Présentation du déploiement d’application dans les Clusters Big Data SQL Server
S’applique à : ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Le déploiement d’applications sur des clusters Big Data SQL Server s’effectue au moyen d’interfaces conçues pour créer, gérer et exécuter des applications. Les applications déployées sur un cluster Big Data bénéficient de la puissance de calcul du cluster et peuvent accéder aux données disponibles sur le cluster. Vous augmentez ainsi la scalabilité et les performances des applications tout en gérant les applications où résident les données. Les runtimes d’application pris en charge sur les Clusters Big Data SQL Server sont R, Python, dtexec et MLeap.
Les sections suivantes décrivent l’architecture et les fonctionnalités du déploiement d’application.
Architecture du déploiement d’application
Le déploiement d’application passe par un contrôleur et des gestionnaires d’exécution d’application. Quand vous créez une application, un fichier de spécification (spec.yaml) est fourni. Ce fichier spec.yaml contient tout ce que le contrôleur doit savoir pour déployer correctement l’application. Voici un exemple du contenu de spec.yaml :
#spec.yaml
name: add-app #name of your python script
version: v1 #version of the app
runtime: Python #the language this app uses (R or Python)
src: ./add.py #full path to the location of the app
entrypoint: add #the function that will be called upon execution
replicas: 1 #number of replicas needed
poolsize: 1 #the pool size that you need your app to scale
inputs: #input parameters that the app expects and the type
x: int
y: int
output: #output parameter the app expects and the type
result: int
Le contrôleur inspecte le runtime spécifié dans le fichier spec.yaml et appelle le gestionnaire d’exécution correspondant. Le gestionnaire d’exécution crée l’application. Tout d’abord, un ReplicaSet Kubernetes est créé avec un ou plusieurs pods, chacun d’eux contenant l’application à déployer. Le nombre de pods est défini par le paramètre replicas défini dans le fichier spec.yaml de l’application. Chaque pod peut avoir un ou plusieurs pools. Le nombre de pools est défini par le paramètre poolsize défini dans le fichier spec.yaml.
Ces paramètres déterminent la quantité de demandes que le déploiement peut traiter en parallèle. Le nombre maximal de demandes à un moment donné est égal à replicas fois poolsize. Si vous avez 5 réplicas et 2 pools par réplica, le déploiement peut donc gérer 10 demandes en parallèle. L’image ci-dessous est une représentation graphique de replicas et de poolsize :
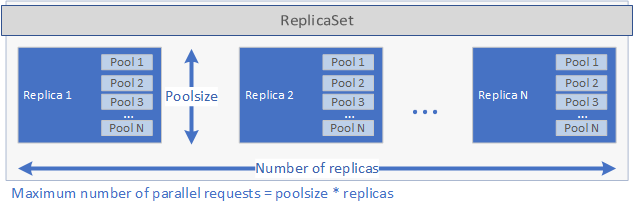
Une fois le ReplicaSet créé et les pods démarrés, un travail cron est créé si un schedule a été défini dans le fichier spec.yaml. Enfin, le service Kubernetes créé peut être utilisé pour gérer et exécuter l’application (voir ci-dessous).
Quand une application est exécutée, le service Kubernetes pour l’application transmet par proxy les demandes à un réplica et retourne les résultats.
Considérations sur la sécurité pour le déploiement d'applications sur OpenShift
SQL Server 2019 CU5 prend en charge le déploiement de BDC sur Red Hat OpenShift et un modèle de sécurité mis à jour pour BDC, si bien que les conteneurs privilégiés ne sont plus nécessaires. Outre les utilisateurs sans privilège, les conteneurs s’exécutent en tant qu’utilisateur non racine par défaut pour tous les nouveaux déploiements avec SQL Server 2019 CU5.
À l’heure où CU5 est publié, l’étape de configuration des applications déployées avec les interfaces de déploiement d’application s’exécute toujours comme utilisateur racine. En effet, c’est à ce moment-là que sont installés les packages supplémentaires utilisés par l’application. Le reste du code utilisateur déployé dans le cadre de l’application s’exécute en tant qu’utilisateur à faibles privilèges.
En outre, CAP_AUDIT_WRITE est une fonctionnalité facultative permettant la planification d’applications SSIS (SQL Server Integration Services) à l’aide de travaux cron. Quand le fichier de spécification yaml de l’application indique une planification, l’application est déclenchée par le biais d’un travail cron, qui nécessite une fonctionnalité supplémentaire. L’application peut également être déclenchée à la demande avec azdata app run via un appel de service web, qui ne nécessite pas la fonctionnalité CAP_AUDIT_WRITE. Notez que la fonctionnalité CAP_AUDIT_WRITE n’est plus nécessaire pour cronjob à compter de la version SQL Server 2019 CU8.
Notes
La contrainte de contexte de sécurité (SCC) personnalisée de l’article sur le déploiement OpenShift n’inclut pas cette fonctionnalité, car elle n’est pas requise par le déploiement par défaut d’un BDC. Pour activer cette fonctionnalité, vous devez d’abord mettre à jour le fichier yaml du SCC personnalisé pour inclure CAP_AUDIT_WRITE.
...
allowedCapabilities:
- SETUID
- SETGID
- CHOWN
- SYS_PTRACE
- AUDIT_WRITE
...
Comment utiliser le déploiement d’application dans un cluster Big Data
Les deux interfaces principales pour le déploiement d’application sont les suivantes :
- Interface de ligne de commande Azure Data CLI (
azdata) - Visual Studio Code et extension Azure Data Studio
Vous pouvez également exécuter une application à l’aide d’un service web RESTful. Pour plus d’informations, consultez Utiliser des applications sur des clusters Big Data.
Scénarios de déploiement d’application
Le déploiement d’applications sur un BDC SQL Server s’effectue au moyen d’interfaces conçues pour créer, gérer et exécuter des applications.
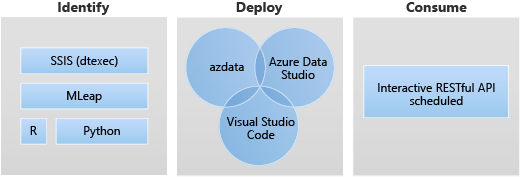
Voici les scénarios cibles pour le déploiement d’application :
- Déployez des services web Python ou R dans le cluster Big Data pour répondre à de nombreux cas d’usage tels que l’inférence Machine Learning, le service d’API, etc.
- Créez un point de terminaison d’inférence Machine Learning avec le moteur MLeap.
- Planifiez et exécutez des packages à partir de fichiers DTSX avec l’utilitaire dtexec pour la transformation et le déplacement des données.
Utiliser le runtime Python de déploiement d’application
Dans le déploiement d’application, le runtime Python du cluster Big Data permet à l’application Python à l’intérieur du cluster Big Data de répondre à de nombreux cas d’usage tels que l’inférence Machine Learning et le service d’API.
L'application déployant le runtime Python utilise Python 3.8 sur les Clusters Big Data SQL Server CU10+.
Dans le déploiement d’application, c’est dans spec.yaml que vous fournissez les informations que le contrôleur doit connaître pour déployer votre application. Les champs suivants peuvent être spécifiés :
name: nom de l’applicationversion: version de l’application, par exemplev1runtime: runtime de déploiement d’application, que vous devez spécifier ainsi :Pythonsrc: chemin de l’application Pythonentry point: fonction de point d’entrée dans le script src à exécuter pour cette application Python.
Outre les données ci-dessus, vous devez spécifier l’entrée et la sortie de votre application Python. Vous obtenez ainsi un fichier spec.yaml similaire à ce qui suit :
#spec.yaml
name: add-app
version: v1
runtime: Python
src: ./add.py
entrypoint: add
replicas: 1
poolsize: 1
inputs:
x: int
y: int
output:
result: int
Vous pouvez créer le dossier de base et la structure de fichiers nécessaires au déploiement d’une application Python s’exécutant sur des clusters Big Data :
azdata app init --template python --name hello-py --version v1
Pour les étapes suivantes, consultez Comment déployer une application sur un cluster Big Data SQL Server.
Limitations du runtime Python de déploiement d’application
Le runtime Python de déploiement d’application ne prend pas en charge le scénario de planification. Une fois l'application Python déployée et exécutée dans BDC, un point de terminaison RESTful est configuré pour écouter les demandes entrantes.
Utiliser le runtime R de déploiement d’application
Dans le déploiement d’application, le runtime Python du cluster Big Data permet à l’application R à l’intérieur du cluster Big Data de répondre à de nombreux cas d’usage tels que l’inférence Machine Learning et le service d’API.
L'application déployant le runtime R utilise Microsoft R Open (MRO) version 3.5.2 sur les Clusters Big Data SQL Server CU10+.
Comment l’utiliser ?
Dans le déploiement d’application, c’est dans spec.yaml que vous fournissez les informations que le contrôleur doit connaître pour déployer votre application. Les champs suivants peuvent être spécifiés :
name: nom de l’applicationversion: version de l’application, par exemplev1runtime: runtime de déploiement d’application, que vous devez spécifier ainsi :Rsrc: chemin de l’application Rentry point: point d’entrée pour exécuter cette application R
Outre les données ci-dessus, vous devez spécifier l’entrée et la sortie de votre application R. Vous obtenez ainsi un fichier spec.yaml similaire à ce qui suit :
#spec.yaml
name: roll-dice
version: v1
runtime: R
src: ./roll-dice.R
entrypoint: rollEm
replicas: 1
poolsize: 1
inputs:
x: integer
output:
result: data.fram
Vous pouvez créer le dossier de base et la structure de fichiers nécessaires au déploiement d’une nouvelle application R à l’aide de la commande suivante :
azdata app init --template r --name hello-r --version v1
Pour les étapes suivantes, consultez Comment déployer une application sur un cluster Big Data SQL Server.
Limitations du runtime R
Ces limitations s’alignent sur le réseau d’applications Microsoft R, qui a été mis hors service le 1er juillet 2023. Pour plus d’informations et de solutions alternatives, consultez Mise hors service du réseau d’applications Microsoft R.
Utiliser le runtime dtexec de déploiement d’application
Dans le déploiement d’application, le runtime Big Data Cluster a intégré l’utilitaire dtexec provenant de SSIS sur Linux (mssql-server-is). Le déploiement d’application utilise l’utilitaire dtexec pour charger des packages à partir de fichiers *.dtsx. Il prend en charge l’exécution de packages SSIS selon une planification de type cron ou à la demande par le biais de demandes de service web.
Cette fonctionnalité utilise /opt/ssis/bin/dtexec /FILE à partir de SQL Server 2019 Integration Service sur Linux. Elle prend en charge le format dtsx pour SQL Server 2019 Integration Service sur Linux (mssql-server-is 15.0.2). Pour en découvrir plus sur l’utilitaire dtexec, consultez Utilitaire dtexec.
Dans le déploiement d’application, c’est dans spec.yaml que vous fournissez les informations que le contrôleur doit connaître pour déployer votre application. Les champs suivants peuvent être spécifiés :
name: applicationnameversion: version de l’application, par exemplev1runtime: runtime de déploiement d’application, pour exécuter l’utilitaire dtexec, que vous devez spécifier ainsi :SSISentrypoint: spécifiez un point d’entrée ; en l’occurrence, il s’agit généralement du fichier .dtsx.options: spécifiez des options supplémentaires pour/opt/ssis/bin/dtexec /FILE; par exemple, pour vous connecter à une base de données avec une chaîne de connexion, vous devriez adopter le modèle suivant :/REP V /CONN "sqldatabasename"\;"\"Data Source=xx;User ID=xx;Password=<password>\""Pour plus d’informations sur la syntaxe, consultez Utilitaire dtexec.
schedule: spécifiez la fréquence d’exécution du travail, par exemple, en cas d’utilisation d’une expression cron, cette valeur est spécifiée au format « */1 * * * * », ce qui signifie que le travail est exécuté chaque minute.
Vous pouvez créer le dossier de base et la structure de fichiers nécessaires au déploiement d’une nouvelle application SSIS à l’aide de la commande suivante :
azdata app init --name hello-is –version v1 --template ssis
Vous obtenez ainsi un fichier spec.yaml similaire à ce qui suit :
#spec.yaml
entrypoint: ./hello.dtsx
name: hello-is
options: /REP V
poolsize: 2
replicas: 2
runtime: SSIS
schedule: '*/2 * * * *'
version: v1
Il en résulte également un exemple de package hello.dtsx.
Tous les fichiers de votre application se trouvent dans le même répertoire que votre fichier spec.yaml. Le fichier spec.yaml doit se trouver au niveau racine du répertoire du code source de votre application incluant le fichier dtsx.
Pour les étapes suivantes, consultez Comment déployer une application sur un cluster Big Data SQL Server.
Limitations du runtime de l’utilitaire dtexec
Toutes les limitations et tous les problèmes connus pour SQL Server Integration Services (SSIS) sur Linux s’appliquent aux Clusters Big Data SQL Server. Pour plus d’informations, consultez Limitations et problèmes connus pour SSIS sur Linux.
Utiliser le runtime MLeap de déploiement d’application
Le runtime MLeap de déploiement d’application prend en charge MLeap Serving v0.13.0.
Dans le déploiement d’application, c’est dans spec.yaml que vous fournissez les informations que le contrôleur doit connaître pour déployer votre application. Les champs suivants peuvent être spécifiés :
name: nom de l’applicationversion: version de l’application, par exemplev1runtime: runtime de déploiement d’application, que vous devez spécifier ainsi :Mleap
Hormis les données ci-dessus, vous devez spécifier le bundleFileName de votre application MLeap. Vous obtenez ainsi un fichier spec.yaml similaire à ce qui suit :
#spec.yaml
name: mleap-census
version: v1
runtime: Mleap
bundleFileName: census-bundle.zip
replicas: 1
Vous pouvez créer le dossier de base et la structure de fichiers nécessaires au déploiement d’une nouvelle application MLeap à l’aide de la commande suivante :
azdata app init --template mleap --name hello-mleap --version v1
Pour les étapes suivantes, consultez Comment déployer une application sur un cluster Big Data SQL Server.
Limitations du runtime MLeap
Les limitations s’alignent sur la vision du projet open source MLeap Combust sur GitHub.
Étapes suivantes
Pour en savoir plus sur la création et l’exécution d’applications sur les Clusters Big Data SQL Server, consultez les rubriques suivantes :
- Déployer des applications avec azdata
- Déployer des applications à l’aide de l’extension de déploiement d’application
- Utiliser des applications sur des clusters Big Data
Pour plus d’informations sur les Clusters Big Data SQL Server, consultez la vue d’ensemble suivante :