Tutoriel : Interroger HDFS dans un cluster Big Data SQL Server
S’applique à : ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
Ce tutoriel montre comment interroger des données HDFS dans un Clusters de Big Data SQL Server 2019.
Dans ce tutoriel, vous allez apprendre à :
- Créer une table externe pointant vers des données HDFS dans un cluster Big Data.
- Associer ces données à des données à valeur élevée dans l’instance maître.
Conseil
Si vous préférez, vous pouvez télécharger et exécuter un script pour les commandes de ce tutoriel. Pour obtenir des instructions, consultez les exemples de virtualisation de données sur GitHub.
Cette vidéo de 7 minutes vous guide tout au long de l’interrogation des données HDFS dans un cluster Big Data :
Prérequis
- Outils Big Data
- kubectl
- Azure Data Studio
- Extension SQL Server 2019
- Charger des exemples de données dans votre cluster Big Data
Créer une table externe pour HDFS
Le pool de stockage contient des données de parcours web dans un fichier CSV stocké dans HDFS. Procédez comme suit pour définir une table externe qui peut accéder aux données dans ce fichier.
Dans Azure Data Studio, connectez-vous à l’instance maître SQL Server de votre cluster Big Data. Pour plus d’informations, consultez Se connecter à l’instance maître SQL Server.
Double-cliquez sur la connexion dans la fenêtre Serveurs pour afficher le tableau de bord de serveur de l’instance maître SQL Server. Sélectionnez Nouvelle requête.
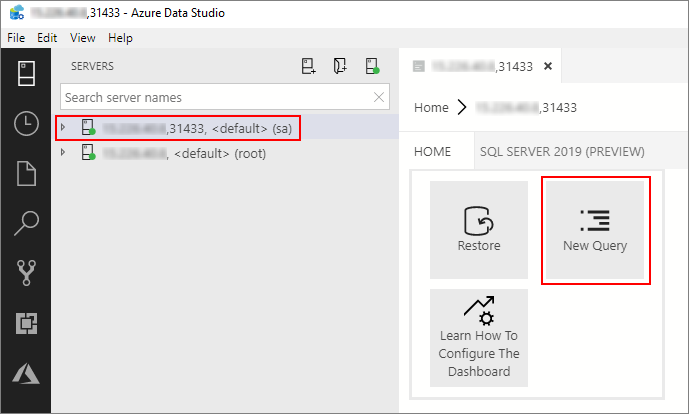
Exécutez la commande Transact-SQL suivante pour remplacer le contexte par celui de la base de données Sales dans l’instance maître.
USE Sales GODéfinissez le format du fichier CSV à lire à partir de HDFS. Appuyez sur la touche F5 pour exécuter l’instruction.
CREATE EXTERNAL FILE FORMAT csv_file WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS( FIELD_TERMINATOR = ',', STRING_DELIMITER = '"', FIRST_ROW = 2, USE_TYPE_DEFAULT = TRUE) );Créez une source de données externe pour le pool de stockage, si elle n’existe pas déjà.
IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlStoragePool') BEGIN CREATE EXTERNAL DATA SOURCE SqlStoragePool WITH (LOCATION = 'sqlhdfs://controller-svc/default'); ENDCréez une table externe capable de lire les
/clickstream_dataà partir du pool de stockage. SqlStoragePool est accessible à partir de l’instance maître d’un cluster Big Data.CREATE EXTERNAL TABLE [web_clickstreams_hdfs] ("wcs_click_date_sk" BIGINT , "wcs_click_time_sk" BIGINT , "wcs_sales_sk" BIGINT , "wcs_item_sk" BIGINT , "wcs_web_page_sk" BIGINT , "wcs_user_sk" BIGINT) WITH ( DATA_SOURCE = SqlStoragePool, LOCATION = '/clickstream_data', FILE_FORMAT = csv_file ); GO
Interroger les données
Exécutez la requête suivante pour associer les données HDFS de la table externe web_clickstream_hdfs aux données relationnelles de la base de données Sales locale.
SELECT
wcs_user_sk,
SUM( CASE WHEN i_category = 'Books' THEN 1 ELSE 0 END) AS book_category_clicks,
SUM( CASE WHEN i_category_id = 1 THEN 1 ELSE 0 END) AS [Home & Kitchen],
SUM( CASE WHEN i_category_id = 2 THEN 1 ELSE 0 END) AS [Music],
SUM( CASE WHEN i_category_id = 3 THEN 1 ELSE 0 END) AS [Books],
SUM( CASE WHEN i_category_id = 4 THEN 1 ELSE 0 END) AS [Clothing & Accessories],
SUM( CASE WHEN i_category_id = 5 THEN 1 ELSE 0 END) AS [Electronics],
SUM( CASE WHEN i_category_id = 6 THEN 1 ELSE 0 END) AS [Tools & Home Improvement],
SUM( CASE WHEN i_category_id = 7 THEN 1 ELSE 0 END) AS [Toys & Games],
SUM( CASE WHEN i_category_id = 8 THEN 1 ELSE 0 END) AS [Movies & TV],
SUM( CASE WHEN i_category_id = 9 THEN 1 ELSE 0 END) AS [Sports & Outdoors]
FROM [dbo].[web_clickstreams_hdfs]
INNER JOIN item it ON (wcs_item_sk = i_item_sk
AND wcs_user_sk IS NOT NULL)
GROUP BY wcs_user_sk;
GO
Nettoyer
Utilisez la commande suivante pour supprimer la table externe utilisée dans ce tutoriel.
DROP EXTERNAL TABLE [dbo].[web_clickstreams_hdfs];
GO
Étapes suivantes
Passez à l’article suivant pour découvrir comment interroger Oracle à partir d’un cluster Big Data.