Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
S’applique à :![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Base de données SQL dans Microsoft Fabric
Base de données SQL dans Microsoft Fabric
Planification des tâches du système d'exploitation
Les threads sont les plus petites unités de traitement pouvant être exécutées par un système d'exploitation. Ils permettent de séparer la logique d'application en plusieurs chemins d'exécution simultanée. Les threads sont utiles lorsque des applications complexes comprennent un grand nombre de tâches à exécuter simultanément.
Lorsqu'un système d'exploitation exécute une instance d'application, il crée une unité appelée processus pour gérer cette instance. Ce processus est associé à un thread d’exécution. Il s'agit de la série d'instructions de programmation exécutées par le code de l'application. Par exemple, si une application simple comprend un seul jeu d'instructions pouvant être exécutées en série, ce jeu d’instructions est traité comme une tâche unique et il n'existe qu'un seul chemin d'exécution, ou thread, dans toute l'application. Il est possible que les applications plus complexes aient plusieurs tâches pouvant être exécutées simultanément, mais pas en série. Une application peut le faire en démarrant des processus séparés pour chaque tâche, ce qui est une opération nécessitant de nombreuses ressources, ou en démarrant des threads séparés, ce qui nécessite relativement moins de ressources. De plus, l'exécution de chaque thread peut être programmée indépendamment des autres threads du même processus.
Les threads permettent aux applications complexes d'utiliser plus efficacement un processeur (UC), même sur des ordinateurs dotés d'une seule UC. Avec un processeur, un seul thread peut s'exécuter à la fois. Si un thread exécute une longue opération qui n'utilise pas l'UC, comme par exemple la lecture ou l'écriture sur le disque, un autre thread peut être exécuté avant la fin de la première opération. La possibilité d'exécuter des threads pendant que d'autres attendent la fin d'une opération permet à l'application d'optimiser l'utilisation de l'UC. Cela est particulièrement vrai pour les applications multi-utilisateurs qui utilisent beaucoup d'E/S disque, par exemple un serveur de bases de données. Les ordinateurs dotés de plusieurs UC peuvent exécuter simultanément un thread par UC. Ainsi, si un ordinateur comprend huit processeurs, il peut exécuter huit threads en même temps.
Planification de tâches SQL Server
Dans l'étendue de SQL Server, une requête est la représentation logique d'une requête ou d'un lot. Une requête représente également des opérations requises par des threads de système, telles qu’un point de contrôle ou un enregistreur de journal. Les requêtes existent dans différents états pendant toute leur durée de vie et peuvent accumuler des attentes lorsque les ressources requises pour exécuter la requête, comme des verrous ou loquets, ne sont pas disponibles. Pour plus d’informations sur les états des requêtes, consultez sys.dm_exec_requests.
Tâches
Une tâche représente l’unité de travail à effectuer pour exécuter la requête. Une ou plusieurs tâches peuvent être attribuées à une seule requête.
- Les requêtes parallèles comportent plusieurs tâches actives qui sont exécutées simultanément plutôt qu'en série, avec une tâche parente (ou une tâche qui coordonne) et plusieurs tâches enfants. Un plan d'exécution pour une requête parallèle peut avoir des branches en série - des zones du plan avec des opérateurs qui n'exécutent pas en parallèle. La tâche parente est également chargée de l’exécution de ces opérateurs en série.
- Les requêtes en série n'ont qu'une seule tâche active à un moment donné de leur exécution. Les tâches existent dans différents états pendant toute leur durée de vie. Pour plus d’informations sur les états des tâches, consultez sys.dm_os_tasks. Les tâches dans l’état SUSPENDED attendent que les ressources requises pour exécuter la tâche soient disponibles. Pour plus d’informations sur les tâches en attente, consultez sys. dm_os_waiting_tasks.
Collaborateurs
Un thread de travail SQL Server, également appelé Worker ou thread, est une représentation logique d'un thread de système d'exploitation. Lors de l'exécution de requêtes en série, le moteur de base de données SQL Server génère un Worker pour exécuter la tâche active (1:1). Lors de l’exécution de requêtes parallèles en mode en ligne, le moteur de base de données SQL Server affecte un Worker pour coordonner les travailleurs enfants chargés de l’exécution des tâches qui leur sont attribuées (1:1), appelées le thread parent (ou thread de coordination). Un thread parent est associé à un thread parent. Le thread parent est le point d’entrée de la demande et existe même avant que le moteur n’analyse une requête. Les principales responsabilités du thread parent sont les suivantes :
- Coordonner une analyse parallèle.
