voulez deux copies de l'index, vous aurez besoin de deux fois plus de composants d'index que de partitions d'index. Par exemple, un index redondantSharePoint Server 2016 avec 80 millions d'éléments exige quatre partitions. Huit composants d'index représentent les quatre partitions en cas d'utilisation de deux copies pour chaque partition.
Si vous ajoutez des composants d'index aux partitions existantes en tant que copies sur une installation en cours, la recherche amorce automatiquement les nouvelles copies avec les données de la partition d'index. Plusieurs heures peuvent être nécessaires pour que les nouvelles copies soient opérationnelles.
Rendre redondants les composants d’analyse, de traitement de contenu, de traitement des requêtes, de traitement d’analyse et d’administration de la recherche
Prenons le composant d'analyse comme exemple. Si vous devez arrêter l'un des serveurs hébergeant un composant d'analyse pour maintenance, cela peut réduire l'actualisation des résultats mais la recherche peut tout de même analyser tout le contenu. Cependant, si l'environnement nécessite la même actualisation des résultats en permanence, la recherche a besoin de composants d'analyse plus redondants. Par exemple : vous avez conçu votre topologie de recherche avec trois composants d'analyse et vous voulez la même actualisation de résultats même en cas de défaillance de deux serveurs de composants d'analyse. Ajoutez deux autres composants d'analyse.
Le composant d'administration de la recherche est une exception à ce principe. Un composant d'administration de la recherche a une capacité suffisante pour n'importe quelle topologie de recherche, peu importe sa taille. Ainsi, deux composants d'administration de la recherche sont suffisants pour assurer la redondance.
Les composants de traitement de contenu équilibrent la charge entre eux, donc les composants de traitement de contenu redondants augmentent la capacité de traitement des éléments.
Rendre redondantes les bases de données de recherche
Pour rendre redondantes vos bases de données de recherche, utilisez les alternatives haute disponibilité offertes par SQL Server (voir Créer une architecture et une stratégie haute disponibilité pour SharePoint Server).
Étape 3 : Choisir d’exécuter des serveurs physiques ou virtuels
Lorsque vous avez initialement planifié votre architecture de recherche, vous avez décidé d’utiliser des serveurs physiques, des machines virtuelles, ou un mélange des deux. Demandez-vous si cette décision est toujours valide. Si vous avez maintenant beaucoup plus de composants de recherche, vous pouvez utiliser des machines virtuelles pour faciliter la gestion de l'architecture. Par exemple, il est plus facile de remplacer une machine virtuelle défaillante qu'une machine physique. Notez également que même si un environnement virtuel est plus facile à gérer, son niveau de performances peut parfois être légèrement plus faible que celui d'un environnement physique. Un serveur physique peut héberger plus de composants de recherche sur le même serveur qu'un serveur virtuel. Vous trouverez des conseils utiles ici : Overview of farm virtualization and architectures for SharePoint 2013.
Étape 4 : Quel serveur pour héberger quel composant de recherche ou quelle base de données de recherche ?
Maintenant que vous avez reconçu votre topologie de recherche, la prochaine étape consiste à attribuer les composants et bases de données de recherche aux serveurs physiques ou virtuels. Il n'y a pas de méthode optimale pour attribuer des composants de recherche aux serveurs physiques ou aux machines virtuelles, mais nous vous proposons quelques conseils :
Un seul type de composant de recherche par serveur
Chaque serveur physique ou machine virtuelle ne peut héberger qu’un seul composant de recherche de chaque type. Le composant d'index constitue une exception. Les serveurs physiques ou les machines virtuelles peuvent héberger jusqu'à quatre composants d'index. Ces limites sont détaillées dans Limites de la recherche.
Séparer les composants de traitement en bloc et en temps réel
Évitez de mélanger des composants de recherche de traitement en bloc et de traitement en temps réel sur le même serveur physique ou la même machine virtuelle. Les composants d'analyse, de traitement de contenu et de traitement d'analyse effectuent un traitement en bloc. Les composants de traitement d'index et de traitement des requêtes effectuent un traitement en temps réel.
Ne pas mélanger des composants de recherche concurrents
Évitez de mélanger des composants de recherche sur un serveur ou une machine physique si ces composants seront en compétition pour les mêmes ressources. Voici un tableau qui indique la quantité relative de ressources dont chaque composant a besoin.
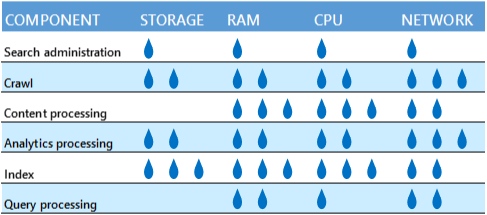
Par exemple, il est déconseillé de mettre un composant d'analyse et un composant de traitement de l'analyse sur le même serveur, car ils utilisent tous les deux beaucoup de bande passante réseau. Cependant, si le serveur physique ou la machine virtuelle a une capacité réseau suffisante, les composants ne seront pas en concurrence.
Un autre exemple est l’exemple d’architecture de recherche très volumineuse que Microsoft a estimé. Ici, nous avons placé les composants d’administration d’analyse et de recherche sur des machines virtuelles distinctes. Cela est bon pour la vitesse de l’analyse, car les deux composants pourraient être en concurrence pour les ressources du processeur.
Utiliser des domaines d’échec
Attribuez les composants de recherche redondants aux hôtes dans des domaines d’échec distincts.
Étape 5 : De quelle configuration matérielle requise dois-je tenir compte ?
L'étape suivante consiste à planifier le matériel dont vous aurez besoin :
Choisir la quantité de ressources matérielles pour les serveurs hôtes
Ressources minimales pour le composant de traitement de l'analyse
Choisir le mode de prise en charge de la haute disponibilité dans votre architecture de recherche
Choisir la quantité de ressources matérielles pour les serveurs hôtes
Chaque composant de recherche et base de données de recherche a besoin d’une quantité minimale de ressources matérielles du serveur hôte pour fonctionner correctement. Cependant, plus vous avez de ressources matérielles, plus les performances de votre architecture de recherche seront bonnes. Il est donc judicieux de disposer de plus de ressources matérielles que le minimum requis. Les ressources que chaque composant de recherche exige dépendent de la charge de travail, qui est la plupart du temps déterminée par le taux d'analyse, le taux de requête et le nombre d'éléments indexés.
Par exemple, en cas d'hébergement de machines virtuelles sur Windows Server 2008 R2 Service Pack 1 (SP1), vous ne pouvez pas utiliser plus de quatre cœurs de processeur par machine virtuelle. Avec Windows Server 2012 ou une version ultérieure, vous utilisez au moins huit cœurs de processeur par machine virtuelle. Vous pouvez alors effectuer une mise à l'échelle horizontale avec plus de cœurs de processeur pour chaque machine virtuelle au lieu d'effectuer une mise à l'échelle verticale avec plus de machines virtuelles. Configurez des serveurs ou des machines virtuelles qui hébergent les mêmes composants de recherche, avec les mêmes ressources matérielles. Prenons le composant d'index comme exemple. Lorsque vous hébergez des partitions d'index sur des machines virtuelles, la machine virtuelle ayant les performances les plus faibles détermine les performances de l'architecture de recherche globale.
Stockage global
Veillez à ce que chaque serveur hôte dispose d'un espace disque suffisant pour l'installation de base du système d'exploitation Windows Server et des fichiers de programme SharePoint Server 2016. Le serveur hôte doit aussi disposer d'un espace disque supplémentaire pour les fonctions de diagnostic, telles que la journalisation, le débogage et la création de fichiers de vidage de la mémoire, pour les opérations quotidiennes et pour le fichier d'échange. Normalement, 80 Go d'espace disque sont suffisants pour le système d'exploitation Windows Server et pour les fichiers de programme SharePoint Server 2016.
Ajoutez du stockage pour l'espace du journal SQL de chaque serveur de base de données. Si vous ne définissez pas le serveur de base de données pour sauvegarder les bases de données régulièrement, l'espace du journal SQL utilise beaucoup de stockage. Pour plus d'informations sur le mode de planification des bases de données SQL, voir Planification et configuration de la capacité de SQL Server et du stockage (SharePoint Server).
Le stockage minimal requis par la base de données de rapports d’analytique peut varier. En effet, la quantité de stockage dépend de la façon dont les utilisateurs interagissent avec SharePoint Server 2016. Lorsque les utilisateurs interagissent fréquemment, il y a généralement plus d’événements à stocker. Vérifiez la quantité de stockage utilisée par votre architecture de recherche actuelle pour la base de données d’analyse et affectez au moins cette quantité à votre topologie repensée.
Ressources minimales pour le composant d’index
Voici les ressources minimales dont doit disposer un serveur ou une machine virtuelle pour héberger un composant d’index, ou pour héberger un composant d’index et un composant de traitement des requêtes :
| Stockage | Mémoire | Processeur | Bande passante réseau |
| 500 Go pour l'index1 | 32 GB1 | 64 bits, 8 cœurs minimum1, 2. | 2 Gbits/s |
1Avec SharePoint Server 2013, la quantité minimale de ressources est de 500 Go de stockage, 16 Go de RAM et quatre cœurs de processeur.
2Vous pouvez utiliser 16 Go de RAM et quatre cœurs d'UC avec SharePoint Server 2016, mais chaque composant d'index peut alors comporter 10 millions d'éléments au maximum (au lieu de 20 millions).
Ressources minimales pour le composant de traitement de l’analyse
Voici les ressources minimales dont doit disposer un serveur ou une machine virtuelle pour héberger un composant de traitement de l’analyse :
| Stockage | Mémoire | Processeur | Bande passante réseau |
| 300 Go pour le traitement local d’analyses | 8 Go | 64 bits, 4 cœurs minimum, mais 8 cœurs recommandés. | 2 Gbits/s |
Si le serveur héberge un composant de traitement de l’analyse et un ou plusieurs composants de traitement en bloc, augmentez la mémoire jusqu’à 16 Go.
Ressources minimales pour le composant d’analyse, de traitement de contenu, de traitement des requêtes et d’administration de la recherche
Voici les ressources minimales dont doit disposer un serveur ou une machine virtuelle pour héberger l’un de ces composants :
| Stockage | Mémoire | Processeur | Bande passante réseau |
| Non requis | 8 Go | 64 bits, 4 cœurs minimum, mais 8 cœurs recommandés. | 2 Gbits/s |
Si le serveur héberge au moins deux de ces composants, augmentez la mémoire jusqu’à 16 Go.
Le composant de traitement des requêtes nécessite une bonne bande passante réseau. Ce sont le nombre de partitions d'index et la taille des requêtes et des résultats qui génèrent ce besoin en bande passante réseau. Par exemple, 20 requêtes par seconde par composant de traitement des requêtes (20 QPS/QPC) et un index avec 20 partitions d'index occasionnent 200 Mbits/s de trafic entrant et 100 Mbits/s de trafic sortant pour le serveur ou la machine virtuelle hébergeant le composant de traitement des requêtes.
Ressources minimales pour les bases de données de recherche
Voici les ressources minimales dont doit disposer un serveur ou une machine virtuelle pour héberger une ou plusieurs bases de données de recherche :
| Stockage | Mémoire | Processeur | Bande passante réseau |
| L'espace de stockage minimal requis par la base de données de création de rapports d'analyse varie selon la manière dont l'environnement de recherche utilise l'analyse et la fréquence. Utilisez la quantité actuelle de stockage pour la base de données de création de rapports d'analyse à titre indicatif. | 8 Go pour les déploiements à petite échelle 16 Go pour les déploiements à moyenne échelle |
64 bits, 4 cœurs. | 2 Gbits/s |
Planifier les performances de stockage
La vitesse du stockage a une incidence sur les performances de recherche. Veillez à ce que le stockage dont vous disposez soit assez rapide pour gérer le trafic provenant des bases de données et des composants de recherche. La vitesse du disque est mesurée en opérations d'E/S par seconde (IOPS).
La façon dont vous décidez de distribuer les données provenant des composants de recherche et du système d'exploitation dans l'ensemble de votre stockage influe sur les performances de recherche. Il est conseillé d'effectuer les actions suivantes :
Fractionner les fichiers du système d'exploitation de Windows Server, les fichiers de programme de SharePoint Server 2016 et les journaux de diagnostic en trois volumes ou partitions de stockage distincts avec des performances normales.
Stocker les données de composant de recherche sur un volume ou une partition de stockage distinct. Pour les composants d'index, ce stockage doit également avoir des performances élevées.
Notes
[!REMARQUE] Vous pouvez définir un emplacement personnalisé pour les données de composant de recherche lorsque vous installez SharePoint Server 2016 sur un hôte. Tous les composants de recherche sur l'hôte qui doivent stocker des données le font à cet emplacement. Pour modifier cet emplacement par la suite, vous devez réinstaller SharePoint Server 2016.
Choisir le type de stockage
Pour obtenir une vue d'ensemble des architectures de stockage et des types de disques, voir Planification et configuration de la capacité de SQL Server et du stockage (SharePoint Server 2016). Les serveurs qui hébergent les composants d'index, de traitement analytique et d'administration de la recherche, ou les bases de données de recherche, requièrent un stockage capable de maintenir une latence faible, tout en permettant de réaliser un nombre suffisant d'opérations d'E/S par seconde (IOPS). Les tableaux suivants indiquent le nombre d'IOPS que chacun de ces composants et bases de données de recherche requièrent.
Si vous déployez un stockage partagé de type SAN/NAS, la charge disque maximale d'un composant de recherche coïncide généralement avec la charge disque maximale d'un autre composant de recherche. Pour obtenir le nombre d’IOPS requises par la recherche dans le cas d’un stockage partagé, vous devez ajouter les besoins en IOPS de chacun de ces composants.
Besoins en IOPS des composants de recherche
| Nom du composant | Détails du composant | Besoins en IOPS | Utilisation de volume/partition de stockage distinct |
|---|---|---|---|
| Composant d'index | Utilise le stockage lors de la fusion de l’index et lors de la gestion et de la réponse aux requêtes. | 300 IOPS pour 64 Ko de lectures aléatoires 100 IOPS pour 256 Ko d’écritures aléatoires 200 Mo/s pour les lectures séquentielles 200 Mo/s pour les écritures séquentielles |
Oui |
| Composant analytique | Analyse les données localement, en traitement en bloc. | Non | Oui |
| Composant d'analyse | Stocke le contenu téléchargé localement, avant de l'envoyer à un composant de traitement de contenu. Le stockage est limité par la bande passante réseau. | Non | Oui |
Besoins en IOPS des bases de données de recherche
| Nom de la base de données | Besoins en IOPS | Charge classique sur le sous-système d'E/S |
|---|---|---|
| Base de données d'analyse | IOPS moyennes à élevées | 10 IOPS pour un taux d’analyse d’1 document par seconde (DPS) |
| Base de données de liens | IOPS moyennes | 10 IOPS pour 1 million d’éléments dans l’index de recherche |
| Base de données d'administration de la recherche | IOPS faibles | Non applicable |
| Base de données de création de rapports d'analyse | IOPS moyennes | Non applicable |
Choisir le mode de prise en charge de la haute disponibilité dans votre architecture de recherche
Si vous connaissez peu les stratégies de haute disponibilité, voici un article qui vous permettra de démarrer : Créer une architecture et une stratégie haute disponibilité pour SharePoint Server. Lorsque vous hébergez des composants et des bases de données de recherche redondants sur des domaines d'erreur distincts, une panne dans une partie de la batterie de serveurs n'arrête pas l'ensemble du service. Cependant, étant donné que les composants de recherche ne peuvent plus partager la charge, les performances de la recherche se dégradent. Pour réduire le risque de perdre un seul serveur, il est judicieux d'améliorer la redondance locale. Pour chaque serveur hôte dans votre architecture de recherche :
Utilisez le stockage RAID sur chaque serveur.
Installez plusieurs connexions réseau redondantes sur chaque serveur.
Installez plusieurs alimentations redondantes avec un câblage indépendant ou un onduleur pour chaque serveur.
Tous les échantillons d'architecture de recherche hébergent des composants de recherche redondants sur des serveurs indépendants. Dans les échantillons d'architecture de recherche, l'hôte le plus à droite dans chaque paire d'hôtes est redondant. Voici l'architecture de recherche de grande taille avec un contour autour des hôtes redondants :