Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Base de données SQL dans Microsoft Fabric
Base de données SQL dans Microsoft Fabric
La conception d’index efficaces est essentielle pour atteindre de bonnes performances de base de données et d’application. Un manque d’index, de sur-indexation ou d’index mal conçus sont des sources principales de problèmes de performances de base de données.
Ce guide décrit l’architecture et les principes de base de l’index et fournit les meilleures pratiques pour vous aider à concevoir des index efficaces pour répondre aux besoins de vos applications.
Pour plus d’informations sur les types d’index disponibles, consultez Index.
Ce guide couvre les types d’index suivants :
| Format de stockage principal | Type d’index |
|---|---|
| Rowstore sur disque | |
| Clustered | |
| Nonclustered | |
| Unique | |
| Filtered | |
| Columnstore | |
| Columnstore en cluster | |
| Columnstore non-clustérisé | |
| Memory-optimized | |
| Hash | |
| Mémoire optimisée non-clusterisé |
Pour plus d’informations sur les index XML, consultez Index XML (SQL Server) et Index XML sélectifs (SXI).
Pour plus d’informations sur les index spatiaux, consultez Vue d’ensemble des index spatiaux.
Pour plus d'informations sur les index de recherche en texte intégral, consultez Alimenter des index de recherche en texte intégral.
Principes de base de l’index
Pensez à un livre ordinaire : à la fin du livre, il existe un index qui permet de rechercher rapidement les informations dans le livre. L’index est une liste triée de mots clés, chacun accompagné d’un ensemble de numéros de page pointant vers les pages où il se trouve.
Un index rowstore est similaire : il s’agit d’une liste ordonnée de valeurs et pour chaque valeur, il existe des pointeurs vers les pages de données où se trouvent ces valeurs. L’index lui-même est également stocké sur les pages, appelées pages d’index. Dans un livre normal, si l’index s’étend sur plusieurs pages et que vous devez rechercher des pointeurs vers toutes les pages qui contiennent le mot SQL par exemple, vous devrez parcourir à partir du début de l’index jusqu’à ce que vous localisiez la page d’index qui contient le mot clé SQL. À partir de là, vous suivez les pointeurs vers toutes les pages du livre. Cela peut être optimisé si, au tout début de l’index, vous créez une page unique qui contient une liste alphabétique de chaque lettre. Par exemple : « A à D – page 121 », « E à G – page 122 », et ainsi de suite. Cette page supplémentaire évite de feuilleter l’index pour rechercher le point de départ. Une telle page n'existe pas dans les livres ordinaires, mais elle existe dans un index rowstore. Cette page unique est appelée page racine de l’index. La page racine est la page de démarrage de l’arborescence utilisée par un index. En suivant l’analogie de l’arborescence, les pages de fin qui contiennent des pointeurs vers les données réelles sont appelées « pages feuilles » de l’arborescence.
Un index est une structure sur disque ou en mémoire associée à une table ou à une vue qui accélère l’extraction des lignes de la table ou de la vue. Un index rowstore contient des clés générées à partir des valeurs d’une ou de plusieurs colonnes de la table ou de la vue. Pour les index rowstore, ces clés sont stockées dans une arborescence (arborescence B+) qui permet au moteur de base de données de rechercher les lignes associées aux valeurs de clé rapidement et efficacement.
Un index rowstore stocke les données organisées logiquement en tant que table avec des lignes et des colonnes, et stockées physiquement dans un format de données de ligne appelé rowstore1. Il existe une autre méthode pour stocker les colonnes de données, appelée columnstore.
La conception des index appropriés pour une base de données et sa charge de travail est un acte d’équilibrage complexe entre la vitesse de requête, le coût de mise à jour d’index et le coût de stockage. Les index rowstore basés sur disque qui sont étroits, ou qui ont peu de colonnes dans la clé d'index, nécessitent moins d'espace de stockage et ont un surcoût de mise à jour plus réduit. Les index larges, d’autre part, peuvent améliorer davantage de requêtes. Vous devrez peut-être expérimenter plusieurs conceptions différentes avant de trouver l’ensemble d’index le plus efficace. À mesure que l’application évolue, les index peuvent avoir besoin de changer pour maintenir des performances optimales. Les index peuvent être ajoutés, modifiés et supprimés sans affecter le schéma de base de données ou la conception d’application. Par conséquent, n'hésitez à faire des essais avec différents index.
L’optimiseur de requête dans le moteur de base de données choisit généralement les index les plus efficaces pour exécuter une requête. Pour voir quels index l’optimiseur de requête utilise pour une requête spécifique, dans SQL Server Management Studio, dans le menu Requête , sélectionnez Afficher le plan d’exécution estimé ou Inclure le plan d’exécution réel.
L’utilisation d’index n’est pas forcément synonyme de bonnes performances, et inversement, de bonnes performances ne sauraient être nécessairement attribuables à l’utilisation d’index efficaces. Si l'utilisation d'un index contribuait toujours à produire les meilleurs résultats, le travail de l'optimiseur de requête en serait simplifié. En réalité, le choix d'un index inapproprié peut aboutir à des performances moins que satisfaisantes. Par conséquent, la tâche de l’optimiseur de requête consiste à sélectionner un index ou une combinaison d’index, uniquement lorsqu’il améliore les performances et pour éviter la récupération indexée lorsqu’il entrave les performances.
Une erreur de conception courante consiste à créer de nombreux index spéculatifs pour « donner les choix de l’optimiseur ». La surindexation résultante ralentit les modifications de données et peut entraîner des problèmes d’accès concurrentiel.
1 Rowstore est la méthode standard de stockage des données de table relationnelles. Rowstore fait référence à une table où le format de stockage de données sous-jacent est un tas, une arborescence B+ (index cluster) ou une table optimisée en mémoire. Un rowstore sur disque exclut les tables à mémoire optimisée.
Tâches de conception d’index
La stratégie de conception d’index que nous recommandons est constituée des tâches suivantes :
Comprendre les caractéristiques de la base de données et de l’application.
Par exemple, dans une base de données OLTP (Online Transaction Processing) avec des modifications fréquentes des données qui doivent maintenir un débit élevé, quelques index rowstore étroits ciblés pour les requêtes les plus critiques seraient une bonne conception d’index initiale. Pour un débit extrêmement élevé, envisagez des tables et des index à mémoire optimisée, qui offrent une conception sans verrouillage et sans verrou. Pour plus d’informations, consultez les directives de conception d’index non-clusteré optimisées en mémoire et les directives de conception d’index de hachage dans ce guide.
À l’inverse, pour une base de données d’analytique ou d’entreposage de données (OLAP) qui doit traiter des jeux de données très volumineux de manière rapide, l’utilisation d’indexes columnstore en cluster serait particulièrement appropriée. Pour plus d’informations, consultez les index Columnstore : vue d’ensemble ou architecture d’index Columnstore dans ce guide.
Comprendre les caractéristiques des requêtes les plus fréquemment utilisées.
Par exemple, savoir qu’une requête fréquemment utilisée joint deux tables ou plus vous permet de déterminer l’ensemble d’index pour ces tables.
Comprendre la distribution des données dans les colonnes utilisées dans les prédicats de requête.
Par exemple, un index peut être utile pour les colonnes avec de nombreuses valeurs de données distinctes, mais moins pour les colonnes avec de nombreuses valeurs en double. Pour les colonnes avec de nombreuses valeurs NULL ou celles qui ont des sous-ensembles de données bien définis, vous pouvez utiliser un index filtré. Pour plus d'informations, consultez Instructions de conception d’index filtrés dans ce guide.
Déterminez les options d’index qui peuvent améliorer les performances.
Par exemple, la création d’un index cluster sur une table volumineuse existante peut tirer parti de l’option d’index
ONLINE. L’optionONLINEpermet la poursuite des activités concurrentes sur les données sous-jacentes pendant la création ou la reconstruction de l’index. L’utilisation de la compression des données de ligne ou de page peut améliorer les performances en réduisant l’empreinte E/S et mémoire de l’index. Pour plus d’informations, consultez CREATE INDEX.Examinez les index existants sur la table pour empêcher la création d’index dupliqués ou très similaires.
Il est souvent préférable de modifier un index existant que de créer un index nouveau mais essentiellement redondant. Par exemple, envisagez d’ajouter une ou deux colonnes supplémentaires incluses à un index existant, au lieu de créer un index avec ces colonnes. Cela est particulièrement pertinent lorsque vous paramétrez des index non clusterisés avec des suggestions d’index manquants, ou si vous utilisez l’Assistant de paramétrage du moteur de base de données, où il vous sera proposé des variantes similaires d’index sur la même table et les mêmes colonnes.
Recommandations générales pour la conception d'index
Comprendre les caractéristiques de votre base de données, requêtes et colonnes de table peut vous aider à concevoir des index optimaux initialement et à modifier la conception à mesure que vos applications évoluent.
Considérations relatives à la base de données
Lorsque vous créez un index, prenez en compte les directives suivantes relatives aux bases de données :
Un grand nombre d’index sur une table affecte les performances des instructions
INSERT,UPDATE,DELETE, etMERGE, car les données dans les index doivent parfois changer en fonction des changements des données de la table. Par exemple, si une colonne est utilisée dans plusieurs index et que vous exécutez uneUPDATEinstruction qui modifie les données de cette colonne, chaque index qui contient cette colonne doit également être mis à jour.Évitez que les tables mises à jour ne soient trop abondamment indexées et faites en sorte que les index soient étroits, c'est-à-dire qu'ils comprennent le moins de colonnes possible.
Vous pouvez avoir plus d’index sur des tables qui ont peu de modifications de données, mais de grands volumes de données. Pour ces tables, un large éventail d’index peut aider à interroger les performances tandis que la surcharge de mise à jour d’index reste acceptable. Toutefois, ne créez pas d’index de façon spéculative. Surveillez l’utilisation des index et supprimez les index inutilisés au fil du temps.
L’indexation de petites tables peut ne pas être optimale, car le moteur de base de données peut prendre plus de temps pour parcourir l’index recherchant des données que pour effectuer une analyse de table de base. Par conséquent, les index sur de petites tables ne peuvent jamais être utilisés, mais doivent toujours être mis à jour à mesure que les données de la table sont mises à jour.
Les index sur les vues peuvent fournir des gains de performances significatifs lorsque la vue contient des agrégations et/ou des jointures. Pour plus d’informations, consultez Créer des vues indexées.
Les bases de données sur les réplicas principaux dans Azure SQL Database génèrent automatiquement des recommandations relatives aux performances de Database Advisor pour les index. Vous pouvez éventuellement activer le réglage automatique des index.
Le Magasin des requêtes permet d’identifier les requêtes avec des performances non optimales et fournit un historique des plans d’exécution de requête qui vous permettent de voir les index sélectionnés par l’optimiseur. Vous pouvez utiliser ces données pour apporter les modifications de réglage des index les plus impactantes en mettant l’accent sur les requêtes les plus fréquentes et consommatrices de ressources.
Considérations relatives aux requêtes
Lorsque vous créez un index, prenez en compte les directives suivantes relatives aux requêtes :
Créez des indexs non clusterisés sur les colonnes fréquemment utilisées dans les prédicats et les expressions de jointure dans les requêtes. Ces sont vos colonnes SARGable. Toutefois, vous devez éviter d’ajouter une colonne inutile aux index. L’ajout d’un trop grand nombre de colonnes d’index peut affecter l’espace disque et les performances des mises à jour d’index.
Le terme SARGable dans les bases de données relationnelles fait référence à un prédicat Search ARGumentable, capable d’utiliser un index pour accélérer l’exécution de la requête. Pour plus d’informations, consultez le guide de l’architecture et de la conception d’index pour SQL Server et Azure SQL.
Tip
Vérifiez toujours que les index que vous créez sont réellement utilisés par la charge de travail de requête. Supprimez les index inutilisés.
Les statistiques d’utilisation des index sont disponibles dans sys.dm_db_index_usage_stats et sys.dm_db_index_operational_stats.
La couverture des index peut améliorer les performances des requêtes, car toutes les données nécessaires pour répondre aux exigences de la requête existent dans l'index proprement dit. Cela signifie que seules les pages d'index, et non les pages de données de la table ou de l'index cluster, sont nécessaires pour récupérer les données demandées, réduisant ainsi globalement le nombre d'E/S des disques. Par exemple, une requête de colonnes
AetBsur une table avec un index composite créé sur les colonnesA,BetCpeut récupérer les données spécifiées à partir de l’index uniquement.Note
Un index de couverture est un index non cluster qui satisfait à tous les accès aux données par une requête directement sans accéder à la table de base.
Ces index ont toutes les colonnes SARGables nécessaires dans la clé d’index et les colonnes non SARGables comme colonnes incluses . Cela signifie que toutes les colonnes requises par la requête, que ce soit dans les clauses
WHERE,JOIN, etGROUP BY, ou dans les clausesSELECTouUPDATE, sont présentes dans l’index.Il y a potentiellement beaucoup moins d’E/S pour exécuter la requête, si l’index est suffisamment restreint par rapport aux lignes et aux colonnes de la table elle-même, ce qui signifie qu’il s’agit d’un petit sous-ensemble de l'ensemble des colonnes.
Envisagez de couvrir les index lors de la récupération d’une petite partie d’une table volumineuse et où cette petite partie est définie par un prédicat fixe.
Évitez de créer un index couvrant avec trop de colonnes, car cela réduit son avantage lors de l’inflation du stockage de base de données, des E/S et de l’empreinte mémoire.
Rédigez des requêtes insérant ou modifiant un maximum de lignes en une seule instruction, plutôt que de recourir à plusieurs requêtes pour mettre à jour les mêmes lignes. Cela réduit la surcharge de mise à jour d’index.
Considérations relatives aux colonnes
Lorsque vous créez un index, prenez en compte les directives suivantes relatives aux colonnes :
Conservez la longueur de la clé d’index courte, en particulier pour les index cluster.
Les colonnes qui sont des types de données ntext, text, image, varchar(max), nvarchar(max), varbinary(max), json et vector ne peuvent pas être spécifiées en tant que colonnes clés d’index. Toutefois, les colonnes avec ces types de données peuvent être ajoutées à un index non cluster en tant que colonnes d’index non clés (incluses). Pour plus d’informations, consultez la section Utiliser les colonnes incluses dans les index non cluster dans ce guide.
Vérifiez l'unicité des colonnes. Un index unique au lieu d’un index non unique sur les mêmes colonnes clés fournit des informations supplémentaires pour l’optimiseur de requête qui rend l’index plus utile. Pour plus d’informations, consultez Instructions de conception d’index uniques dans ce guide.
Examinez la distribution des données dans la colonne. La création d’un index sur une colonne avec de nombreuses lignes, mais peu de valeurs distinctes peuvent ne pas améliorer les performances des requêtes même si l’index est utilisé par l’optimiseur de requête. Par analogie, un répertoire téléphonique physique trié par ordre alphabétique sur le nom de la famille n’accélère pas la localisation d’une personne si toutes les personnes de la ville sont nommées Smith ou Jones. Pour plus d'informations sur la distribution de données, consultez Statistics.
Envisagez d’utiliser des index filtrés sur des colonnes qui ont des sous-ensembles bien définis, par exemple des colonnes avec de nombreuses valeurs NULL, des colonnes avec des catégories de valeurs et des colonnes avec des plages de valeurs distinctes. Un index filtré bien conçu peut améliorer les performances des requêtes, réduire les coûts de mise à jour d’index et réduire les coûts de stockage en stockant un petit sous-ensemble de toutes les lignes de la table si ce sous-ensemble est pertinent pour de nombreuses requêtes.
Considérez l’ordre des colonnes clés d’index si la clé contient plusieurs colonnes. La colonne utilisée dans le prédicat de requête dans une expression d'égalité (
=), de différence (>,>=,<,<=), ou qui participe à une jointure, doit être placée en premier. Les colonnes supplémentaires doivent être classées en fonction de leur niveau de différenciation, c'est-à-dire de la plus distincte à la moins distincte.Par exemple, si l’index est défini comme
LastName,FirstNamel’index est utile lorsque le prédicat de requête dans laWHEREclause estWHERE LastName = 'Smith'ouWHERE LastName = Smith AND FirstName LIKE 'J%'. Toutefois, l’optimiseur de requête n’utilise pas l’index pour une requête qui a recherché uniquement surWHERE FirstName = 'Jane', ou l’index n’améliorerait pas les performances d’une telle requête.Envisagez d’indexer des colonnes calculées si elles sont incluses dans les prédicats de requête. Pour plus d’informations, consultez Index sur les colonnes calculées.
Caractéristiques d’index
Après avoir déterminé qu'un index est approprié pour une requête, vous pouvez sélectionner le type d'index qui convient le mieux à la situation. Les caractéristiques d’index sont les suivantes :
- Cluster ou non-cluster
- Unique ou non unique
- Colonne unique ou multicolonne
- Ordre croissant ou décroissant pour les colonnes clés dans l’index
- Pour les index non clusterisés, toutes les lignes ou filtrées
- Columnstore ou Rowstore
- Hachage ou non-cluster pour les tables optimisées pour la mémoire
Placement d'index sur les groupes de fichiers ou les schémas de partition
Lors du développement de votre stratégie de conception des index, vous devez tenir compte du placement de ces index sur les groupes de fichiers associés à la base de données.
Par défaut, les index sont stockés dans le même groupe de fichiers que la table de base (index cluster ou tas) sur laquelle l’index est créé. D’autres configurations sont possibles, notamment :
Créez des index non cluster sur un groupe de fichiers autre que le groupe de fichiers de la table de base.
partitionner des index cluster et non-cluster pour qu'ils concernent plusieurs groupes de fichiers ;
Pour les tables nonpartitionées, l’approche la plus simple est généralement la meilleure : créez toutes les tables sur le même groupe de fichiers et ajoutez autant de fichiers de données au groupe de fichiers que nécessaire pour utiliser tout le stockage physique disponible.
Des approches de placement d’index plus avancées peuvent être prises en compte lorsque le stockage hiérarchisé est disponible. Par exemple, vous pouvez créer un groupe de fichiers pour les tables fréquemment sollicitées avec des fichiers sur des disques plus rapides et un groupe de fichiers pour les tables d’archivage sur des disques plus lents.
Vous pouvez déplacer une table avec un index cluster d’un groupe de fichiers vers un autre en supprimant l’index cluster et en spécifiant un nouveau groupe de fichiers ou schéma de partition dans la MOVE TO clause de l’instruction DROP INDEX ou en utilisant l’instruction CREATE INDEX avec la DROP_EXISTING clause.
les index partitionnés ;
Vous pouvez également envisager de partitionner des tas basés sur disque, des index clusterisés et non clusterisés sur plusieurs groupes de fichiers. Les index partitionnés sont partitionnés horizontalement (par ligne), en fonction d’une fonction de partition. La fonction de partition définit la façon dont chaque ligne est mappée à une partition en fonction des valeurs d’une colonne que vous désignez, appelée colonne de partitionnement. Un schéma de partition spécifie le mappage d’un ensemble de partitions à un groupe de fichiers.
Le partitionnement d'un index peut présenter les avantages suivants :
Rendre les bases de données volumineuses plus gérables. Les systèmes OLAP, par exemple, peuvent implémenter l’ETL prenant en charge les partitions, ce qui simplifie considérablement l’ajout et la suppression de données en bloc.
Faites en sorte que certains types de requêtes, tels que les requêtes analytiques de longue durée, s’exécutent plus rapidement. Lorsque les requêtes utilisent un index partitionné, le moteur de base de données peut traiter plusieurs partitions en même temps et ignorer (éliminer) les partitions qui ne sont pas nécessaires par la requête.
Avertissement
Le partitionnement améliore rarement les performances des requêtes dans les systèmes OLTP, mais il peut introduire une surcharge significative si une requête transactionnelle doit accéder à de nombreuses partitions.
Pour plus d’informations, consultez Tables et index partitionnés.
Recommandations pour la conception de l'ordre de tri d'index
Lors de la définition d’index, déterminez si chaque colonne de clé d’index doit être stockée dans l’ordre croissant ou décroissant. L'ordre croissant est la valeur par défaut. La syntaxe des instructions CREATE INDEX, CREATE TABLE et ALTER TABLE permet l’application des mot clés ASC (croissant) et DESC (décroissant) à chaque colonne d’un index et d’une contrainte.
La spécification de l’ordre dans lequel les valeurs de clé sont stockées dans un index est utile lorsque les requêtes référençant la table possèdent des clauses ORDER BY qui définissent différents sens pour la ou les colonnes clés de cet index. Dans ces cas, l’index peut supprimer la nécessité d’un opérateurde tri dans le plan de requête.
Par exemple, les acheteurs du service achat de Adventure Works Cycles doivent évaluer la qualité des produits qu'ils acquièrent auprès des fournisseurs. Les acheteurs sont les plus intéressés par la recherche de produits envoyés par les fournisseurs avec un taux de rejet élevé.
Comme le montre la requête suivante sur l’exemple de base de données AdventureWorks, l’extraction des données en fonction de ce critère nécessite que la colonne RejectedQty de la table Purchasing.PurchaseOrderDetail soit triée dans l’ordre décroissant (de la valeur la plus élevée à la valeur la plus faible), et que la colonne ProductID soit triée dans l’ordre croissant (de la valeur la plus faible à la valeur la plus élevée).
SELECT RejectedQty,
((RejectedQty / OrderQty) * 100) AS RejectionRate,
ProductID,
DueDate
FROM Purchasing.PurchaseOrderDetail
ORDER BY RejectedQty DESC, ProductID ASC;
Le plan d’exécution suivant pour cette requête montre que l’optimiseur de requête a utilisé un opérateur de tri pour retourner le jeu de résultats dans l’ordre spécifié par la ORDER BY clause.

Si un index rowstore basé sur disque est créé avec des colonnes clés qui correspondent à celles de la ORDER BY clause de la requête, l’opérateur Sort du plan de requête est éliminé, ce qui rend le plan de requête plus efficace.
CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail
(RejectedQty DESC, ProductID ASC, DueDate, OrderQty);
Une fois la requête réexécutée, le plan d’exécution suivant montre que l’opérateur Sort n’est plus présent et que l’index non cluster nouvellement créé est utilisé.
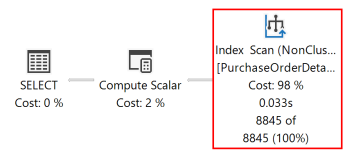
Le moteur de base de données peut analyser un index dans les deux sens. Index défini comme RejectedQty DESC, ProductID ASC pouvant toujours être utilisé pour une requête dans laquelle les directions de tri des colonnes de la ORDER BY clause sont inversées. Par exemple, une requête avec la ORDER BY clause ORDER BY RejectedQty ASC, ProductID DESC peut utiliser le même index.
L’ordre de tri ne peut être spécifié que pour les colonnes clés dans l’index. La vue catalogue sys.index_columns indique si une colonne d’index est stockée dans l’ordre croissant ou décroissant.
instructions sur la conception des index
L’index cluster stocke toutes les lignes et toutes les colonnes d’une table. Les lignes sont triées dans l’ordre des valeurs de clé d’index. Il ne peut y avoir qu’un seul index cluster par table.
La table de base peut faire référence soit à un index clusterisé, soit à un tas. Un tas est une structure de données non triée sur le disque qui contient toutes les lignes et toutes les colonnes d’une table.
Avec quelques exceptions, chaque table doit avoir un index cluster. Les propriétés souhaitables de l’index cluster sont les suivantes :
| Propriété | Descriptif |
|---|---|
| Étroit | La clé de l’index clusterisé fait partie de l’index non clusterisé sur la même table de base. Une clé étroite ou une clé où la longueur totale des colonnes clés est petite, réduit le stockage, les E/S et la surcharge mémoire de tous les index d’une table. Pour calculer la longueur de la clé, ajoutez les tailles de stockage pour les types de données utilisés par les colonnes clés. Pour plus d’informations, consultez catégories de types de données. |
| Unique | Si l’index clusterisé n’est pas unique, une colonne interne de 4 octets est automatiquement ajoutée à la clé d’index pour assurer l’unicité. L’ajout d’une colonne unique existante à la clé d’index en cluster évite la surcharge de stockage, d’E/S et de mémoire de la colonne uniqueifier dans tous les index d’une table. En outre, l’optimiseur de requête peut générer des plans de requête plus efficaces lorsqu’un index est unique. |
| Toujours croissant | Dans un index toujours croissant, les données sont toujours ajoutées sur la dernière page de l’index. Cela évite les fractionnements de pages au milieu de l’index, ce qui réduit la densité de page et diminue les performances. |
| Immuable | La clé d'index clusterisé fait partie de l'index non clusterisé. Lorsqu’une colonne clé d’un index cluster est modifiée, une modification doit également être apportée dans tous les index non cluster, ce qui ajoute une surcharge processeur, journalisation, E/S et mémoire. La surcharge est évitée si les colonnes clés de l’index cluster sont immuables. |
| Ne contient que des colonnes non nullables | Si une ligne a des colonnes nullables, elle doit inclure une structure interne appelée bloc NULL, qui ajoute 3 à 4 octets de stockage par ligne dans un index. Rendre toutes les colonnes de l'index clusterisé non nullables évite cette surcharge. |
| Contient uniquement des colonnes de largeur fixe | Les colonnes utilisant des types de données de largeur variable, tels que varchar ou nvarchar , utilisent un nombre supplémentaire de 2 octets par valeur par rapport aux types de données de largeur fixe. L’utilisation de types de données de largeur fixe comme int évite cette surcharge dans tous les index de la table. |
Satisfaire autant de ces propriétés que possible lors de la conception d’un index clusterisé rend non seulement cet index, mais également tous les index non-clusterisés sur la même table plus efficaces. Les performances sont améliorées en évitant les surcharges de stockage, d’E/S et de mémoire.
Par exemple, une clé d’index cluster avec une seule colonne int ou bigint non nullable a toutes ces propriétés si elle est remplie par une IDENTITY clause ou une contrainte par défaut à l’aide d’une séquence et n’est pas mise à jour après l’insertion d’une ligne.
À l’inverse, une clé d’index cluster avec une seule colonne uniqueidentifier est plus large, car elle utilise 16 octets de stockage au lieu de 4 octets pour int et 8 octets pour bigint, et ne satisfait pas à la propriété en constante augmentation , sauf si les valeurs sont générées séquentiellement.
Tip
Lorsque vous créez une PRIMARY KEY contrainte, un index unique prenant en charge la contrainte est créé automatiquement. Par défaut, cet index est clusterisé ; toutefois, si cet index ne satisfait pas les propriétés souhaitées de l’index clusterisé, vous pouvez créer la contrainte comme non clusterisé et créer un autre index clusterisé à la place.
Si vous ne créez pas d’index clusterisé, la table est stockée en tant qu'amas, ce qui n’est généralement pas recommandé.
Architecture des index cluster
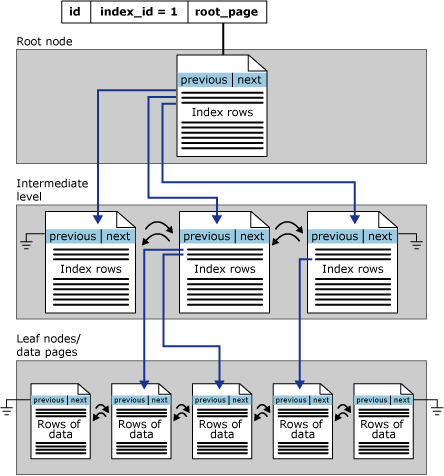
Les index rowstore sont organisés sous la forme d’arbres B+. Chaque page d’un arbre B+ d’index s’appelle un nœud d’index. Le nœud supérieur d’un arbre B+ (B+ tree) est le nœud racine. Les nœuds du niveau inférieur de l'index sont appelés les nœuds feuille. Tous les niveaux d'index situés entre la racine et les nœuds feuille s'appellent des niveaux intermédiaires. Dans un index cluster, les nœuds feuille contiennent les pages de données de la table sous-jacente. Les nœuds racine et de niveau intermédiaire contiennent les pages d'index dans lesquelles se trouvent les lignes d'index. Chaque ligne d’index contient une valeur de clé et un pointeur vers une page de niveau intermédiaire dans l’arbre B+ (B+ tree) ou vers une ligne de données dans le niveau feuille de l’index. Les pages de chaque niveau de l'index sont liées dans une liste doublement liée.
Les index cluster ont une ligne dans sys.partitions pour chaque partition utilisée par l’index, avec index_id = 1. Par défaut, un index cluster possède une seule partition. Lorsqu’un index cluster a plusieurs partitions, chaque partition a une structure d’arborescence B+ distincte qui contient les données de cette partition spécifique. Par exemple, si un index cluster a quatre partitions, il existe quatre structures d’arborescence B+, une dans chaque partition.
Suivant les types de données de l'index cluster, chaque structure d'index cluster possède une ou plusieurs unités d'allocation pour le stockage et la gestion des données d'une partition spécifique. Au minimum, chaque index cluster détient une unité d’allocation IN_ROW_DATA par partition. L’index clusterisé a également une unité d’allocation LOB_DATA par partition, s’il contient des colonnes d’objets volumineux (LOB) telles que nvarchar(max). Il a également une unité d’allocation ROW_OVERFLOW_DATA par partition s’il contient des colonnes de longueur variable qui dépassent la limite de taille de ligne de 8 060 octets.
Les pages de la structure d’arborescence B+ sont classées sur la valeur de la clé d’index clusterisé. Toutes les insertions sont effectuées sur la page où la valeur de clé dans la ligne insérée correspond à la séquence de classement entre les pages existantes. Dans une page, les lignes ne sont pas nécessairement stockées dans un ordre physique. Toutefois, la page gère un ordre logique des lignes à l’aide d’une structure interne appelée tableau d’emplacements. Les entrées du tableau des emplacements sont conservées dans l’ordre de la clé d'indexation.
L'illustration suivante montre la structure d'un index cluster dans une partition unique.
Recommandations pour la conception d'index non-cluster
La principale différence entre un index cluster et un index non cluster est qu’un index non cluster contient un sous-ensemble des colonnes de la table, généralement triés différemment de l’index cluster. Si vous le souhaitez, un index non cluster peut être filtré, ce qui signifie qu’il contient un sous-ensemble de toutes les lignes de la table.
Un indice rowstore non-cluster basé sur disque contient les localisateurs de lignes qui pointent vers l’emplacement de stockage de la ligne dans la table de base. Vous pouvez créer plusieurs index non cluster sur une table ou une vue indexée. En règle générale, les index non cluster doivent être conçus pour améliorer les performances des requêtes fréquemment utilisées qui devront analyser la table de base dans le cas contraire.
De la même manière que vous utilisez un index dans un livre, l'optimiseur de requête recherche une valeur de données en examinant l'index non-cluster afin de trouver l'emplacement qu'occupe la valeur dans la table, puis récupère directement les données à partir de cet emplacement. C'est pour cette raison que les index non cluster constituent une solution idéale pour les requêtes à correspondance exacte ; l'index contient en effet des entrées décrivant l'emplacement exact qu'occupent dans la table les valeurs de données recherchées dans les requêtes.
Par exemple, pour interroger la HumanResources.Employee table pour tous les employés qui dépendent d'un responsable spécifique, l’optimiseur de requête peut utiliser l’index non cluster IX_Employee_ManagerID ; qui a ManagerID pour première colonne clé. Étant donné que les ManagerID valeurs sont classées dans l’index non cluster, l’optimiseur de requête peut rapidement rechercher toutes les entrées de l’index qui correspondent à la valeur spécifiée ManagerID . Chaque entrée d’index pointe vers la page et la ligne exactes de la table de base où les données correspondantes de toutes les autres colonnes peuvent être récupérées. Une fois que l’optimiseur de requête trouve toutes les entrées dans l’index, elle peut accéder directement à la page et à la ligne exactes pour récupérer les données au lieu d’analyser l’intégralité de la table de base.
Architecture des index non-cluster
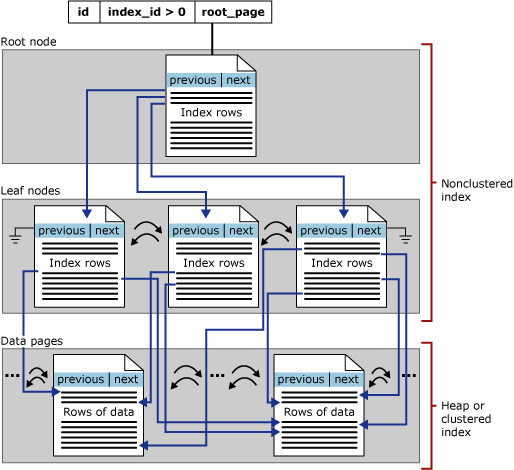
Les index non structurés en clusters de stockage par lignes basés sur disque ont la même structure d’arborescence B+ que les index structurés en clusters, excepté les différences suivantes :
Un index non cluster ne contient pas nécessairement toutes les colonnes et lignes de la table.
Le niveau feuille d’un index non cluster n’est pas constitué de pages de données, mais de pages d’index. Les pages d’index au niveau feuille d’un index non cluster contiennent des colonnes clés. Si vous le souhaitez, ils peuvent également contenir un sous-ensemble d’autres colonnes de la table en tant que colonnes incluses, pour éviter de les récupérer à partir de la table de base.
Les localisateurs de lignes dans les lignes d’index non-cluster sont soit un pointeur vers une ligne, soit une clé d’index cluster pour une ligne, décrite comme suit :
Si la table a un index cluster, ou si l'index est sur une vue indexée, le localisateur de ligne est la clé d'index cluster pour la ligne.
Si la table est un segment de mémoire (dépourvue d'index cluster), le localisateur de ligne est un pointeur vers la ligne. Le pointeur est construit à partir de l'ID du fichier, du numéro de la page et du numéro de ligne dans la page. Le pointeur complet est appelé une ID de ligne (RID).
Les localisateurs de ligne garantissent également l’unicité des lignes d’index non-cluster. Le tableau suivant décrit comment le moteur de base de données ajoute des localisateurs de ligne aux index non-cluster :
| Type de table de base | Type d’index non-cluster | Localisateur de lignes |
|---|---|---|
| Heap | ||
| Nonunique | RID ajouté aux colonnes clés | |
| Unique | RID ajouté aux colonnes incluses | |
| Index cluster unique | ||
| Nonunique | Clés d’index cluster ajoutées aux colonnes clés | |
| Unique | Clés d’index cluster ajoutées aux colonnes incluses | |
| Index cluster non unique | ||
| Nonunique | Clés d’index cluster et indicateur d’unicité (le cas échéant) ajoutés aux colonnes clés | |
| Unique | Clés d’index cluster et indicateur d’unicité (le cas échéant) ajoutés aux colonnes incluses |
Le moteur de base de données ne stocke jamais une colonne donnée plusieurs fois dans un index non cluster. L’ordre de clé d’index spécifié par l’utilisateur lorsqu’il crée un index non cluster est toujours respecté : toutes les colonnes de localisateur de lignes qui doivent être ajoutées à la clé d’un index non cluster sont ajoutées à la fin de la clé, en suivant les colonnes spécifiées dans la définition d’index. Les localisateurs de lignes clés d’index en cluster dans un index non cluster peuvent être utilisés dans le traitement des requêtes, qu’ils soient explicitement spécifiés dans la définition d’index ou ajoutés implicitement.
Les exemples suivants montrent comment les localisateurs de ligne sont implémentés dans des index non-cluster :
| Index clusterisé | Définition d’index non-cluster | Définition d’index non-cluster avec localisateurs de ligne | Explanation |
|---|---|---|---|
Index cluster unique avec des colonnes clés (A, B, C) |
Index non-cluster non unique avec des colonnes clés (B, A) et des colonnes incluses (E, G) |
Colonnes clés (B, A, C) et colonnes incluses (E, G) |
L’index non-cluster n’étant pas unique, le localisateur de ligne doit être présent dans les clés d’index. Les colonnes B et A du localisateur de ligne étant déjà présentes, seule la colonne C est ajoutée. La colonne C est ajoutée à la fin de la liste des colonnes clés. |
Index cluster unique avec une colonne clé (A) |
Index non-cluster non unique avec des colonnes clés (B, C) et une colonne incluse (A) |
Colonnes clés (B, C, A) |
L’index non-cluster n’étant pas unique, le localisateur de ligne est ajouté à la clé. La colonne A n’étant pas encore spécifiée en tant que colonne clé, elle est ajoutée à la fin de la liste des colonnes clés. La colonne A étant maintenant dans la clé, il est inutile de la stocker en tant que colonne incluse. |
Index cluster unique avec des colonnes clés (A, B) |
Index non-cluster unique avec une colonne clé (C) |
Colonne clé (C) et colonnes incluses (A, B) |
L’index non-cluster étant unique, le localisateur de ligne est ajouté aux colonnes incluses. |
Les index non cluster ont une ligne dans sys.partitions pour chaque partition utilisée par l’index, avec index_id > 1. Par défaut, un index non-cluster contient une seule partition. Quand un index non cluster a plusieurs partitions, chaque partition possède une arborescence B+ qui contient les lignes d’index correspondantes. Par exemple, si un index non cluster a quatre partitions, il existe quatre structures d’arborescence B+, une dans chaque partition.
En fonction des types de données de l'index non-cluster, chaque structure d'index non-cluster aura une ou plusieurs unités d'allocation dans lesquelles stocker et gérer les données d'une partition spécifique. Au minimum, chaque index non-clustered a une unité d’allocation IN_ROW_DATA par partition qui stocke les pages d'index de l'arborescence B+. L’index non cluster a également une unité d’allocation LOB_DATA par partition s’il contient des colonnes d’objet volumineux (LOB) telles que nvarchar(max). En outre, elle a une unité d’allocation ROW_OVERFLOW_DATA par partition si elle contient des colonnes de longueur variable qui dépassent la limite de taille de ligne de 8 060 octets.
L'illustration suivante montre la structure d'un index non-cluster avec une seule partition.
Utiliser des colonnes incluses dans des index non-clusterisés
En plus des colonnes clés, un index non cluster peut également avoir des colonnes non clés stockées dans le niveau feuille. Ces colonnes non clés sont appelées colonnes incluses et sont spécifiées dans la INCLUDE clause de l’instruction CREATE INDEX .
Un index avec des colonnes non clés incluses peut améliorer considérablement les performances des requêtes lorsqu’il couvre la requête, autrement dit, lorsque toutes les colonnes utilisées dans la requête se trouvent dans l’index en tant que colonnes clés ou non clés. Les gains de performances sont obtenus, car le moteur de base de données peut localiser toutes les valeurs de colonne dans l’index ; la table de base n’est pas accessible, ce qui entraîne moins d’opérations d’E/S de disque.
Si une colonne doit être récupérée par une requête, mais n’est pas utilisée dans les prédicats de requête, les agrégations et les tris, ajoutez-la en tant que colonne incluse et non en tant que colonne clé. Cela présente les avantages suivants :
Les colonnes incluses peuvent utiliser des types de données non autorisés comme colonnes clés d’index.
Les colonnes incluses ne sont pas prises en compte par le moteur de base de données lors du calcul du nombre de colonnes clés d’index ou de taille de clé d’index. Avec les colonnes incluses, vous n’êtes pas limité par la taille de clé maximale de 900 octets. Vous pouvez créer des index plus larges qui couvrent davantage de requêtes.
Lorsque vous déplacez une colonne de la clé d’index vers des colonnes incluses, la génération d’index prend moins de temps, car l’opération de tri d’index devient plus rapide.
Si la table a un index clusterisé, les colonnes définies dans la clé d’index clusterisé sont automatiquement ajoutées à chaque index non clusterisé sur la table. Il n’est pas nécessaire de les spécifier dans la clé d’index non cluster ou en tant que colonnes incluses.
Instructions pour les index avec des colonnes incluses
Tenez compte des instructions suivantes lorsque vous concevez des index non cluster avec des colonnes incluses :
Les colonnes incluses ne peuvent être définies que dans des index non cluster sur des tables ou des vues indexées.
Tous les types de données sont autorisés, à l'exception de text, ntextet image.
Les colonnes calculées déterministes et précises ou imprécises peuvent être des colonnes incluses. Pour plus d’informations, consultez Index sur les colonnes calculées.
Comme pour les colonnes clés, les colonnes calculées dérivées des types de données image, ntext et texte peuvent être incluses dans les colonnes tant que le type de données de colonne calculée est autorisé dans une colonne incluse.
Les noms des colonnes ne peuvent pas être spécifiés à la fois dans la liste
INCLUDEet dans la liste des colonnes clés.Les noms des colonnes ne peuvent pas être répétés dans la liste
INCLUDE.Au moins une colonne clé doit être définie dans un index. Le nombre maximal de colonnes incluses est de 1 023. Il équivaut au nombre maximal de colonnes de table moins 1.
Quelle que soit la présence de colonnes incluses, les colonnes clés d’index doivent respecter les restrictions de taille d’index existantes de 16 colonnes clés maximum et une taille totale de clé d’index de 900 octets.
Recommandations de conception pour les index avec des colonnes incluses
Envisagez de redéfinir les index non cluster avec une grande taille de clé d’index afin que seules les colonnes utilisées dans les prédicats de requête, les agrégations et les tris soient des colonnes clés. Toutes les autres colonnes qui couvrent la requête doivent être des colonnes non-clés incluses. De cette manière, vous disposez de toutes les colonnes nécessaires pour couvrir la requête, mais la clé d'index elle-même est petite et efficace.
Par exemple, supposons que vous voulez concevoir un index qui couvre la requête ci-dessous.
SELECT AddressLine1,
AddressLine2,
City,
StateProvinceID,
PostalCode
FROM Person.Address
WHERE PostalCode BETWEEN N'98000' AND N'99999';
Pour couvrir la requête, chaque colonne doit être définie dans l'index. Même si vous pouviez définir toutes les colonnes en tant que colonnes clés, la taille de clé serait 334 octets. Comme la seule colonne utilisée comme critère de recherche est la colonne PostalCode, dont la longueur vaut 30 octets, une meilleure conception d’index définirait PostalCode comme colonne clé et inclurait toutes les autres colonnes comme colonnes non-clés.
L'instruction suivante crée un index contenant des colonnes incluses pour couvrir la requête.
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
Pour vérifier que l’index couvre la requête, créez l’index, puis affichez le plan d’exécution estimé. Si le plan d’exécution affiche un opérateur Index Seek pour l’index IX_Address_PostalCode , la requête est couverte par l’index.
Considérations relatives aux performances pour les index avec des colonnes incluses
Évitez de créer des index avec un très grand nombre de colonnes incluses. Même si l’index peut couvrir davantage de requêtes, son avantage de performances est réduit car :
La page contient moins de lignes d'index. Cela augmente les E/S de disque et réduit l’efficacité du cache.
Le stockage de l'index nécessite plus d'espace disque. En particulier, l’ajout de varchar(max), nvarchar(max), varbinary(max) ou des types de données xml dans les colonnes incluses peut augmenter considérablement les besoins en espace disque. En effet, les valeurs des colonnes sont copiées dans le niveau feuille de l'index. Par conséquent, elles résident à la fois dans l'index et dans la table de base.
Les performances de modification des données diminuent, car de nombreuses colonnes doivent être modifiées à la fois dans la table basée et dans l’index non cluster.
Vous devez déterminer si les gains de performances des requêtes l’emportent sur la diminution des performances de modification des données et l’augmentation des besoins en espace disque.
Recommandations pour la conception d'index uniques
Un index unique garantit que la clé d’index ne contient aucune valeur en double. La création d’un index unique n’est possible que lorsque l’unicité est une caractéristique des données elles-mêmes. Par exemple, si vous souhaitez que les valeurs de la colonne NationalIDNumber de la table HumanResources.Employee soient uniques, lorsque la clé primaire est EmployeeID, créez une contrainte UNIQUE sur la colonne NationalIDNumber. La contrainte rejette toute tentative d’introduction de lignes avec des numéros d’ID nationaux en double.
Lorsque vous utilisez un index unique multicolonne, celui-ci garantit que chaque combinaison de valeurs dans la clé d'index est unique. Par exemple, si un index unique est créé sur une combinaison des colonnes LastName, FirstName et MiddleName, aucune des deux lignes de la table ne peut avoir les mêmes valeurs pour ces colonnes.
Tant les index cluster que les index non-cluster peuvent être uniques. Vous pouvez créer un index cluster unique et plusieurs index non cluster uniques sur la même table.
Les avantages des index uniques sont les suivants :
- Les règles d’entreprise qui nécessitent l’unicité des données sont appliquées.
- L'optimiseur de requête dispose d'informations utiles supplémentaires.
Lorsque vous créez une contrainte PRIMARY KEY ou UNIQUE, vous créez automatiquement un index unique sur les colonnes spécifiées. Il n’y a pas de différences significatives entre la création d’une contrainte UNIQUE et la création d’un index unique indépendant d’une contrainte. La validation des données s'effectue de la même manière et l'optimiseur de requêtes ne fait pas de différence entre un index unique créé par une contrainte ou créé manuellement. Toutefois, vous devez créer une UNIQUE ou PRIMARY KEY contrainte sur la colonne lorsque l’application des règles d’entreprise est l’objectif. Cette opération met en évidence la finalité de l’index.
Considérations relatives à l’index unique
Un index unique, une contrainte
UNIQUEou une contraintePRIMARY KEYne peuvent pas être créés si les données comportent des valeurs de clé dupliquées.Si les données sont uniques et que l'unicité doit être assurée, la création d'un index unique au lieu d'un index non unique sur la même combinaison de colonnes fournit des informations supplémentaires à l'optimiseur de requête, qui peut générer des plans d'exécution plus efficaces. La création d’une
UNIQUEcontrainte ou d’un index unique est recommandée dans ce cas.Un index non cluster unique peut contenir des colonnes non-clés incluses. Pour plus d’informations, consultez Utiliser les colonnes incluses dans les index non cluster.
Contrairement à une
PRIMARY KEYcontrainte, uneUNIQUEcontrainte ou un index unique peut être créé avec une colonne nullable dans la clé d’index. Dans le cadre de l’application de l’unicité, deux VALEURS NULL sont considérées comme égales. Par exemple, cela signifie que dans un index unique à colonne unique, la colonne peut être NULL pour une seule ligne de la table uniquement.
Recommandations pour la conception d'index filtrés
Un index filtré est un index non cluster optimisé, particulièrement adapté aux requêtes qui nécessitent un petit sous-ensemble de données dans la table. Il utilise un prédicat de filtre dans la définition d’index pour indexer une partie des lignes de la table. Un index filtré bien conçu peut améliorer les performances des requêtes, réduire les coûts de mise à jour d’index et réduire les coûts de stockage d’index par rapport à un index de table complète.
Les index filtrés peuvent présenter les avantages suivants par rapport aux index de table entière :
Meilleures performances des requêtes et qualité de plan améliorée
Un index filtré bien conçu améliore les performances des requêtes et la qualité du plan d’exécution, car il est plus petit qu’un index non cluster complet. Un index filtré a filtré des statistiques, qui sont plus précises que les statistiques de table complète, car elles couvrent uniquement les lignes de l’index filtré.
Réduction des coûts de mise à jour d’index
Un index est mis à jour uniquement lorsque les instructions DML (Data Manipulation Language) affectent les données de l’index. Un index filtré réduit les coûts de mise à jour d’index par rapport à un index non cluster complet, car il est plus petit et n’est mis à jour que lorsque les données de l’index sont affectées. Il est possible d’avoir un grand nombre d’index filtrés, notamment s’ils contiennent des données qui sont rarement affectées. De même, si un index filtré contient uniquement les données fréquemment affectées, la plus petite taille de l’index réduit le coût de la mise à jour des statistiques.
Coûts réduits de stockage des index
La création d'un index filtré peut réduire le stockage sur disque des index non-cluster lorsqu'un index de table entière n'est pas nécessaire. Vous pouvez peut-être remplacer un index non cluster complet par plusieurs index filtrés sans augmenter considérablement les exigences de stockage.
Les index filtrés sont utiles lorsque les colonnes contiennent des sous-ensembles de données bien définis. Voici quelques exemples :
Colonnes qui contiennent de nombreuses NULL.
Colonnes hétérogènes qui contiennent des catégories de données.
Colonnes qui contiennent des plages de valeurs telles que les quantités, l’heure et les dates.
Les coûts de mise à jour réduits pour les index filtrés sont les plus notables lorsque le nombre de lignes de l’index est petit par rapport à un index de table complète. Si l'index filtré inclut la plupart des lignes de la table, son coût de maintenance risque d'être plus élevé que celui d'un index de table entière. Dans ce cas, vous devez utiliser un index de table entière à la place d'un index filtré.
Les index filtrés sont définis sur une seule table et ne prennent en charge que les opérateurs de comparaison simples. Si vous avez besoin d’une expression de filtre qui a une logique complexe ou fait référence à plusieurs tables, vous devez créer une colonne calculée indexée ou une vue indexée.
Considérations relatives à la conception d’index filtrées
Pour concevoir des index filtrés efficaces, il est important de comprendre les requêtes utilisées par votre application et leurs relations avec les sous-ensembles de données. Voici quelques exemples de données qui ont des sous-ensembles bien définis sont des colonnes avec de nombreuses valeurs NULL, des colonnes avec des catégories hétérogènes de valeurs et de colonnes avec des plages de valeurs distinctes.
Les considérations de conception suivantes donnent plusieurs scénarios pour concevoir un index filtré pouvant offrir des avantages par rapport aux index de table complète.
Index filtrés pour des sous-ensembles de données
Lorsqu'une colonne ne contient que quelques valeurs pertinentes pour les requêtes, vous pouvez créer un index filtré sur ce sous-ensemble de valeurs. Par exemple, lorsque la colonne est principalement NULL et que la requête nécessite uniquement des valeurs non NULL, vous pouvez créer un index filtré contenant les lignes non NULL.
Par exemple, l’exemple de base de données AdventureWorks contient une table Production.BillOfMaterials de 2 679 lignes. La EndDate colonne comporte uniquement 199 lignes qui contiennent une valeur non NULL et les 2480 autres lignes contiennent NULL. L’index filtré suivant couvre les requêtes qui retournent les colonnes définies dans l’index et qui nécessitent uniquement des lignes avec une valeur non NULL pour EndDate.
CREATE NONCLUSTERED INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials (ComponentID, StartDate)
WHERE EndDate IS NOT NULL;
L'index filtré FIBillOfMaterialsWithEndDate est valide pour la requête suivante. Vous pouvez afficher le plan d’exécution estimé pour déterminer si l’optimiseur de requête a utilisé l’index filtré.
SELECT ProductAssemblyID,
ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL
AND ComponentID = 5
AND StartDate > '20080101';
Pour plus d’informations sur la création d’index filtrés et la définition de l’expression de prédicat d’index filtré, consultez Créer des index filtrés.
Index filtrés pour des données hétérogènes
Lorsqu'une table contient des lignes des données hétérogènes, vous pouvez créer un index filtré pour une ou plusieurs catégories de données.
Par exemple, chacun des produits répertoriés dans la table Production.Product est affecté à un ProductSubcategoryID, qui est à son tour associé à une catégorie de produits (Bikes, Components, Clothing ou Accessories). Ces catégories sont hétérogènes, car leurs valeurs de colonne dans la table Production.Product ne sont pas étroitement corrélées. Par exemple, les colonnes Color, ReorderPoint, ListPrice, Weight, Classet Style ont des caractéristiques uniques pour chaque catégorie de produit. Supposons que des requêtes portent fréquemment sur les accessoires, dont les sous-catégories se situent entre 27 et 36 inclus. Améliorez les performances des requêtes portant sur Accessories en créant un index filtré sur les sous-catégories de la catégorie Accessories, tel que l'illustre l'exemple suivant.
CREATE NONCLUSTERED INDEX FIProductAccessories
ON Production.Product (ProductSubcategoryID, ListPrice)
INCLUDE (Name)
WHERE ProductSubcategoryID >= 27 AND ProductSubcategoryID <= 36;
L’index FIProductAccessories filtré couvre la requête suivante, car les résultats de la requête sont contenus dans l’index et le plan de requête ne nécessite pas d’accéder à la table de base. Par exemple, l'expression de prédicat de requête ProductSubcategoryID = 33 est un sous-ensemble du prédicat d'index filtré ProductSubcategoryID >= 27 et ProductSubcategoryID <= 36, les colonnes ProductSubcategoryID et ListPrice dans le prédicat de requête sont toutes deux des colonnes clés dans l'index et le nom est stocké au niveau feuille de l'index en tant que colonne incluse.
SELECT Name,
ProductSubcategoryID,
ListPrice
FROM Production.Product
WHERE ProductSubcategoryID = 33
AND ListPrice > 25.00;
Clés et colonnes incluses dans les index filtrés
Il est recommandé d’ajouter un petit nombre de colonnes dans une définition d’index filtrée, uniquement si nécessaire pour l’optimiseur de requête afin de choisir l’index filtré pour le plan d’exécution de requête. L'optimiseur de requête peut choisir un index filtré pour la requête, qu'il couvre ou non la requête. Toutefois, l'optimiseur de requête choisira plus probablement un index filtré s'il couvre la requête.
Dans certains cas, un index filtré couvre la requête sans inclure les colonnes de l'expression d'index filtré en tant que colonnes clés ou incluses dans la définition de l'index filtré. Les règles suivantes expliquent dans quels cas une colonne de l'expression d'index filtré doit être une colonne clé ou incluse dans la définition de l'index filtré. Les exemples font référence à l'index filtré FIBillOfMaterialsWithEndDate qui a été créé précédemment.
Il n'est pas nécessaire qu'une colonne de l'expression d'index filtré soit une colonne clé ou incluse dans la définition de l'index filtré si l'expression d'index filtré est équivalente au prédicat de requête et si la requête ne retourne pas la colonne dans l'expression d'index filtré avec les résultats de la requête. Par exemple, l'index filtré FIBillOfMaterialsWithEndDate couvre la requête suivante parce que le prédicat de la requête est équivalent à l'expression de filtre et que EndDate n'est pas retourné avec les résultats de la requête. L’index FIBillOfMaterialsWithEndDate n’a pas besoin EndDate d’une clé ou d’une colonne incluse dans la définition d’index filtré.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Une colonne de l'expression d'index filtré doit être une colonne clé ou incluse dans la définition de l'index filtré si le prédicat de la requête utilise cette colonne dans une comparaison qui n'est pas équivalente à l'expression d'index filtré. Par exemple, l'index filtré FIBillOfMaterialsWithEndDate est valide pour la requête suivante car il sélectionne un sous-ensemble de lignes dans l'index filtré. Toutefois, il ne couvre pas la requête suivante, car EndDate est utilisé dans la comparaison EndDate > '20040101', qui n'est pas équivalente à l'expression d'index filtré. Le processeur de requêtes ne peut pas exécuter cette requête sans examiner les valeurs de EndDate. Par conséquent, EndDate doit être une colonne clé ou incluse dans la définition de l'index filtré.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate > '20040101';
Une colonne de l'expression d'index filtré doit être une colonne clé ou incluse dans la définition de l'index filtré si la colonne se trouve dans le jeu de résultats de la requête. Par exemple, l'index filtré FIBillOfMaterialsWithEndDate ne couvre pas la requête suivante, car il retourne la colonne EndDate dans les résultats de la requête. Par conséquent, EndDate doit être une colonne clé ou incluse dans la définition de l'index filtré.
SELECT ComponentID,
StartDate,
EndDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Il n'est pas nécessaire que la clé de l'index cluster de la table soit une colonne clé ou incluse dans la définition de l'index filtré. La clé de l'index cluster est automatiquement incluse dans tous les index non cluster, y compris les index filtrés.
Opérateurs de conversion de données dans le prédicat du filtre
Si l'opérateur de comparaison spécifié dans l'expression d'index filtré de l'index filtré provoque une conversion de données implicite ou explicite, une erreur survient si cette conversion se produit du côté gauche d'un opérateur de comparaison. L’une des solutions consiste à écrire l’expression de l’index filtré avec l’opérateur de conversion de données (CAST ou CONVERT) situé à droite de l’opérateur de comparaison.
L’exemple suivant crée une table avec des colonnes de différents types de données.
CREATE TABLE dbo.TestTable
(
a INT,
b VARBINARY(4)
);
Dans la définition d’index filtrée suivante, la colonne b est implicitement convertie en type de données entier pour la comparer à la constante 1. Le message d’erreur 10611 est alors généré car la conversion se produit à gauche de l’opérateur dans le prédicat filtré.
CREATE NONCLUSTERED INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = 1;
La solution consiste à convertir la constante qui se trouve à droite de manière à ce que son type soit identique à celui de la colonne b, comme dans l’exemple suivant :
CREATE INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = CONVERT (VARBINARY(4), 1);
Le fait de déplacer la conversion de données de la gauche vers la droite d'un opérateur de comparaison peut modifier la signification de la conversion. Dans l’exemple précédent, lorsque l’opérateur CONVERT a été ajouté à droite, la comparaison est passée d’une comparaison int à une comparaison varbinary .
Architecture des index columnstore
Un index columnstore est une technologie de stockage, de récupération et de gestion des données à l’aide d’un format de données columnar, appelé columnstore. Pour plus d’informations, consultez les index Columnstore : vue d’ensemble.
Pour plus d’informations sur la version et pour découvrir les nouveautés, visitez les Nouveautés relatives aux index columnstore.
Connaître ces principes de base facilite la compréhension d’autres articles columnstore qui expliquent comment utiliser cette technologie efficacement.
Le stockage de données utilise columnstore et rowstore
Quand nous parlons des index columnstore, nous utilisons les termes rowstore et columnstore pour indiquer clairement le format du stockage de données. Les index columnstore utilisent les deux types de stockage.
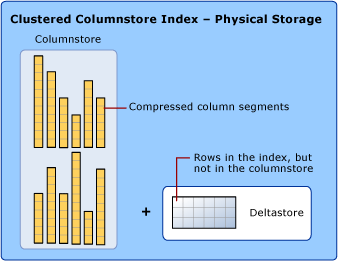
Un columnstore représente des données qui sont organisées logiquement sous la forme d’une table avec des lignes et des colonnes, et stockées physiquement dans un format de données selon les colonnes.
Un index columnstore stocke physiquement la plupart des données au format columnstore. Au format columnstore, les données sont compressées et décompressées sous la forme de colonnes. Il n’est pas nécessaire de décompresser les autres valeurs de chaque ligne qui ne sont pas demandées par la requête. Cela permet d’analyser rapidement une colonne entière d’une table volumineuse.
Un rowstore représente des données qui sont organisées logiquement sous la forme d’une table avec des lignes et des colonnes, puis stockées physiquement dans un format de données selon les lignes. Il s’agit du moyen traditionnel de stocker des données de table relationnelles telles qu’un index B+ arborescent groupé ou un tas.
Un index columnstore stocke également physiquement certaines lignes dans un format rowstore appelé deltastore. Le deltastore, également appelé « rowgroups delta », est un espace de stockage pour les lignes qui sont en trop petit nombre pour bénéficier de la compression dans le columnstore. Chaque rowgroup delta est implémenté en tant qu’index d’arborescence B+ clusterisée, qui est un rowstore.
Les opérations sont effectuées sur des rowgroups et des segments de colonne
L’index columnstore regroupe des lignes en unités gérables. Chacune de ces unités est appelée rowgroup. Pour des performances optimales, le nombre de lignes d'un rowgroup est suffisamment grand pour améliorer le ratio de compression et suffisamment petit pour bénéficier des opérations en mémoire.
Par exemple, l’index columnstore effectue les opérations suivantes sur des rowgroups :
Compresse les rowgroups dans le columnstore. La compression est effectuée sur chaque segment de colonne d’un rowgroup.
Fusionne les rowgroups pendant une
ALTER INDEX ... REORGANIZEopération, y compris la suppression de données supprimées.Recrée tous les groupes de lignes pendant une
ALTER INDEX ... REBUILDopération.Génère des rapports sur l’intégrité et la fragmentation des rowgroups dans des vues de gestion dynamique (DMV).
Le deltastore se compose d’un ou plusieurs rowgroups appelés rowgroups delta. Chaque rowgroup delta est un index d’arborescence B+ en grappes qui stocke de petites charges en bloc et des insertions jusqu'à ce que le rowgroup contienne 1 048 576 lignes, après quoi un processus appelé tuple-mover compresse automatiquement un rowgroup fermé dans le columnstore.
Pour plus d’informations sur les états de rowgroup, consultez sys.dm_db_column_store_row_group_physical_stats.
Tip
Avoir un trop grand nombre de rowgroups de petite taille réduit la qualité de l’index columnstore. Une opération de réorganisation fusionne des rowgroups plus petits, suite à une stratégie de seuil interne qui détermine comment supprimer les lignes supprimées et combiner les rowgroups compressés. Après une fusion, la qualité de l’index est améliorée.
Dans SQL Server 2019 (15.x) et versions ultérieures, le tuple-mover est aidé par une tâche de fusion en arrière-plan qui compresse automatiquement des rowgroups delta ouverts plus petits qui existent depuis un certain temps, comme déterminé par un seuil interne, ou fusionne des rowgroups compressés à partir desquels un grand nombre de lignes a été supprimé.
Chaque colonne a certaines de ses valeurs dans chaque rowgroup. Ces valeurs sont appelées segments de colonne. Chaque rowgroup contient un segment de colonne pour chaque colonne dans la table. Chaque colonne a un seul segment de colonne dans chaque rowgroup.
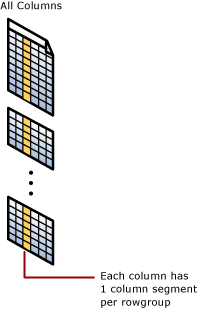
Quand l’index columnstore compresse un rowgroup, il compresse chaque segment de colonne séparément. Pour décompresser la totalité d’une colonne, l’index columnstore doit simplement décompresser un segment de colonne dans chaque rowgroup.
Les petits chargements et les petites insertions sont placés dans le deltastore
Un index columnstore améliore la compression columnstore et les performances en compressant au moins 102 400 lignes à la fois dans l’index columnstore. Pour compresser des lignes en masse, l’index columnstore accumule les petits chargements et les petites insertions dans le deltastore. Les opérations deltastore sont gérées en arrière-plan. Pour retourner les résultats de la requête, l'index columnstore clusterisé combine les résultats de la requête des deux sources : le columnstore et le deltastore.
Les lignes sont placées dans le deltastore quand elles sont :
Insérées avec l’instruction
INSERT INTO ... VALUES.À la fin d’un chargement en masse et que leur nombre est inférieur à 102 400.
Updated. Chaque mise à jour correspond à une suppression et une insertion.
Le deltastore stocke également une liste des ID des lignes supprimées qui ont été marquées comme supprimées mais qui n’ont pas encore été supprimées physiquement de l’index columnstore.
Quand les rowgroups delta sont pleins, ils sont compressés dans le columnstore.
Les index columnstore cluster collectent jusqu’à 1 048 576 lignes dans chaque rowgroup delta avant de compresser le rowgroup dans le columnstore. Cela améliore la compression de l’index columnstore. Lorsqu’un rowgroup delta atteint le nombre maximal de lignes, il passe de l’état OPEN à l’état CLOSED. Un processus en arrière-plan nommé moteur de tuple vérifie les groupes de lignes fermés. Lorsqu'il trouve un rowgroup fermé, il le compresse et le stocke dans le columnstore.
Quand un rowgroup delta a été compressé, le rowgroup delta existant passe à l’état TOMBSTONE pour être supprimé ultérieurement par le moteur de tuple lorsqu’il n’y a aucune référence à celui-ci. Le nouveau rowgroup compressé est marqué comme COMPRESSED.
Pour plus d’informations sur les états de rowgroup, consultez sys.dm_db_column_store_row_group_physical_stats.
Vous pouvez placer de force des rowgroups delta dans le columnstore à l’aide de l’instruction ALTER INDEX pour reconstruire ou réorganiser l’index. S’il existe une sollicitation de la mémoire lors de la compression, l’index columnstore peut réduire le nombre de lignes stockées dans le rowgroup compressé.
Chaque partition de table a ses propres rowgroups et rowgroups delta
Le concept de partitionnement est le même dans un index clusterisé, un tas de données et un index de stockage en colonnes. Le partitionnement d’une table divise la table en groupes de lignes plus petits en fonction d’une plage de valeurs de colonne. Il est souvent utilisé pour la gestion des données. Par exemple, vous pouvez créer une partition pour chaque année de données, puis utiliser le basculement de partition pour archiver les anciennes données dans un stockage moins coûteux.
Les rowgroups sont toujours définis dans une partition de table. Quand un index columnstore est partitionné, chaque partition possède ses propres rowgroups et rowgroups delta compressés. Une table nonpartitionnée contient une partition.
Tip
Envisagez d’utiliser le partitionnement de table si vous devez supprimer des données du columnstore. Le remplacement et la réduction des partitions inutiles est une stratégie efficace pour supprimer des données sans introduire de fragmentation dans le columnstore.
Chaque partition peut posséder plusieurs rowgroups delta
Chaque partition peut posséder plusieurs rowgroups delta. Lorsque l’index columnstore doit ajouter des données à un rowgroup delta et que le rowgroup delta est verrouillé par une autre transaction, l’index columnstore tente d’obtenir un verrou sur un autre rowgroup delta. Si aucun rowgroup delta n’est disponible, l’index columnstore en crée un. Par exemple, une table comportant 10 partitions peut facilement avoir au moins 20 rowgroups delta.
Vous pouvez combiner des index columnstore et rowstore sur la même table
Un index non cluster contient une copie de tout ou partie des lignes et colonnes de la table sous-jacente. L’index est défini comme une ou plusieurs colonnes de la table et a une condition facultative qui filtre les lignes.
Vous pouvez créer un index columnstore non-cluster pouvant être mis à jour sur une table rowstore. L’index columnstore stocke une copie des données, afin que vous n’ayez pas besoin de stockage supplémentaire. Toutefois, les données de l’index columnstore se compressent à une taille beaucoup plus petite que la table rowstore nécessite. Pour ce faire, vous pouvez exécuter des analyses sur l’index columnstore et les charges de travail OLTP sur l’index rowstore simultanément. Le columnstore est mis à jour lors de la modification des données de la table rowstore. Les deux index utilisent donc les mêmes données.
Une table rowstore peut avoir un index columnstore non cluster. Pour plus d’informations, consultez les index Columnstore - Conseils de conception.
Vous pouvez avoir un ou plusieurs index de type rowstore noncluster sur une table à colonnes clusterisée. Ce faisant, vous pouvez effectuer des recherches de tables efficaces sur le columnstore sous-jacent. D’autres options sont également disponibles. Par exemple, vous pouvez appliquer l’unicité à l’aide d’une UNIQUE contrainte sur la table rowstore. Lorsqu’une valeur non unique ne parvient pas à être insérée dans la table rowstore, le moteur de base de données n’insère pas non plus la valeur dans le columnstore.
Considérations relatives aux performances des columnstore non-clusterisés
Pour définir des index columnstore non-cluster, vous pouvez utiliser une condition filtrée. Pour réduire l'impact sur les performances de l'ajout d'un index columnstore, utilisez une expression de filtre pour créer un index columnstore non clusterisé uniquement sur le sous-ensemble de données requis pour l'analyse.
Une table optimisée pour la mémoire peut avoir un index de stockage par colonne. Vous pouvez le créer lorsque la table est créée ou l’ajouter ultérieurement avec ALTER TABLE.
Pour plus d’informations, consultez les index Columnstore - Performances des requêtes.
Recommandations en matière de conception d’index de hachage à mémoire optimisée
Lorsque vous utilisez In-Memory OLTP, toutes les tables optimisées en mémoire doivent avoir au moins un index. Pour une table optimisée pour la mémoire, chaque index est également optimisé pour la mémoire. Les index de hachage sont l’un des types d’index possibles dans une table optimisée en mémoire. Pour plus d’informations, consultez Index pour les tables à mémoire optimisée.
Architecture d'index de hachage optimisé pour la mémoire
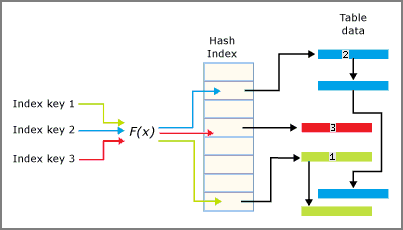
Un index de hachage se compose d’un tableau de pointeurs, chaque élément du tableau constituant un compartiment de hachage.
- Chaque compartiment comprend 8 octets, qui sont utilisés pour stocker l’adresse mémoire d’une liste de liens d’entrées d’index.
- Chaque entrée correspond à une valeur pour une clé d’index, plus l’adresse de la ligne associée dans la table mémoire optimisée sous-jacente.
- Chaque entrée pointe vers l’entrée suivante dans une liste de liens d’entrées, toutes chaînées au compartiment actuel.
Le nombre de compartiments doit être spécifié au moment de la création de l’index :
- Plus le rapport entre les compartiments et les lignes de table ou les valeurs distinctes est faible, plus la liste moyenne de liens de compartiments est longue.
- Les listes de liens courtes sont plus rapides que les listes de liens longues.
- Un index de hachage peut contenir 1 073 741 824 compartiments au maximum.
Tip
Pour déterminer le droit BUCKET_COUNT pour vos données, consultez la page Configuration du nombre de compartiments d'index de hachage.
La fonction de hachage est appliquée aux colonnes de clés d’index. Son résultat détermine le compartiment auquel ces clés sont mappées. Chaque compartiment a un pointeur vers les lignes dont les valeurs de clés hachées sont mappées à ce compartiment.
La fonction de hachage utilisée pour les index de hachage présente les caractéristiques suivantes :
- Le moteur de base de données possède une fonction de hachage utilisée pour tous les index de hachage.
- La fonction de hachage est déterministe. La même valeur de clé d’entrée est toujours mappée au même compartiment dans l’index de hachage.
- Plusieurs clés d’index peuvent être mappées au même compartiment de hachage.
- La fonction de hachage est équilibrée, ce qui signifie que la distribution des valeurs de clé d’index sur les compartiments de hachage est généralement une distribution de type Poisson ou courbe en cloche, et pas une distribution linéaire plate.
- La distribution Poisson n'est pas une distribution uniforme. Les valeurs de clé d'index ne sont pas distribuées uniformément dans les compartiments de hachage.
- Si deux clés d’index sont mappées au même compartiment de hachage, il y a une collision de hachage. Un grand nombre de collisions de hachage peut avoir un impact sur la performance des opérations de lecture. Un objectif réaliste est que 30 % des ensembles contiennent deux valeurs clés différentes.
L’interaction entre l’index de hachage et les compartiments est résumée dans l’image ci-dessous.
Configurer le nombre de compartiments d'index de hachage
Le nombre de compartiments d’index de hachage est spécifié au moment de la création de l’index et peut être modifié à l’aide de la syntaxe ALTER TABLE...ALTER INDEX REBUILD.
Dans la plupart des cas, le nombre de compartiments devrait être compris entre 1 et 2 fois le nombre de valeurs distinctes de la clé d'index.
Il se peut que vous ne puissiez pas toujours prédire le nombre de valeurs qu’une clé d’index particulière possède. Les performances sont en général encore bonnes si la valeur BUCKET_COUNT est inférieure ou égale à 10 fois le nombre réel de valeurs de clés et il est généralement préférable de surestimer que de sous-estimer.
Un trop petit nombre de compartiments peut présenter les inconvénients suivants :
- Davantage de collisions de hachage de valeurs de clés distinctes.
- Chaque valeur distincte est forcée de partager le même compartiment avec une autre valeur distincte.
- La longueur de chaîne moyenne par compartiment augmente.
- Plus la chaîne de compartiment est longue, plus les recherches d’égalité sont lentes dans l’index.
Un trop grand nombre de compartiments peut présenter les inconvénients suivants :
- Un nombre de compartiments trop élevé peut entraîner plus de compartiments vides.
- Des compartiments vides affectent les performances des analyses d’index complètes. Si des analyses sont effectuées régulièrement, envisagez de choisir un nombre de compartiments proche du nombre de valeurs de clés distinctes.
- Des compartiments vides utilisent de la mémoire, même si chaque compartiment utilise seulement 8 octets.
Note
L’ajout de nouveaux compartiments ne fait rien pour réduire le chaînage groupé des entrées qui partagent une valeur en double. Le taux de duplication de valeurs est utilisé pour déterminer si un index de hachage ou un index non cluster est le type d’index approprié, et non pour calculer le nombre de compartiments.
Considérations relatives aux performances pour les index de hachage
Les performances d’un index de hachage sont :
- excellentes quand le prédicat dans la clause
WHEREspécifie une valeur exacte pour chaque colonne dans la clé d’index de hachage ; Un index de hachage rétablit une analyse en fonction d’un prédicat d’inégalité. - médiocres quand le prédicat dans la clause
WHERErecherche une plage de valeurs dans la clé d’index ; - médiocres quand le prédicat dans la clause
WHEREstipule une valeur donnée pour la première colonne d'une clé d'index de hachage de deux colonnes, mais ne spécifie pas de valeur pour les autres colonnes de la clé.
Tip
Le prédicat doit inclure toutes les colonnes dans la clé d’index de hachage. L'index de hachage nécessite toute la clé pour effectuer une recherche dans l'index.
Si un index de hachage est utilisé et que le nombre de clés d’index uniques est plus de 100 fois plus petit que le nombre de lignes, envisagez d’augmenter le nombre de compartiments pour éviter les longues chaînes de lignes ou d’utiliser un index non-clusterisé à la place.
Créer un index de hachage
Lors de la création d’un index de hachage, tenez compte des éléments suivants :
- Un index de hachage peut exister uniquement sur une table optimisée en mémoire. Il ne peut pas exister sur une table sur disque.
- Un index de hachage n’est pas unique par défaut, mais peut être déclaré comme unique.
L’exemple suivant crée un index de hachage unique :
ALTER TABLE MyTable_memop ADD INDEX ix_hash_Column2
UNIQUE HASH (Column2) WITH (BUCKET_COUNT = 64);
Versions de lignes et collecte de déchets dans les tables optimisées pour la mémoire
Dans une table mémoire optimisée, lorsqu’une ligne est affectée par une UPDATE instruction, la table crée une version mise à jour de la ligne. Lors de la transaction de mise à jour, d’autres sessions peuvent être en mesure de lire l’ancienne version de la ligne et d’éviter ainsi le ralentissement des performances associé à un verrou de ligne.
L’index de hachage peut également avoir différentes versions de ses entrées pour prendre en charge la mise à jour.
Par la suite, quand les anciennes versions ne sont plus nécessaires, un thread garbage collection (GC) traverse les compartiments et leurs listes de liens pour nettoyer les anciennes entrées. Le thread GC fonctionne mieux si les longueurs de chaîne des listes de liens sont courtes. Pour plus d’informations, consultez Garbage collection de l’OLTP en mémoire.
Recommandations pour la conception d'index non-cluster à mémoire optimisée
Outre les index de hachage, les index non cluster sont les autres types d’index possibles dans une table optimisée en mémoire. Pour plus d’informations, consultez Index pour les tables à mémoire optimisée.
Architecture d’index non clusterisé optimisé pour la mémoire
Les index non cluster sur les tables mémoire optimisées sont implémentés à l’aide d’une structure de données appelée arborescence Bw, initialement prévue et décrite par Microsoft Research en 2011. Un arbre Bw (Bw-tree) est une variante sans verrous d’un arbre B (B-tree). Pour plus d’informations, consultez l’article Arbre Bw (Bw-tree) : arbre B (B-tree) pour les nouvelles plateformes matérielles.
À un niveau élevé, l’arborescence Bw peut être comprise comme une carte de pages organisées par ID de page (PidMap), une fonctionnalité permettant d’allouer et de réutiliser des ID de page (PidAlloc) et d’un ensemble de pages liées dans la carte de pages et entre elles. Ces trois sous-composants principaux constituent la structure interne de base d’un arbre Bw (Bw-tree).
La structure est similaire à un arbre B (B-tree) standard, car chaque page a un ensemble de valeurs de clés ordonnées, l’index a plusieurs niveaux qui pointent vers un niveau inférieur et les niveaux feuille pointent vers une ligne de données. Il y a toutefois quelques différences.
Tout comme avec les index de hachage, plusieurs lignes de données peuvent être liées ensemble pour prendre en charge le contrôle de version. Les pointeurs de page entre les niveaux sont des ID de page logiques qui indiquent une position dans une table de mappage de pages, laquelle contient l’adresse physique de chaque page.
Il n’y a aucune mise à jour sur place des pages d’index. De nouvelles pages delta sont introduites dans ce but.
- Aucun verrouillage n’est nécessaire pour les mises à jour de pages.
- Les pages d'index n'ont pas de taille fixe.
La valeur clé de chaque page de niveau non-feuille est la valeur la plus élevée que l'enfant auquel il pointe contient, et chaque rangée contient également cet ID de page logique. Dans les pages de niveau feuille, avec la valeur de clé, elle contient l’adresse physique de la ligne de données.
Les recherches ponctuelles sont similaires aux arborescences B, sauf que, comme les pages sont liées dans une seule direction, le moteur de base de données suit les pointeurs de page de droite, où chaque page non-feuille a la valeur la plus élevée de son enfant, plutôt que la valeur la plus faible comme dans une arborescence B.
Si une page de niveau feuille doit changer, le moteur de base de données ne modifie pas la page elle-même. Au lieu de cela, le moteur de base de données crée un enregistrement delta qui décrit la modification et l’ajoute à la page précédente. Ensuite, il change également l’adresse de cette page précédente dans la table de mappage des pages par l’adresse de l’enregistrement delta qui devient alors l’adresse physique de cette page.
La gestion de la structure d'un arbre Bw peut nécessiter trois opérations différentes : la consolidation, le fractionnement et la fusion.
Consolidation du delta
Une longue chaîne d’enregistrements delta peut éventuellement dégrader les performances de recherche, car elle peut nécessiter une longue traversée de chaîne lors de la recherche dans un index. Si un nouvel enregistrement delta est ajouté à une chaîne qui contient déjà 16 éléments, les modifications effectuées dans les enregistrements delta sont consolidées dans la page d’index référencée. La page est ensuite regénérée pour inclure les modifications indiquées par le nouvel enregistrement delta ayant déclenché la consolidation. La nouvelle page regénérée a le même ID de page, mais elle a une nouvelle adresse mémoire.
Page divisée
Dans un arbre Bw, une page d'index croît selon les besoins pour stocker une seule ligne jusqu'à un maximum de 8 Ko. Quand la page d’index atteint une taille de 8 Ko, l’insertion d’une nouvelle ligne entraîne le fractionnement de la page d’index. Pour une page interne, cela se produit quand il n’y a plus assez d’espace pour ajouter une autre valeur et le pointeur associé. Pour une page feuille, cela se produit si la ligne est trop longue pour tenir dans la page après l’incorporation de tous les enregistrements delta. Les informations statistiques contenues dans l'en-tête d'une page feuille permettent de savoir combien d'espace est nécessaire pour consolider les enregistrements delta. Ces informations sont ajustées à mesure que chaque nouvel enregistrement delta est ajouté.
Un fractionnement s'effectue en deux étapes atomiques. Dans l'image ci-dessous, l'exemple suppose qu'une page de niveau feuille force un fractionnement après l'insertion d'une clé avec la valeur 5, et qu'il existe une page non-feuille pointant vers la fin de la page feuille active (clé avec la valeur 4).

Étape 1 : allouez deux nouvelles pages P1 et P2, puis fractionnez les lignes de la page P1 précédente sur ces nouvelles pages, y compris la ligne venant d’être insérée. Dans la table de mappage des pages, un nouvel emplacement est utilisé pour stocker l’adresse physique de la page P2. Les pages P1 et P2 ne sont pas encore accessibles aux opérations simultanées. En outre, le pointeur logique entre P1 et P2 est défini. Puis, en une seule étape atomique, mettez à jour la table de mappage des pages pour changer le pointeur de l'ancienne page P1 à la nouvelle page P1.
Étape 2 : la page non-feuille pointe vers P1, mais il n’y a pas de pointeur direct entre cette page non-feuille et la page P2.
P2 est uniquement accessible via P1. Pour créer un pointeur entre une page non-feuille et la page P2, allouez une nouvelle page non-feuille (page d’index interne), copiez toutes les lignes à partir de l’ancienne page non-feuille et ajoutez une nouvelle ligne pour pointer vers P2. Après cela, en une seule étape atomique, mettez à jour la table de mappage des pages pour changer le pointeur de l'ancienne page non-feuille à la nouvelle page non-feuille.
Page de fusion
Lorsqu’une DELETE opération entraîne la fusion d’une page avec moins de 10 % de la taille maximale de la page (8 Ko) ou d’une seule ligne, cette page est fusionnée avec une page contiguë.
Quand une ligne est supprimée d’une page, un enregistrement delta correspondant à la suppression est ajouté. En outre, une vérification est effectuée pour déterminer si la page d’index (page non-en-feuille) est éligible à la fusion. Cette vérification détermine si l’espace restant après la suppression de la ligne est inférieur à 10 % de la taille de page maximale. Si elle satisfait les conditions, la fusion est effectuée en trois étapes atomiques.
Dans l’image ci-dessous, l’exemple suppose qu’une opération DELETE supprime la valeur de clé 10.

Étape 1 : une page delta représentant la valeur de clé 10 (triangle bleu) est créée, et son pointeur dans la page non-feuille Pp1 est défini à la nouvelle page delta. De plus, une page delta spécifique pour la fusion (triangle vert) est créée, et est liée pour pointer vers la page delta. À ce stade, les deux pages (page delta et page delta de la fusion) ne sont pas visibles pour les autres transactions simultanées. En une seule étape atomique, le pointeur vers la page de niveau feuille P1 dans la table de mappage des pages est mis à jour pour pointer vers la page delta de la fusion. Après cette étape, l’entrée de la valeur de clé 10 dans la page Pp1 pointe maintenant vers la page delta de la fusion.
Étape 2 : la ligne représentant la valeur de clé 7 dans la page non-feuille Pp1 doit être supprimée, et l’entrée de la valeur de clé 10 doit être mise à jour pour pointer vers P1. Pour ce faire, une nouvelle page non-feuille Pp2 est allouée, et toutes les lignes de la page Pp1 sont copiées à l’exception de la ligne représentant la valeur de clé 7. Ensuite, la ligne de la valeur de clé 10 est mise à jour pour pointer vers la page P1. Après cela, en une seule étape atomique, l’entrée de la table de mappage des pages pointant vers Pp1 est mise à jour pour pointer vers Pp2.
Pp1 n’est plus accessible.
Étape 3 : les pages de niveau feuille P2 et P1 sont fusionnées, et les pages delta sont supprimées. Pour ce faire, une nouvelle page P3 est allouée, les lignes des pages P2 et P1 sont fusionnées, et les modifications des pages delta sont ajoutées à la nouvelle page P3. Ensuite, en une seule opération atomique, l'entrée de la table de mappage des pages pointant vers la page P1 est mise à jour pour pointer vers la page P3.
Considérations relatives aux performances pour les index non cluster à mémoire optimisée
Les performances d'un index non-clusterisé sont meilleures que celles des index de hachage lors de l'interrogation d'une table optimisée pour la mémoire avec des prédicats d'inégalité.
Une colonne dans une table optimisée en mémoire peut faire partie d'un index de hachage et d'un index non cluster.
Lorsqu'une colonne clé d'un index non-cluster contient un grand nombre de valeurs dupliquées, les performances peuvent baisser lors des mises à jour, des insertions et des suppressions. Une façon d'améliorer les performances dans cette situation consiste à ajouter une colonne qui a une meilleure sélectivité dans la clé d'index.
Métadonnées d’index
Pour examiner les métadonnées d’index telles que les définitions d’index, les propriétés et les statistiques de données, utilisez les vues système suivantes :
- sys.objects
- sys.indexes
- sys.index_columns
- sys.columns
- sys.types
- sys.partitions
- sys.internal_partitions
- sys.dm_db_index_usage_stats
- sys.dm_db_partition_stats
- sys.dm_db_index_operational_stats
Les vues précédentes s’appliquent à tous les types d’index. Pour les index columnstore, utilisez également les vues suivantes :
- sys.column_store_row_groups
- sys.column_store_segments
- sys.column_store_dictionaries
- sys.dm_column_store_object_pool
- sys.dm_db_column_store_row_group_operational_stats
- sys.dm_db_column_store_row_group_physical_stats
Pour les index columnstore, toutes les colonnes sont stockées dans les métadonnées sous forme de colonnes incorporées. L'index columnstore n'a pas de colonnes clés.
Pour les index sur des tables mémoire optimisées, utilisez également les vues suivantes :
- sys.hash_indexes
- sys.dm_db_xtp_hash_index_stats
- sys.dm_db_xtp_index_stats
- sys.dm_db_xtp_nonclustered_index_stats
- sys.dm_db_xtp_object_stats
- sys.dm_db_xtp_table_memory_stats
- sys.memory_optimized_tables_internal_attributes
Contenu connexe
- CRÉER UN INDEX (Transact-SQL)
- Optimiser la maintenance des index pour améliorer les performances des requêtes et réduire la consommation des ressources
- Tables et index partitionnés
- Index sur des tables optimisées en mémoire
- Index Columnstore : vue d’ensemble
- Index sur les colonnes calculées
- Paramétrer les index non-cluster avec les suggestions d’index manquants