- Démarrer des processus enfants parallèles.
- Collecter les lignes des threads parallèles et les envoyer au client.
- Effectuer des agrégations locales et globales.
Remarque
Si un plan de requête a des branches en série et parallèles, l’une des tâches parallèles est chargée de l’exécution de la branche en série.
Le nombre de threads de travail générés pour chaque tâche dépend de ce qui suit :
Si la requête était éligible pour le parallélisme comme déterminé par l’optimiseur de requête.
Détermine le degré de parallélisme (DOP) effectif disponible dans le système en fonction de la charge actuelle. Cela peut diverger du degré de parallélisme estimé, qui est basé sur la configuration du serveur pour le degré maximal de parallélisme (MAXDOP). Par exemple, la configuration du serveur pour MAXDOP peut être 8, mais le DOP disponible au moment de l’exécution peut être de 2 seulement, ce qui affecte les performances des requêtes. La pression de la mémoire et le manque de travailleurs sont deux conditions qui réduisent la disponibilité des DOP au moment de l'exécution.
Remarque
La limite du degré maximal de parallélisme (MAXDOP) est spécifiée par tâche, pas par requête. Cela signifie que lors d’une exécution de requête parallèle, une seule requête peut générer plusieurs tâches jusqu’à la limite de MAXDOP et que chaque tâche utilisera un worker. Pour plus d’informations sur MAXDOP, consultez Configurer l’option de configuration serveur du degré maximal de parallélisme.
Planificateurs
Un planificateur, également appelé planificateur SOS, gère les threads de travail nécessitant un temps de traitement pour effectuer le travail résultant de tâches. Chaque planificateur est mappé à un processeur (UC) individuel. La durée pendant laquelle un Worker peut rester actif dans un planificateur est appelée quantum de système d’exploitation, avec un maximum de 4 ms. Une fois que son temps de quantum a expiré, un Worker consacre son temps à d’autres Workers ayant besoin d’accéder aux ressources du processeur et change d’état. Cette coopération entre les Workers pour optimiser l’accès aux ressources du processeur est appelée planification coopérative, également connue sous le nom de planification non préemptive. À son tour, la modification de l’état du travailleur est propagée à la tâche associée à ce travailleur ainsi qu’à la requête associée à la tâche. Pour plus d'informations sur les états des travailleurs, consultez sys.dm_os_workers. Pour plus d'informations sur les planificateurs, consultez sys.dm_os_schedulers.
En résumé, une requête peut générer une ou plusieurs tâches pour effectuer des unités de travail. Chaque tâche est assignée à un thread de travail qui est responsable de l’exécution de la tâche. Chaque thread de travail doit être planifié (placé sur un planificateur) pour l’exécution active de la tâche.
Examinez le cas suivant :
- Worker 1 est une tâche de longue durée, par exemple une requête de lecture utilisant la lecture en avance sur des tables stockées sur disque. Worker 1 trouve les pages de données requises qui se trouvent déjà dans le pool de mémoires tampons. Il n’est donc pas nécessaire d’attendre les opérations d’E/S et peut consommer son quantum complet avant de générer.
- Worker 2 exécute des tâches subordonnées plus courtes et, par conséquent, doit être généré avant l’épuisement de son quantum complet.
Dans ce scénario et jusqu'à SQL Server 2014 (12.x), Worker 1 est autorisé à monopoliser le planificateur en ayant plus de temps quantum global.
À partir de SQL Server 2016 (13.x), la planification coopérative prend en compte la planification LDF (Large Deficit First). Avec la planification LDF, les modèles d’utilisation quantum sont monitorés et un thread de travail ne monopolise pas un planificateur. Dans le même scénario, Worker 2 est autorisé à consommer des quantums répétitifs avant que Worker 1 ne soit autorisé à plus de quantum, ce qui empêche Worker 1 de monopoliser le planificateur dans un modèle peu convivial.
Planification de tâches parallèles
Imaginez un SQL Server configuré avec MaxDOP 8, et l'affinité du processeur est configurée pour 24 UC (planificateurs) sur les nœuds NUMA 0 et 1. Les planificateurs de 0 à 11 appartiennent au nœud NUMA 0, les planificateurs de 12 à 23 appartiennent au nœud NUMA 1. Une application envoie la requête suivante (request) au moteur de base de données :
SELECT h.SalesOrderID,
h.OrderDate,
h.DueDate,
h.ShipDate
FROM Sales.SalesOrderHeaderBulk AS h
INNER JOIN Sales.SalesOrderDetailBulk AS d
ON h.SalesOrderID = d.SalesOrderID
WHERE (h.OrderDate >= '2014-3-28 00:00:00');
Conseil
L’exemple de requête peut être exécuté à l’aide de la base de données AdventureWorks2016_EXT sample database. Les tables Sales.SalesOrderHeader et Sales.SalesOrderDetail ont été augmentées 50 fois et renommées en Sales.SalesOrderHeaderBulk et Sales.SalesOrderDetailBulk.
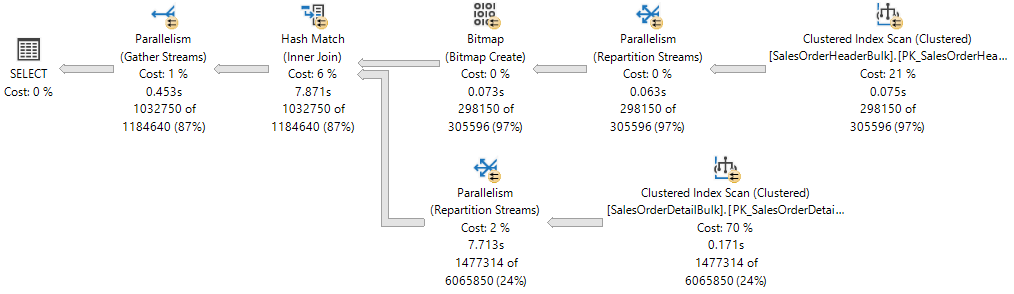
Le plan d’exécution affiche une Jointure de hachage entre deux tables, et chacun des opérateurs exécutés en parallèle, comme indiqué par le cercle jaune avec deux flèches. Chaque opérateur de parallélisme est une branche différente dans le plan. Par conséquent, il existe trois branches dans le plan d'exécution suivant.
Remarque
Si vous visualisez un plan d’exécution comme une arborescence, une branche est une zone du plan qui regroupe un ou plusieurs opérateurs entre les opérateurs de parallélisme, également appelés itérateurs d’échange. Pour plus d’informations sur les opérateurs de plan, consultez le Guide de référence des opérateurs logiques et physiques de Showplan.
Bien qu’il y ait trois branches dans le plan d’exécution, à tout moment pendant l’exécution, seules deux branches peuvent s’exécuter simultanément dans ce plan d’exécution :
- La branche dans laquelle une analyse d’index clusterisé est utilisée sur
Sales.SalesOrderHeaderBulk(entrée de construction de la jointure) s’exécute seule. - Ensuite, la branche dans laquelle une Analyse d’index cluster est utilisée sur le
Sales.SalesOrderDetailBulk(entrée de sonde de la jointure) s’exécute simultanément avec la branche dans laquelle le Bitmap a été créé et où le Hash Match s’exécute.
Le plan d’exécution de requêtes XML montre que 16 threads de travail ont été réservés et utilisés sur le nœud NUMA 0 :
<ThreadStat Branches="2" UsedThreads="16">
<ThreadReservation NodeId="0" ReservedThreads="16" />
</ThreadStat>
La réservation de thread garantit que le moteur de base de données dispose de suffisamment de threads de travail pour effectuer toutes les tâches qui sont nécessaires pour la requête. Les threads peuvent être réservés sur plusieurs nœuds NUMA ou être réservés dans un seul nœud NUMA. La réservation de thread est effectuée au moment de l’exécution avant le démarrage de l’exécution, et dépend de la charge du planificateur. Le nombre de threads de travail réservés est dérivé de façon générique à partir de la formule concurrent branches * runtime DOP et exclut le thread de travail parent. Chaque branche est limitée à un nombre de threads de travail égaux à MaxDOP. Dans cet exemple, il existe deux branches simultanées et MaxDOP a pour valeur 8, par conséquent 2 * 8 = 16.
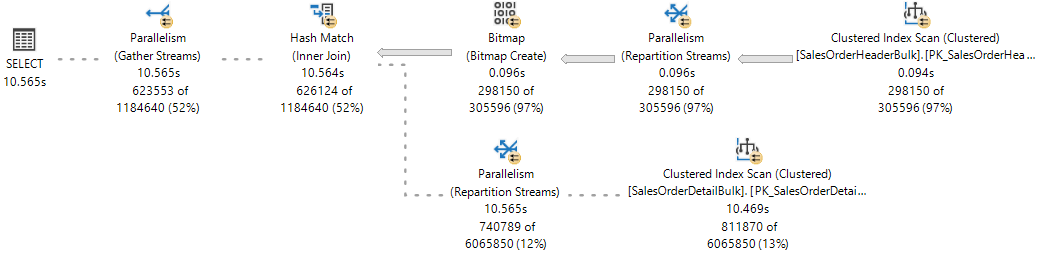
Pour référence, observez le plan d’exécution en direct à partir de Statistiques des Requêtes en direct, où une branche est terminée et que deux branches s’exécutent simultanément.
Le moteur de base de données SQL Server assigne un thread de travail pour exécuter une tâche active (1:1), qui peut être observée pendant l'exécution de la requête en interrogeant la DMV sys. dm_os_tasks, comme indiqué dans l'exemple suivant :
SELECT parent_task_address, task_address,
task_state, scheduler_id, worker_address
FROM sys.dm_os_tasks
WHERE session_id = <insert_session_id>
ORDER BY parent_task_address, scheduler_id;
Conseil
La colonne parent_task_address est toujours NULL pour la tâche parente.
Conseil
Sur un moteur de base de données SQL Server très occupé, il est possible de voir un certain nombre de tâches actives supérieur à la limite fixée par les threads réservés. Ces tâches peuvent appartenir à une branche qui n’est plus utilisée et qui sont dans un état transitoire, en attente de nettoyage.
Voici le jeu de résultats. Notez qu'il y a 17 tâches actives pour les branches en cours d'exécution : 16 tâches enfants correspondant aux threads réservés, en plus de la tâche parente, ou tâche de coordination.
| adresse de la tâche parente | adresse_tâche | état_de_tâche | ID de planificateur | adresse_du_travailleur |
|---|---|---|---|---|
| ZÉRO | 0x000001EF4758ACA8 |
SUSPENDU | 3 | 0x000001EFE6CB6160 |
| 0x000001EF4758ACA8 | 0x000001EFE43F3468 | SUSPENDU | 0 | 0x000001EF6DB70160 |
| 0x000001EF4758ACA8 | 0x000001EEB243A4E8 | SUSPENDU | 0 | 0x000001EF6DB7A160 |
| 0x000001EF4758ACA8 | 0x000001EC86251468 | SUSPENDU | 5 | 0x000001EEC05E8160 |
| 0x000001EF4758ACA8 | 0x000001EFE3023468 | SUSPENDU | 5 | 0x000001EF6B46A160 |
| 0x000001EF4758ACA8 | 0x000001EFE3AF1468 | SUSPENDU | 6 | 0x000001EF6BD38160 |
| 0x000001EF4758ACA8 | 0x000001EFE4AFCCA8 | SUSPENDU | 6 | 0x000001EF6ACB4160 |
| 0x000001EF4758ACA8 | 0x000001EFDE043848 | SUSPENDU | 7 | 0x000001EEA18C2160 |
| 0x000001EF4758ACA8 | 0x000001EF69038108 | SUSPENDU | 7 | 0x000001EF6AEBA160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD8CA8 | SUSPENDU | 8 | 0x000001EFCB6F0160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD88C8 | SUSPENDU | 8 | 0x000001EF6DC46160 |
| 0x000001EF4758ACA8 | 0x000001EFBCC54108 | SUSPENDU | 9 | 0x000001EFCB886160 |
| 0x000001EF4758ACA8 | 0x000001EC86279468 | SUSPENDU | 9 | 0x000001EF6DE08160 |
| 0x000001EF4758ACA8 | 0x000001EFDE901848 | SUSPENDU | 10 | 0x000001EFF56E0160 |
| 0x000001EF4758ACA8 | 0x000001EF6DB32108 | SUSPENDU | 10 | 0x000001EFCC3D0160 |
| 0x000001EF4758ACA8 | 0x000001EC8628D468 | SUSPENDU | 11 | 0x000001EFBFA4A160 |
| 0x000001EF4758ACA8 | 0x000001EFBD3A1C28 | SUSPENDU | 11 | 0x000001EF6BD72160 |
Notez que chacune des 16 tâches enfants a un thread de travail différent affecté (vu dans la colonne worker_address), mais que tous les workers sont affectés au même pool de huit planificateurs (0, 5, 6, 7, 8, 9, 10, 11) et que la tâche parente est affectée à un planificateur en dehors de ce pool (3).
Importante
Une fois le premier ensemble de tâches parallèles sur une branche donnée planifiée, le moteur de base de données utilise ce même pool de planificateurs pour toutes les tâches supplémentaires sur d'autres branches. Cela signifie que le même ensemble de planificateurs sera utilisé pour toutes les tâches parallèles dans le plan d’exécution entier, limité uniquement par MaxDOP.
Le moteur de base de données SQL Server essaiera toujours d’affecter des planificateurs du même nœud NUMA pour l’exécution des tâches et de les affecter de manière séquentielle (en mode tourniquet) si des planificateurs sont disponibles. Toutefois, le thread de travail affecté à la tâche parente peut être placé dans un autre nœud NUMA à partir d’autres tâches.
Un thread de travail ne peut rester actif dans le planificateur que pour la durée de son quantum (4 ms) et doit générer son planificateur après que ce quantum se soit écoulé, de sorte qu'un thread de travail affecté à une autre tâche peut devenir actif. Lorsque le quantum d'un travailleur expire et qu'il n'est plus actif, la tâche correspondante est placée dans une file d'attente FIFO à l'état RUNNABLE, jusqu'à ce qu'elle repasse à l'état RUNNING. Cela suppose que la tâche n'exige pas l'accès à des ressources indisponibles pour le moment, telles qu'un verrou, auquel cas la tâche serait mise dans l'état SUSPENDED au lieu de RUNNABLE, jusqu'à ce que ces ressources soient de nouveau disponibles.
Conseil
Pour la sortie de la vue DMV indiquée ci-dessus, toutes les tâches actives sont en état SUSPENDU. Pour plus d’informations sur les tâches en attente, vous pouvez interroger la DMV sys. dm_os_waiting_tasks.
En résumé, une demande parallèle génère plusieurs tâches. Chaque tâche doit être affectée à un seul thread de travail. Chaque thread de travail doit être affecté à un seul planificateur. Ainsi, le nombre de planificateurs en cours d'utilisation ne peut pas dépasser le nombre de tâches parallèles par branche, que définit l'indicateur de requête ou la configuration MaxDOP. Le thread de coordination ne contribue pas à la limite MaxDOP.
Allocation de threads aux processeurs
Par défaut, chaque instance SQL Server commence chaque thread, et le système d'exploitation répartit les threads à partir des instances SQL Server entre les processeurs (UC) sur un ordinateur en fonction de la charge. Si l'affinité de processus a été activée au niveau du système d'exploitation, ce dernier attribue chaque thread à une UC spécifique. En revanche, le moteur de base de données SQL Server attribue des threads de travail aux planificateurs qui distribuent les threads de manière équitable entre les processeurs en mode tourniquet (round robin).
Pour exécuter des travaux multitâches, par exemple lorsque plusieurs applications accèdent au même ensemble d’UC, le système d’exploitation déplace parfois les threads de travail entre les différentes UC. Bien qu’efficace du point de vue du système d’exploitation, cette activité peut réduire les performances de SQL Server sous des charges de système intenses, car des données sont rechargées de façon répétée dans chaque cache de processeur. L'affectation d’UC à des threads spécifiques permet d'améliorer les performances dans ces conditions en éliminant les rechargements de processeurs et en réduisant la migration des threads entre les UC (réduisant ainsi les changements de contexte) ; une telle association entre un thread et un processeur est appelée affinité du processeur. Si l'affinité processeur a été activée, le système d'exploitation attribue chaque thread à un processeur spécifique.
L’option de masque d’affinité est définie à l’aide d’ALTER SERVER CONFIGURATION. Lorsque le masque d'affinité n'est pas défini, l'instance de SQL Server alloue les threads de travail de manière équitable entre les planificateurs qui n'ont pas été masqués.
Attention
Évitez de configurer l'affinité de processeur dans le système d'exploitation et le masque d'affinité dans SQL Server. Ces paramètres tentent d'obtenir le même résultat et, si les configurations sont incohérentes, les résultats risquent d'être imprévisibles. Pour plus d'informations, consultez l’option de masque d'affinité.
Le regroupement de threads permet d'optimiser les performances lorsque de nombreux clients sont connectés au serveur. Habituellement, un thread de système d'exploitation séparé est créé pour chaque demande de requête. Cependant, s'il existe des centaines de connexions au serveur, l'utilisation d'un thread par demande de requête peut consommer de grandes quantités de ressources système. L'option Nombre maximum de threads de travail permet à SQL Server de créer un pool de threads de travail afin de servir un grand nombre de demandes de requête, ce qui améliore les performances.
Utilisation de l'option de regroupement léger
Importante
À compter de SQL Server 2025 (17.x), la fonctionnalité en mode fibre activée par l’option lightweight pooling est déconseillée et est prévue pour la suppression dans une version ultérieure de SQL Server. En raison de problèmes de stabilité et de compatibilité connus, Microsoft vous recommande d’éviter d’utiliser cette fonctionnalité dans n’importe quelle version de SQL Server.
La surcharge qu’implique le basculement des contextes de thread peut ne pas être significative. La plupart des instances de SQL Server ne perçoivent aucune différence de performances entre les valeurs 0 et 1 de l'option de regroupement léger. Les seules instances de SQL Server susceptibles de tirer parti de l’option Regroupement léger sont celles dont l’ordinateur présente les caractéristiques suivantes :
- Un serveur multiprocesseur de grande taille
- Toutes les UC fonctionnent près de leur capacité maximale
- Fréquence élevée de basculement des contextes
Ces systèmes peuvent augmenter légèrement leurs performances si la valeur 1 est attribuée à l’option Regroupement léger.
Importante
N'utilisez pas la planification en mode fibre pour les opérations courantes. Cela peut réduire les performances en bloquant les avantages habituels du basculement de contexte. Par ailleurs, certains composants de SQL Server ne peuvent pas fonctionner correctement en mode fibre. Pour plus d’informations, reportez-vous au regroupement léger.
Exécution de threads et de fibres
Microsoft Windows utilise un système de priorité numérique qui va de 1 à 31 pour planifier l'exécution des threads. Le chiffre zéro est réservé à l'usage du système d'exploitation. Lorsque plusieurs threads attendent d'être exécutés, Windows envoie le thread dont la priorité est la plus élevée.
Par défaut, chaque instance de SQL Server est une priorité 7 (priorité dite normale). Ceci octroie aux threads SQL Server une priorité suffisamment élevée pour obtenir les ressources UC dont ils ont besoin sans pénaliser les autres applications.
Importante
Cette fonctionnalité sera supprimée dans une version future de SQL Server. Évitez d'utiliser cette fonctionnalité dans de nouveaux travaux de développement, et prévoyez de modifier les applications qui utilisent actuellement cette fonctionnalité.
L’option de configuration Renforcement de priorité peut être utilisée pour augmenter la priorité des threads d’une instance de SQL Server à 13. (priorité dite élevée). Cette valeur donne aux threads SQL Server une priorité plus élevée que la plupart des autres applications. Par conséquent, les threads SQL Server ont plutôt tendance à être distribués chaque fois qu'ils sont prêts à être exécutés et ne sont pas devancés par les threads d'autres applications. Ceci peut améliorer les performances lorsqu’un serveur n’exécute que des instances de SQL Server et aucune autre application. Cependant, si une opération nécessitant beaucoup de mémoire se produit dans SQL Server, les autres applications n'auront sans doute pas une priorité suffisamment élevée pour devancer le thread SQL Server.
Si vous utilisez plusieurs instances de SQL Server sur un ordinateur et activez le renforcement de priorité pour certaines d’entre elles uniquement, les performances des instances exécutées avec une priorité normale peuvent être compromises. Les performances d’autres applications et composants sur le serveur peuvent aussi diminuer si l’option Renforcement de priorité est activée. C'est pourquoi elle doit être utilisée dans certaines conditions bien définies.
Ajout d’un processeur à chaud
Importante
À compter de SQL Server 2025 (17.x), la fonctionnalité d’ajout à chaud du processeur est déconseillée et est prévue pour la suppression dans une version ultérieure de SQL Server. En raison de problèmes de stabilité connus, Microsoft vous recommande d’éviter d’utiliser cette fonctionnalité dans l’administration de SQL Server dans n’importe quelle version de SQL Server.
L'ajout d'un processeur à chaud est la capacité d'ajouter dynamiquement des processeurs à un système en cours d'exécution. L'ajout de processeurs peut s'effectuer physiquement en ajoutant du matériel, logiquement en partitionnant du matériel en ligne ou virtuellement par l'intermédiaire d'une couche de virtualisation.
Spécifications pour l’ajout de processeurs à chaud :
- Nécessite un matériel prenant en charge l'ajout de processeurs à chaud.
- Nécessite une version prise en charge de Windows Server Datacenter ou de l'édition Entreprise. À compter de Windows Server 2012, l'ajout à chaud est pris en charge sur l'édition Standard.
- Nécessite l'édition SQL Server Entreprise.
- SQL Server ne peut pas être configuré pour utiliser la configuration NUMA logicielle. Pour plus d’informations sur la configuration NUMA logicielle, consultez Soft-NUMA (SQL Server).
SQL Server ne commence pas automatiquement à utiliser les processeurs une fois que ceux-ci ont été ajoutés. Cela empêche SQL Server d’utiliser des processeurs qui peuvent être ajoutés à d’autres fins. Après avoir ajouté des processeurs, exécutez l’instruction RECONFIGURE afin que SQL Server reconnaisse les nouvelles UC en tant que ressources disponibles.
Si le masque d’affinité 64 est configuré, il doit être modifié pour utiliser les nouveaux processeurs.
Recommandations pour l'exécution de SQL Server sur des ordinateurs comportant plus de 64 processeurs
Affectation de threads matériels aux processeurs
N'utilisez pas les options de configuration de serveur masque d'affinité (affinity mask) et masque d'affinité 64 (affinity64 mask) pour lier les processeurs à des threads spécifiques. Ces options sont limitées à 64 unités centrales. Utilisez l’option SET PROCESS AFFINITY d’ALTER SERVER CONFIGURATION à la place.
Gestion de la taille des fichiers journaux de transactions
Ne comptez pas sur la croissance automatique pour augmenter la taille du fichier journal de transactions. L'augmentation du journal des transactions doit être un processus série. L’extension du journal peut empêcher la poursuite d’opérations d’écriture de transactions jusqu’à ce que l’extension du journal soit terminée. Pré-allouez plutôt l'espace des fichiers journaux en définissant leur taille avec une valeur suffisamment élevée pour prendre en charge la charge de travail habituelle de l'environnement.
Définition du degré maximal de parallélisme pour les opérations d'index
Les performances des opérations d'index telles que la création ou la reconstruction d'index peuvent être améliorées sur les ordinateurs qui possèdent de nombreuses unités centrales en définissant temporairement le mode de récupération de la base de données sur le mode de récupération simple ou de journalisation en bloc. Ces opérations d’index peuvent générer une activité de journal significative et les conflits de journal peuvent affecter le choix optimal du degré de parallélisme (DOP) effectué par SQL Server.
En plus de l’ajustement de l’option de configuration serveur du degré maximal de parallélisme (MAXDOP), envisagez d’ajuster le parallélisme pour des opérations d’index avec l’option MAXDOP. Pour plus d’informations, consultez Configurer des opérations d’index parallèles. Pour plus d'informations et de recommandations sur l'ajustement de l'option de configuration du serveur Degré maximal de parallélisme, consultez Configurer l'option de configuration serveur Degré maximal de parallélisme.
Option de nombre maximal de threads de travail
SQL Server configure l'option de configuration serveur max worker threads de façon dynamique au démarrage. SQ utilise le nombre d'UC disponibles et l'architecture système pour déterminer cette configuration serveur pendant le démarrage à l'aide d'une formule documentée.
Cette option est une option avancée et doit être modifiée uniquement par un professionnel de base de données expérimenté.
Si vous suspectez un problème de performance, celui ne vient probablement pas de la disponibilité des threads. Le problème est plus vraisemblablement causé par des opérations d’E/S qui contraignent les threads de worker à attendre. Nous vous conseillons d’identifier la cause racine d’un problème de performance avant de changer le paramètre max worker threads. Cependant, si vous devez définir manuellement le nombre maximum de threads de travail, cette valeur de configuration doit toujours être supérieure ou égale à sept fois le nombre de CPU présents sur le système. Pour plus d’informations, consultez Configurer l’option max worker threads.
Éviter l'utilisation de Trace SQL et du Générateur de profils SQL
Nous vous recommandons de ne pas utiliser Trace SQL ni SQL Profiler dans un environnement de production. La surcharge induite par l'exécution de ces outils augmente également proportionnellement au nombre d'unités centrales. Si vous devez utiliser Trace SQL dans un environnement de production, limitez le nombre d'événements de trace au minimum. Profilez et testez avec soin chaque événement de trace sous charge et évitez d'utiliser des combinaisons d'événements qui affectent les performances de façon significative.
Importante
Le traçage SQL et SQL Server Profiler sont obsolètes. L'espace de noms Microsoft.SqlServer.Management.Trace qui contient les objets Trace SQL Server et Replay est également déconseillé.
Cette fonctionnalité sera supprimée dans une version future de SQL Server. Évitez d'utiliser cette fonctionnalité dans de nouveaux travaux de développement, et prévoyez de modifier les applications qui utilisent actuellement cette fonctionnalité.
Utilisez plutôt des événements étendus. Pour plus d’informations sur les événements étendus, consultez Démarrage rapide : Événements étendus dans SQL Server et SSMS XEvent Profiler.
Remarque
Le Profiler SQL Server pour les charges de travail d'Analysis Services n'est PAS obsolète et reste pris en charge.
Définition du nombre de fichiers de données tempdb
Le nombre de fichiers dépend du nombre de processeurs (logiques) sur l’ordinateur. En règle générale, si le nombre de processeurs logiques est inférieur ou égal à huit, utilisez le même nombre de fichiers de données que de processeurs logiques. Si le nombre de processeurs logiques est supérieur à huit, utilisez huit fichiers de données et, si le conflit persiste, augmentez le nombre de fichiers de données par multiples de quatre pour réduire le conflit à un niveau acceptable ou bien modifiez la charge de travail/le code. N'oubliez pas non plus les autres suggestions pour tempdb, disponibles dans Optimisation des performances de tempdb dans SQL Server.
Toutefois, en prenant soigneusement en compte les besoins de concurrence de tempdb, vous pouvez réduire la surcharge de la base de données. Par exemple, si un système comporte 64 unités centrales et qu'habituellement seules 32 requêtes utilisent tempdb, l'augmentation du nombre de fichiers tempdb à 64 n'améliorera pas les performances.
Composants SQL Server qui peuvent utiliser plus de 64 unités centrales
Le tableau suivant dresse la liste des composants de SQL Server et indique s’ils peuvent utiliser plus de 64 unités centrales.
| Nom du processus | Programme exécutable | Utilisation de plus de 64 unités centrales |
|---|---|---|
| Moteur de base de données SQL Server | Sqlserver.exe | Oui |
| Services de rapports | Rs.exe | Non |
| Services d'Analyse | As.exe | Non |
| Services d'intégration | Is.exe | Non |
| Courtier de services | Sb.exe | Non |
| Recherche en texte intégral | Fts.exe | Non |
| Agent de SQL Server | Sqlagent.exe | Non |
| SQL Server Management Studio | Ssms.exe | Non |
| Programme d'installation de SQL Server | Setup.exe | Non |