Envoyer des travaux Spark sur Clusters Big Data SQL Server dans Azure Data Studio
S’applique à : ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Un des principaux scénarios impliquant les clusters Big Data est l’envoi de travaux Spark pour SQL Server. La fonctionnalité d’envoi de travaux Spark vous permet d’envoyer un fichier jar ou py local avec des références au cluster Big Data SQL Server 2019. Elle vous permet également d’exécuter des fichiers jar ou py, qui se trouvent déjà sur le système de fichiers HDFS.
Prérequis
Outils de Big Data SQL Server 2019 :
- Azure Data Studio
- Extension SQL Server 2019
- kubectl
Connectez Azure Data Studio à la passerelle HDFS/Spark de votre cluster Big Data.
Ouvrir la boîte de dialogue d’envoi d’un travail Spark
Vous pouvez ouvrir la boîte de dialogue d’envoi d’un travail Spark de plusieurs façons. Vous avez ainsi le choix entre le tableau de bord, le menu contextuel dans l’Explorateur d’objets et la palette de commandes.
Pour ouvrir la boîte de dialogue d’envoi d’un travail Spark, cliquez sur New Spark Job (Nouveau travail Spark) dans le tableau de bord.
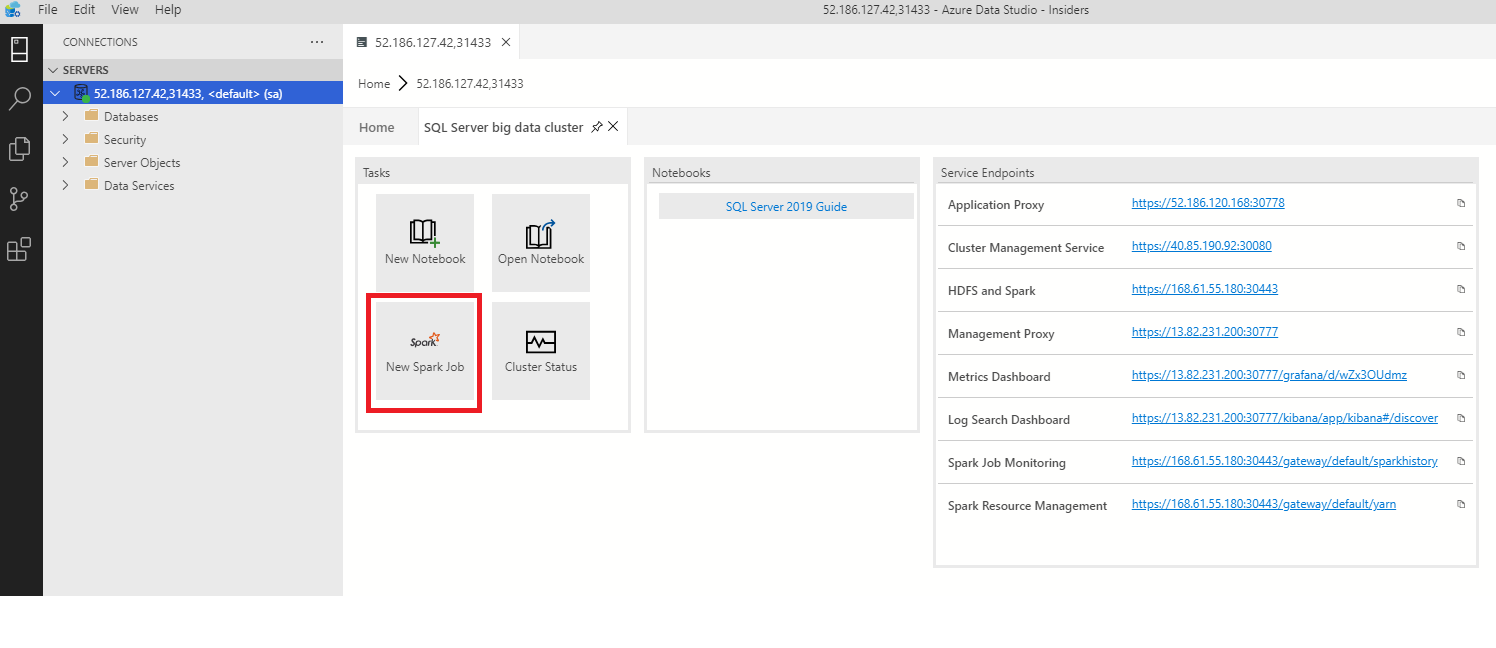
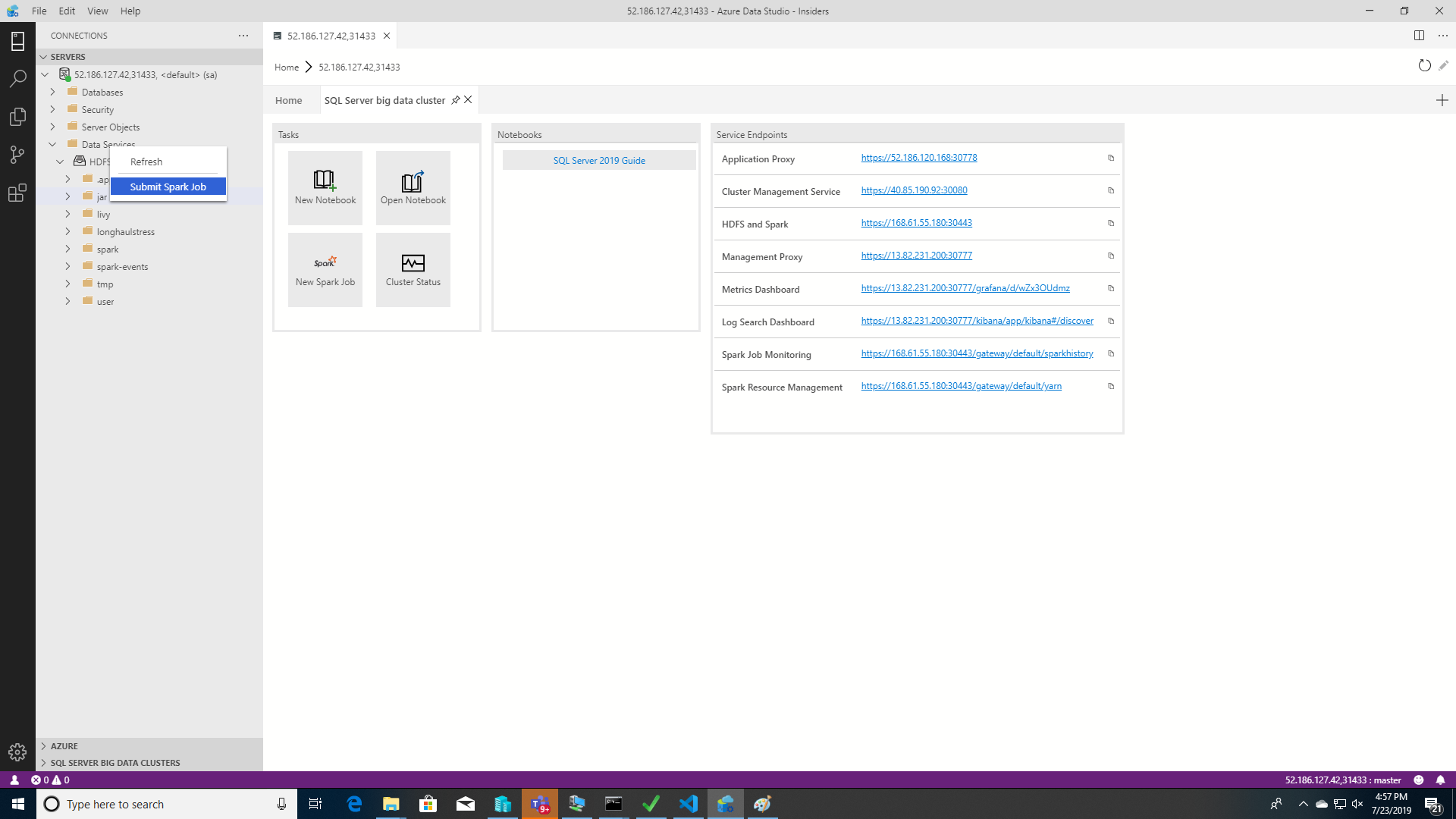
Vous pouvez également cliquer avec le bouton droit sur le cluster dans l’Explorateur d’objets et sélectionner Submit Spark Job dans le menu contextuel.
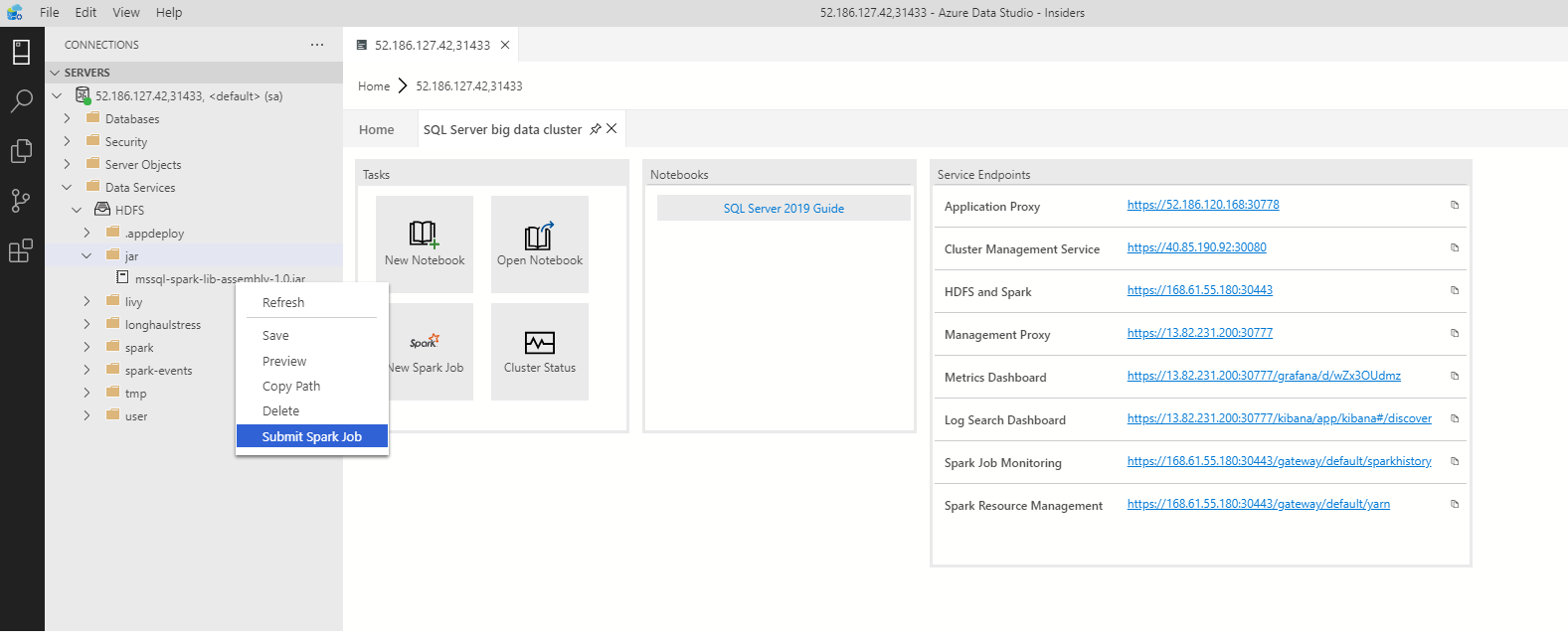
Pour ouvrir la boîte de dialogue d’envoi d’un travail Spark avec les champs Jar/Py préremplis, cliquez avec le bouton droit sur un fichier jar/py dans l’Explorateur d’objets et sélectionnez Submit Spark Job (Envoyer un travail Spark) dans le menu contextuel.
Pour utiliser Submit Spark Job à partir de la palette de commandes, appuyez sur les touches Ctrl+Maj+P (sur Windows) ou Cmd+Maj+P (sur Mac).


Envoyer un travail Spark
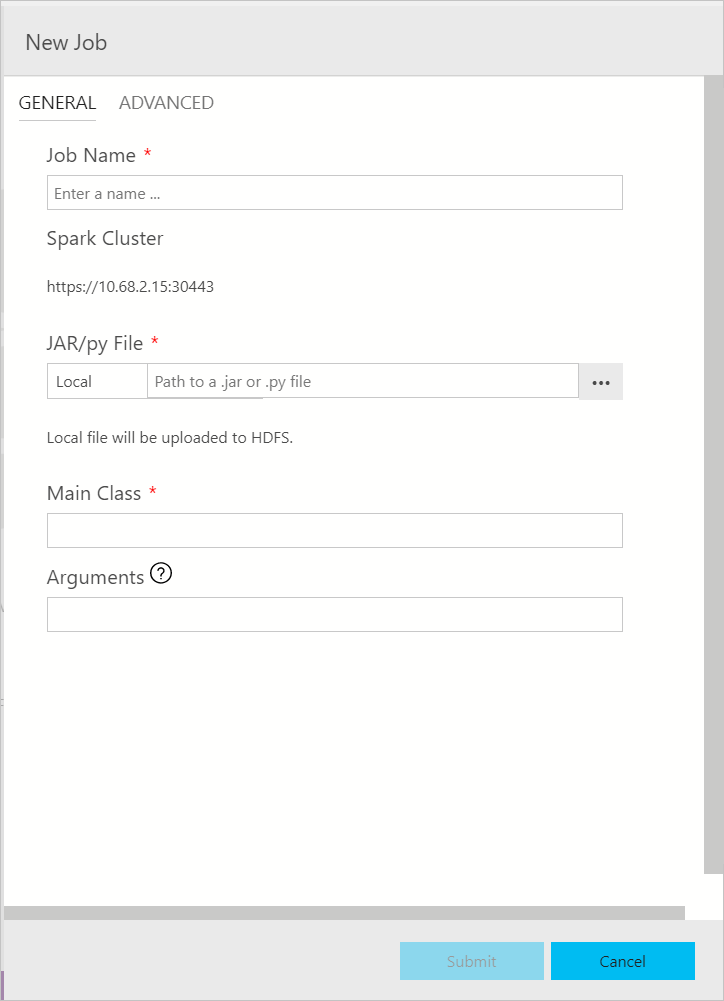
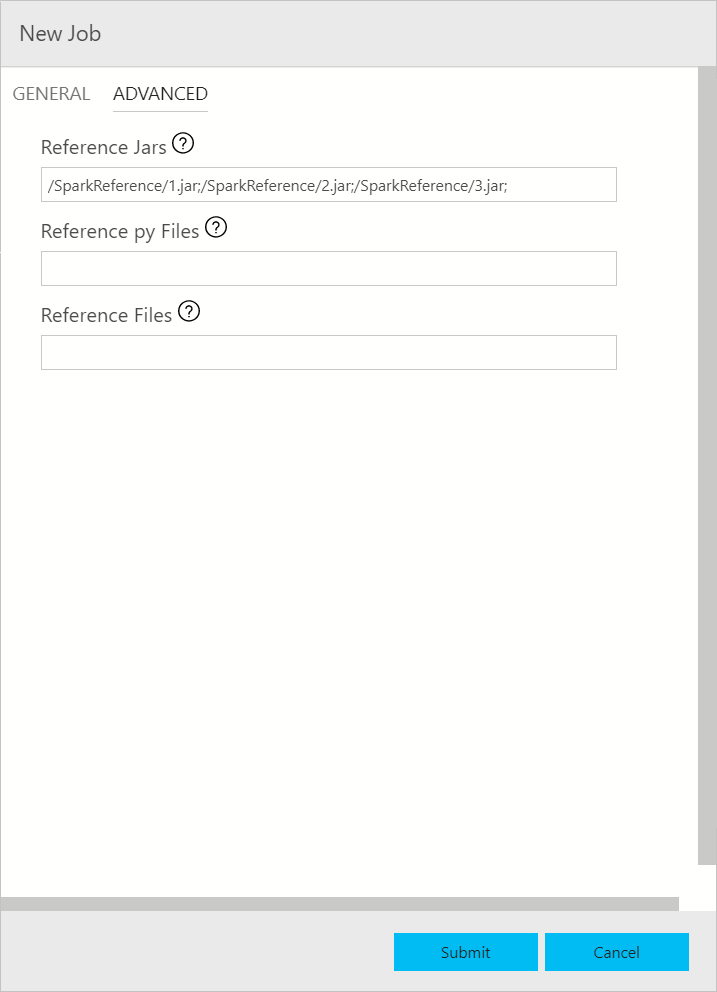
La boîte de dialogue d’envoi d’un travail Spark s’affiche comme suit. Renseignez le nom du travail, le chemin d’accès du fichier Jar/Py, la classe principale et d’autres champs. Le fichier jar/py peut provenir d’une source locale ou de HDFS. Si le travail Spark contient des fichiers jar de référence, des fichiers py ou des fichiers supplémentaires, cliquez sur l’onglet ADVANCED et entrez les chemins correspondants. Cliquez sur Submit pour envoyer le travail Spark.
Superviser l’envoi d’un travail Spark
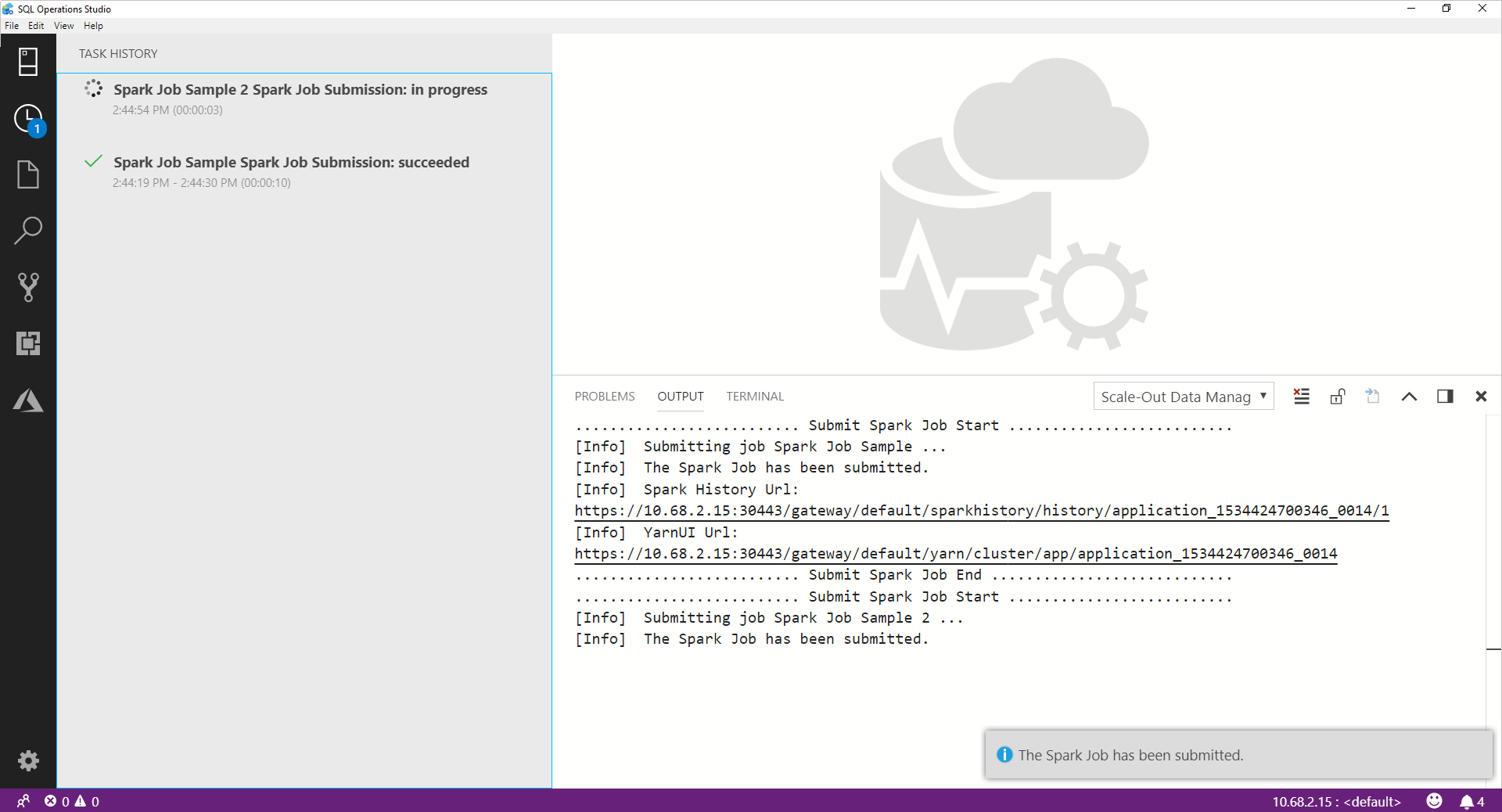
Une fois le travail Spark envoyé, les informations sur l’envoi et l’état d’exécution du travail Spark s’affichent dans Task History (Historique des travaux) à gauche. Des détails sur la progression et les journaux sont également affichés dans la fenêtre OUTPUT en bas.
Quand le travail Spark s’exécute, le volet Task History et la fenêtre OUTPUT sont actualisés avec la progression.
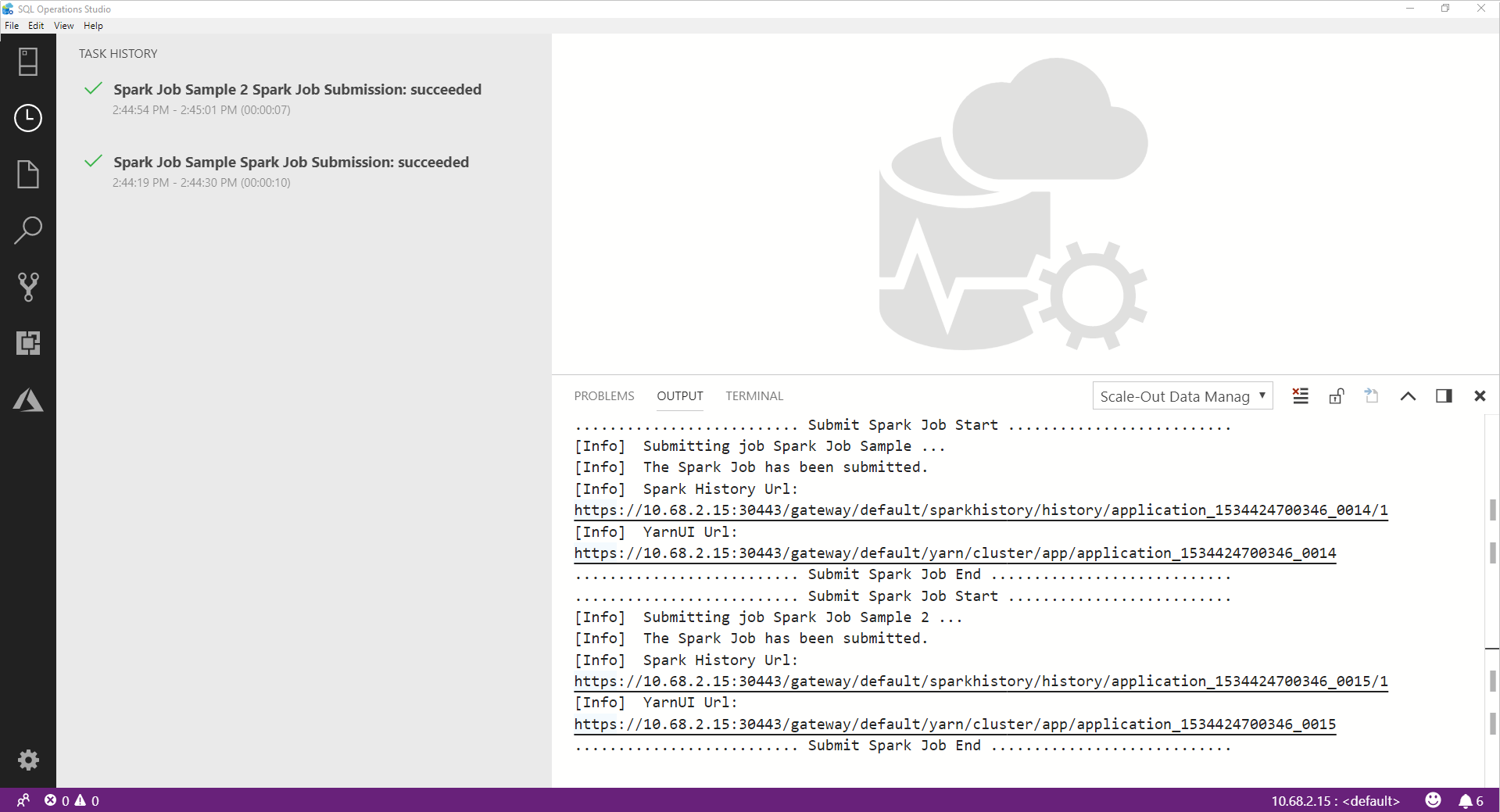
Une fois le travail Spark terminé, les liens vers l’interface utilisateur de Spark et celle de Yarn apparaissent dans la fenêtre OUTPUT. Cliquez sur les liens pour obtenir plus d’informations.
Étapes suivantes
Pour plus d’informations sur le cluster Big Data SQL Server et les scénarios associés, consultez Présentation des Clusters Big Data SQL Server.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour