Introduction des clusters Big Data SQL Server
S’applique à :![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Dans SQL Server 2019 (15.x), les Clusters Big Data SQL Server vous permettent de déployer des clusters scalables de conteneurs SQL Server, Spark et HDFS exécutés sur Kubernetes. Ces composants sont exécutés côte à côte pour que vous puissiez lire, écrire et traiter du Big Data à partir de Transact-SQL ou Spark, afin de pouvoir combiner et analyser facilement vos données relationnelles de grande valeur avec du Big Data volumineux.
Prise en main
- Pour commencer, consultez Bien démarrer avec les Clusters Big Data SQL Server
- Pour découvrir les nouvelles fonctionnalités de la dernière version, consultez les notes de publication
- Pour les questions fréquemment posées, consultez les Questions fréquentes (FAQ) sur Clusters Big Data
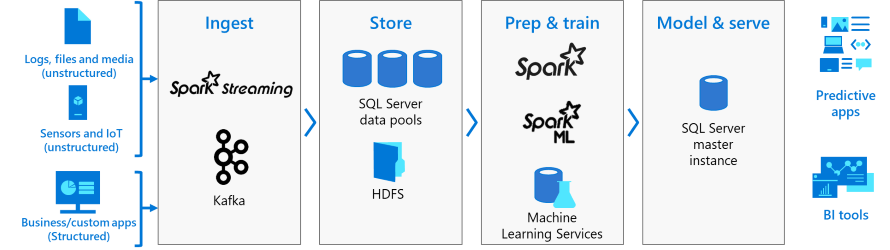
Architecture des clusters Big Data
Le diagramme suivant montre les composants d’un cluster Big Data SQL Server :

Contrôleur
Le contrôleur assure la gestion et la sécurité du cluster. Il contient le service de contrôle, le magasin de configuration et d’autres services de niveau cluster tels que Kibana, Grafana et ElasticSearch.
Pool de calcul
Le pool de calcul fournit des ressources de calcul au cluster. Il contient des nœuds exécutant des pods SQL Server sur Linux. Les pods du pool de calcul sont divisés en instances de calcul SQL pour des tâches de traitement spécifiques.
Pool de données
Le pool de données est utilisé pour la persistance des données. Le pool de données est constitué d’un ou plusieurs pods exécutant SQL Server sur Linux. Il est utilisé pour l’ingestion des données à partir de requêtes SQL ou de travaux Spark.
Pool de stockage
Le pool de stockage est composé de pods de pool de stockage constitués de SQL Server sur Linux, Spark et HDFS. Tous les nœuds de stockage d’un cluster Big Data SQL Server sont membres d’un cluster HDFS.
Conseil
Pour une présentation détaillée de l’architecture et de l’installation des clusters Big Data, consultez Atelier : Architecture des Clusters Big Data Microsoft SQL Server.
Pool d’applications
Le déploiement d’applications sur des clusters Big Data SQL Server s’effectue au moyen d’interfaces conçues pour créer, gérer et exécuter des applications.
Scénarios et fonctionnalités
Les Clusters Big Data SQL Server offrent une certaine flexibilité dans la façon dont vous interagissez avec vos Big Data. Vous pouvez interroger des sources de données externes, stocker du Big Data dans un système HDFS géré par SQL Server ou interroger des données à partir de plusieurs sources de données externes par le biais du cluster. Vous pouvez ensuite utiliser les données pour l’intelligence artificielle, le Machine Learning et d’autres tâches d’analyse.
Utilisez les clusters Big Data SQL Server pour :
- Déployer des clusters scalables de conteneurs SQL Server, Spark et HDFS exécutés sur Kubernetes.
- Lire, écrire et traiter les données du Big Data à partir de Transact-SQL ou de Spark.
- Combiner et analyser facilement des données relationnelles à valeur élevée et un volume important de données du Big Data.
- Interroger des sources de données externes.
- Stocker les données du Big Data dans un système HDFS géré par SQL Server.
- Interroger les données de plusieurs sources de données externes via le cluster.
- Utiliser les données pour l’IA, le machine learning et d’autres tâches d’analyse.
- Déployer et exécuter des applications dans les Clusters Big Data.
- Virtualiser les données avec Polybase. Interroger les données de sources de données SQL Server, Oracle, Teradata, MongoDB et ODBC génériques avec des tables externes.
- Fournir la haute disponibilité pour l’instance principale SQL Server et toutes les bases de données à l’aide de la technologie des groupes de disponibilité Always On.
Les sections ci-dessous fournissent des informations supplémentaires sur ces scénarios.
Virtualisation de données
En tirant parti de Polybase, les Clusters Big Data SQL Server peuvent interroger des sources de données externes sans déplacer ni copier les données. SQL Server 2019 (15.x) introduit de nouveaux connecteurs pour les sources de données. Pour plus d’informations, consultez Nouveautés de PolyBase 2019.
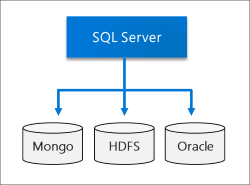
Lac de données
Un cluster Big Data SQL Server comprend un pool de stockage HDFS scalable. Ce dernier peut servir à stocker du Big Data, éventuellement ingéré à partir de plusieurs sources externes. Une fois le Big Data stocké dans HDFS au sein du cluster Big Data, vous pouvez analyser et interroger les données et les combiner avec vos données relationnelles.
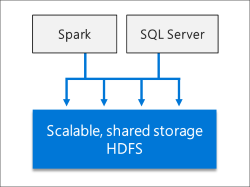
IA et Machine Learning intégrés
Les Clusters Big Data SQL Server autorisent les tâches d’IA et de machine learning sur les données stockées dans les pools de stockage HDFS et les pools de données. Vous pouvez utiliser Spark ainsi que des outils d’IA intégrés dans SQL Server en utilisant R, Python, Scala ou Java.
Gestion et surveillance
La gestion et la supervision sont fournies par le biais d’une combinaison d’outils en ligne de commande, d’API, de portails et de vues de gestion dynamique.
Vous pouvez utiliser Azure Data Studio pour effectuer diverses tâches sur le cluster Big Data :
- Des extraits de code intégrés pour les tâches de gestion courantes
- La possibilité de parcourir le système HDFS, de charger des fichiers, de prévisualiser des fichiers et de créer des répertoires
- La possibilité de créer, d’ouvrir et d’exécuter des notebooks compatibles Jupyter
- Un assistant Virtualisation des données pour simplifier la création de sources de données externes (avec l’extension de virtualisation de données).
Concepts de Kubernetes
Un cluster Big Data SQL Server est un cluster de conteneurs Linux orchestrés par Kubernetes.
Kubernetes est un orchestrateur de conteneurs open source, qui peut mettre à l’échelle des déploiements de conteneurs en fonction des besoins. Le tableau suivant définit certains termes importants liés à Kubernetes :
| Terme | Description |
|---|---|
| Cluster | Un cluster Kubernetes est un ensemble de machines, appelées nœuds. Un des nœuds, appelé nœud master, contrôle le cluster, tandis que les autres nœuds sont des nœuds Worker. Le master Kubernetes est chargé de la distribution du travail entre les Workers et de la supervision de l’intégrité du cluster. |
| Nœud | Un nœud exécute des applications conteneurisées. Il peut s’agir d’une machine physique ou d’une machine virtuelle. Un cluster Kubernetes peut contenir un mélange de nœuds de machine physique et de nœuds de machine virtuelle. |
| Pod | Un pod est l’unité de déploiement atomique de Kubernetes. Un pod regroupe, sous forme logique, un ou plusieurs conteneurs ainsi que les ressources associées nécessaires pour exécuter une application. Chaque pod s’exécute sur un nœud ; un nœud peut exécuter un ou plusieurs pod. Le master Kubernetes attribue automatiquement des pods aux nœuds du cluster. |
Dans les Clusters Big Data SQL Server, Kubernetes est chargé de l’état du cluster. Kubernetes génère et configure les nœuds de cluster, attribue des pods aux nœuds et supervise l’intégrité du cluster.
Étapes suivantes
Pour plus d’informations sur le déploiement des clusters Big Data SQL Server, consultez Bien démarrer avec les clusters Big Data SQL Server.
Ensuite, commencez à charger des données et à exécuter une tâche Spark.
En savoir plus
- Atelier sur l’architecture des clusters Big Data
- REGARDER : Clusters Big Data en bref
- REGARDER : Présentation du Cluster Big Data sur SQL Server 2019 | Virtualisation, Kubernetes et conteneurs
Modules Learn pour les technologies associées :
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour