Comment fonctionne DPM ?
Important
Cette version de Data Protection Manager (DPM) a atteint la fin du support. Nous vous recommandons de procéder à la mise à niveau vers DPM 2022.
La méthode Utilisée par System Center Data Protection Manager (DPM) pour protéger les données varie en fonction du type de données en cours de protection et de la méthode de protection que vous sélectionnez. Cet article sert d’introduction à la façon dont DPM fonctionne. Il est destiné à éduquer ceux qui sont nouveaux à DPM, ou ceux qui peuvent avoir des questions de base sur le fonctionnement de DPM. Cet article traite des processus de protection basés sur disque, des processus de protection sur bande, du processus de récupération et de la stratégie de protection.
Processus de protection sur disque
Pour assurer la protection des données sur disque, le serveur DPM crée et gère un réplica ou une copie des données qui se trouve sur des serveurs protégés. Les réplicas sont stockés dans le pool de stockage, qui se compose d’un ou plusieurs volumes mis en forme ReFs sur le serveur DPM. L’illustration suivante montre la relation de base entre un volume protégé et son réplica.
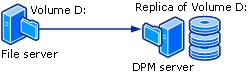
Que vous protégez des données de fichier ou des données d’application, la protection commence par la création d’un réplica de la source de données.
Le réplica est synchronisé ou mis à jour à intervalles réguliers en fonction des paramètres que vous configurez. La méthode utilisée par DPM pour synchroniser le réplica dépend du type de données en cours de protection. Pour plus d’informations, consultez Le processus de Synchronisation des données hronization et le processus d’application Synchronisation des données hronization. Si un réplica est identifié comme incohérent, DPM effectue une vérification de cohérence, qui est une vérification de bloc par bloc du réplica sur la source de données.
Un exemple simple de configuration de protection se compose d’un serveur DPM et d’un ordinateur protégé. L’ordinateur est protégé lorsque vous installez un agent de protection DPM sur l’ordinateur et ajoutez ses données à un groupe de protection.
Les agents de protection suivent les modifications apportées aux données protégées et transfèrent les modifications au serveur DPM. L’agent de protection identifie également les données sur un ordinateur qui peut être protégé et qui est impliqué dans le processus de récupération. Vous devez installer un agent de protection sur chaque ordinateur que vous souhaitez protéger à l’aide de DPM. Les agents de protection peuvent être installés par DPM, ou vous pouvez installer manuellement des agents de protection à l’aide d’applications telles que Systems Management Server (SMS).
Les groupes de protection sont utilisés pour gérer la protection des sources de données sur les ordinateurs. Un groupe de protection est un ensemble de sources de données qui partagent la même configuration de protection. La configuration de la protection est la collection de paramètres communs à un groupe de protection, comme le nom du groupe de protection, la stratégie de protection, les allocations de disque et la méthode de création de réplica.
DPM stocke un réplica distinct pour chaque membre du groupe de protection dans le pool de stockage. Un membre de groupe de protection peut être l’une des sources de données suivantes :
- Volume, partage ou dossier sur un ordinateur de bureau, un serveur de fichiers ou un cluster de serveurs.
- Un groupe de stockage sur un serveur Exchange ou un cluster de serveurs
- Base de données d’une instance de SQL Server ou de cluster serveur
Remarque
DPM ne protège pas les données stockées dans des lecteurs USB.
Processus de synchronisation des données de fichier
Dans DPM, pour un volume de fichiers ou un partage sur un serveur, l’agent de protection utilise un filtre de volume et le journal des modifications pour déterminer les fichiers qui ont changé, puis effectue une procédure de somme de contrôle pour ces fichiers afin de synchroniser uniquement les blocs modifiés. Pendant la synchronisation, ces modifications sont transférées vers le serveur DPM, puis appliquées au réplica pour synchroniser le réplica avec la source de données. La figure suivante illustre le processus de synchronisation de fichiers.
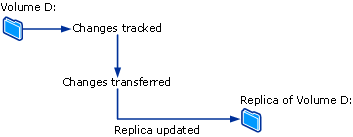
Si un réplica devient incohérent avec sa source de données, DPM génère une alerte qui spécifie l’ordinateur et les sources de données affectés. Pour résoudre le problème, l’administrateur répare le réplica en lançant une synchronisation avec une vérification de cohérence, également appelée simple vérification de cohérence, sur le réplica. Pendant une vérification de cohérence, DPM effectue une vérification de bloc par bloc et répare le réplica pour qu’il soit cohérent avec la source de données.
Vous pouvez planifier une vérification de cohérence quotidienne pour les groupes de protection ou lancer manuellement une vérification de cohérence.
DPM crée un point de récupération pour le membre du groupe de protection à intervalles réguliers, que vous pouvez configurer. Un point de récupération est une version des données depuis laquelle les données peuvent être récupérées.
Processus de synchronisation des données d’application
Pour les données d’application, une fois le réplica créé par DPM, les modifications apportées aux blocs de volume appartenant aux fichiers d’application sont suivies par le filtre de volume.
La façon dont les modifications sont transférées vers le serveur DPM dépend de l’application et du type de synchronisation. L’opération qui est étiquetée synchronisation dans la console administrateur DPM est analogue à une sauvegarde incrémentielle et crée une réflexion précise des données d’application lorsqu’elles sont combinées avec le réplica.
Pendant le type de synchronisation étiqueté sauvegarde complète rapide dans la console administrateur DPM, un instantané VSS (Volume Shadow Copy Service) complet est créé, mais seuls les blocs modifiés sont transférés vers le serveur DPM.
Chaque sauvegarde complète rapide crée un point de récupération pour les données d'application. Si l'application prend en charge les sauvegardes incrémentielles, chaque synchronisation crée également un point de récupération. Le type de synchronisation pris en charge par chaque type de données d’application est résumé comme suit :
Pour les données Exchange protégées, la synchronisation transfère un instantané VSS incrémentiel à l’aide de l’enregistreur VSS Exchange. Des points de récupération sont créés pour chaque synchronisation et sauvegarde complète rapide.
Les bases de données SQL Server fournies en lecture seule, ou qui utilisent le modèle de récupération simple ne prennent pas en charge la sauvegarde incrémentielle. Des points de récupération sont créés pour chaque sauvegarde complète rapide uniquement. Pour toutes les autres bases de données SQL Server, la synchronisation transfère une sauvegarde des journaux de transactions et des points de récupération sont créés pour chaque synchronisation incrémentielle et sauvegarde complète rapide. Le journal de transactions est un enregistrement séquentiel de toutes les transactions qui ont été effectuées sur la base de données depuis la dernière sauvegarde du journal de transactions.
Windows SharePoint Services et Microsoft Virtual Server ne prennent pas en charge la sauvegarde incrémentielle. Des points de récupération sont créés pour chaque sauvegarde complète rapide uniquement.
Les synchronisations incrémentielles demandent moins de temps que l'exécution d'une sauvegarde complète rapide. Toutefois, le temps nécessaire pour récupérer les données augmente à mesure que le nombre de synchronisations augmente. Cela est dû au fait que DPM doit restaurer la dernière sauvegarde complète, puis restaurer et appliquer toutes les synchronisations incrémentielles jusqu’au point dans le temps sélectionné pour la récupération.
Pour accélérer le temps de récupération, DPM effectue régulièrement une sauvegarde complète rapide, un type de synchronisation qui met à jour le réplica pour inclure les blocs modifiés.
Pendant la sauvegarde complète rapide, DPM prend un instantané du réplica avant de mettre à jour le réplica avec les blocs modifiés. Pour permettre des objectifs de point de récupération plus fréquents et pour réduire la fenêtre de perte de données, DPM effectue également des synchronisations incrémentielles dans le temps entre deux sauvegardes complètes rapides.
Comme pour la protection des données de fichier, si un réplica devient incohérent avec sa source de données, DPM génère une alerte qui spécifie quel serveur et quelles sources de données sont affectées. Pour résoudre le problème, l'administrateur répare le réplica en lançant une synchronisation avec vérification de cohérence sur le réplica. Pendant une vérification de cohérence, DPM effectue une vérification de bloc par bloc et répare le réplica pour qu’il soit cohérent avec la source de données.
Vous pouvez planifier une vérification de cohérence quotidienne pour les groupes de protection ou lancer manuellement une vérification de cohérence.
Différence entre les données de fichier et les données d’application
Les données qui existent sur un serveur de fichiers et qui doivent être protégées comme un fichier plat sont appelées données de fichier, comme les fichiers Microsoft Office, les fichiers texte, les fichiers de commandes, etc.
Les données qui existent sur un serveur d’applications et qui nécessitent que DPM sache que l’application se qualifie comme des données d’application, telles que des groupes de stockage Exchange, des bases de données SQL Server, des batteries de serveurs Windows SharePoint Services et des serveurs virtuels.
Chaque source de données est présentée dans la console administrateur DPM en fonction du type de protection que vous pouvez sélectionner pour cette source de données. Par exemple, dans l’Assistant Création d’un groupe de protection, lorsque vous développez un serveur qui contient des fichiers et exécute également un serveur virtuel et une instance d’un serveur SQL Server, les sources de données sont traitées comme suit :
Si vous développez Tous les partages ou tous les volumes, DPM affiche les partages et les volumes sur ce serveur et protège toute source de données sélectionnée dans l’un de ces nœuds en tant que données de fichier.
Si vous développez tous les serveurs SQL, DPM affiche les instances de SQL Server sur ce serveur et protège toute source de données sélectionnée dans ce nœud en tant que données d’application.
Si vous développez Microsoft Virtual Server, DPM affiche la base de données hôte et les machines virtuelles sur ce serveur et protège toute source de données sélectionnée dans ce nœud en tant que données d’application.
Processus de protection sur bande
Lorsque vous utilisez la protection sur disque à court terme et la protection basée sur bande à long terme, DPM peut sauvegarder des données du volume de réplica sur bande afin qu’il n’y ait aucun effet sur l’ordinateur protégé. Lorsque vous utilisez uniquement la protection basée sur bande, DPM sauvegarde les données directement de l’ordinateur protégé sur bande.
DPM protège les données sur bande via une combinaison de sauvegardes complètes et incrémentielles à partir de la source de données protégée (pour une protection à court terme sur bande ou pour une protection à long terme sur bande lorsque DPM ne protège pas les données sur le disque) ou du réplica DPM (pour une protection à long terme sur bande lorsque la protection à court terme est sur disque).
Remarque
Si un fichier a été ouvert lors de la dernière synchronisation du réplica, la sauvegarde de ce fichier à partir du réplica est dans un état cohérent en cas d’incident. Un état cohérent de blocage du fichier contient toutes les données du fichier qui a été conservé sur le disque au moment de la dernière synchronisation. Cela s’applique uniquement aux sauvegardes de système de fichiers. Les sauvegardes d’application sont toujours cohérentes avec l’état de l’application.
Pour connaître les types et planifications de sauvegarde spécifiques, consultez Planification des groupes de protection
Processus de récupération
La méthode de protection des données, basée sur disque ou sur bande ne fait aucune différence avec la tâche de récupération. Vous sélectionnez le point de récupération des données que vous souhaitez récupérer, et DPM récupère les données sur l’ordinateur protégé.
DPM peut stocker un maximum de 448 points de récupération pour chaque membre de fichier d’un groupe de protection. Pour les sources de données d’application, DPM peut stocker jusqu’à 448 sauvegardes complètes express et jusqu’à 96 sauvegardes incrémentielles pour chaque sauvegarde complète rapide. Lorsque les limites de zone de stockage ont été atteintes et que la plage de rétention des points de récupération existants n’est pas encore remplie, les travaux de protection échouent.
Comme expliqué dans Le processus de Synchronisation des données hronization et l’application Synchronisation des données hronization Process, le processus de création de points de récupération diffère entre les données de fichier et les données d’application. DPM crée des points de récupération pour les données de fichier en prenant une cliché instantané du réplica selon une planification que vous configurez. Pour les données d'application, chaque synchronisation et chaque sauvegarde complète rapide créent un point de récupération.
Les administrateurs récupèrent des données à partir de points de récupération disponibles à l’aide de l’Assistant Récupération dans la console Administrateur DPM. Lorsque vous sélectionnez une source de données et un point dans le temps à partir desquels récupérer, DPM vous avertit si les données se trouvent sur bande, que la bande soit en ligne ou hors connexion, et quelles bandes sont nécessaires pour terminer la récupération.
Stratégie de protection
DPM configure la stratégie de protection ou la planification des travaux pour chaque groupe de protection en fonction des objectifs de récupération que vous spécifiez pour ce groupe de protection. Voici quelques exemples d’objectifs de récupération :
Perdre pas plus de 1 heure de données de production
Fournissez-moi une plage de rétention de 30 jours
Rendre les données disponibles pour la récupération pendant 7 ans
Vos objectifs de récupération quantifient les exigences de protection des données de votre organisation. Dans DPM, les objectifs de récupération sont définis par la plage de rétention, la tolérance de perte de données, la planification des points de récupération et, pour les applications de base de données, la planification de sauvegarde complète rapide.
La plage de rétention est la durée pendant laquelle vous avez besoin des données de sauvegarde disponibles. Par exemple, avez-vous besoin de données d’aujourd’hui pour être disponibles une semaine à partir de maintenant ? Deux semaines à partir de maintenant ? Une année à partir de maintenant ?
La tolérance de perte de données est la quantité maximale de perte de données, mesurée dans le temps, acceptable pour les besoins de l’entreprise. Il détermine la fréquence à laquelle DPM doit se synchroniser avec le serveur protégé en collectant les modifications de données du serveur protégé. Vous pouvez modifier la fréquence de synchronisation à n’importe quel intervalle compris entre 15 minutes et 24 heures. Vous pouvez également choisir d'effectuer la synchronisation juste avant la création d'un point de récupération plutôt qu'à un moment précis de la planification.
La planification des points de récupération établit le nombre de points de récupération de ce groupe de protection à créer. Pour la protection des fichiers, vous devez sélectionner les jours et les heures auxquels les points de récupération doivent être créés. Pour la protection des données d'applications qui prennent en charge les sauvegardes incrémentielles, la fréquence de synchronisation détermine la planification du point de récupération. Pour la protection des données des applications qui ne prennent pas en charge les sauvegardes incrémentielles, la planification de sauvegarde complète express détermine la planification du point de récupération.
Remarque
Lorsque vous créez un groupe de protection, DPM identifie le type de données en cours de protection et offre uniquement les options de protection disponibles pour les données.
Processus de découverte automatique
La découverte automatique est le processus quotidien par lequel DPM détecte automatiquement les ordinateurs nouveaux ou supprimés sur le réseau. Une fois par jour, à la fois que vous pouvez planifier, DPM envoie un petit paquet (moins de 10 kilo-octets) au contrôleur de domaine le plus proche. Le contrôleur de domaine répond à la demande LDAP (Lightweight Directory Access Protocol) avec les ordinateurs de ce domaine, et DPM identifie les ordinateurs nouveaux et supprimés. Le trafic réseau créé par le processus de découverte automatique est minimal.
La découverte automatique ne détecte pas les ordinateurs nouveaux et supprimés dans d’autres domaines. Pour installer un agent de protection sur un ordinateur d’un autre domaine, vous devez identifier l’ordinateur à l’aide de son nom de domaine complet.
Télémétrie DPM
DPM ne collecte aucune télémétrie. Si vous envoyez les données à Azure, les informations requises par Sauvegarde Azure sont envoyées à Microsoft. Il ne contient aucune PII.
Télémétrie DPM
Remarque
Applicable à partir de DPM 2019 UR2.
Par défaut, DPM envoie des données de diagnostic et de connectivité à Microsoft. Microsoft les utilise pour assurer et améliorer la qualité, la sécurité et l’intégrité de ses produits et services.
Les administrateurs peuvent désactiver cette fonctionnalité à tout moment. Pour plus d’informations sur les données collectées, consultez gérer les données de télémétrie dans DPM.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour