Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
La boîte à outils d'IA pour VS Code (AI Toolkit) est une extension VS Code qui vous permet de télécharger, de tester, d'affiner et de déployer des modèles d'IA avec vos applications ou dans le cloud. Pour plus d’informations, consultez Vue d’ensemble de l’AI Toolkit.
Remarque
Des documents et didacticiels supplémentaires pour le kit VS Code d'outils IA sont disponibles dans la documentation VS Code : AI Toolkit for Visual Studio Code. Vous trouverez des conseils sur Playground, l’utilisation de modèles IA, l’optimisation des modèles locaux et cloud, etc.
Dans cet article, vous allez apprendre à :
- Configurez un environnement local à ajuster.
- Exécutez un travail d’ajustement.
Prérequis
- Terminé Démarrez avec AI Toolkit pour Visual Studio Code.
- Si vous utilisez un ordinateur Windows pour affiner, installez Windows Subsystem for Linux (WSL). Consultez Comment installer Linux sur Windows avec WSL pour obtenir WSL et une distribution Linux par défaut installée. La distribution WSL Ubuntu 18.04 ou supérieure doit être installée et définie comme distribution par défaut avant d'utiliser AI Toolkit pour VS Code Découvrez comment modifier la distribution par défault.
- Si vous utilisez un ordinateur Linux, il doit s’agir d’une distribution Ubuntu 18.04 ou ultérieure.
- L’utilisation du modèle dans ce tutoriel nécessite des GPU NVIDIA pour le réglage précis. Il existe d'autres modèles dans le catalogue qui peuvent être chargés sur des appareils Windows à l'aide de processeurs ou d'NPUs.
Conseil
Assurez-vous également que les derniers pilotes de NVIDIA sont installés sur votre ordinateur. Si vous avez le choix entre Game Ready Driver ou Studio Driver, téléchargez Studio Driver.
Vous devez connaître le modèle de votre GPU pour télécharger les pilotes appropriés. Pour savoir de quel GPU vous disposez, consultez Comment vérifier votre GPU et pourquoi est-il important.
Configuration de l’environnement
Pour vérifier si vous avez tous les prérequis nécessaires pour exécuter des travaux de réglage précis sur votre appareil local ou machine virtuelle cloud, ouvrez la palette de commandes (Shift+Control+P) et recherchez AI Toolkit : Valider les prérequis de l’environnement.
Si votre appareil local passe les vérifications de validation, le bouton Configurer l’environnement WSL est activé pour vous permettre de sélectionner. Cela installe toutes les dépendances nécessaires pour exécuter des travaux d’ajustement.
Machine virtuelle cloud
Si votre ordinateur local n’a pas d’appareil GPU Nvidia, il est possible d’ajuster sur une machine virtuelle cloud - à la fois Windows et Linux - avec un GPU Nvidia (si vous avez un quota). Dans Azure, vous pouvez ajuster la série de machines virtuelles suivante :
- Série NCasT4_v3
- Série NC A100 v4
- Série ND A100 v4
- Série NCads H100 v5
- Série NCv3
- Série NVadsA10 v5
Conseil
VS Code vous permet de vous connecter à distance à votre machine virtuelle cloud. Si vous ne connaissez pas cette fonctionnalité, lisez le tutoriel Développement à distance sur SSH
Ajuster vos modèles
Le AI Toolkit utilise une méthode appelée QLoRA, qui combine la quantification et l'adaptation de rang faible (LoRA) pour affiner les modèles avec vos propres données. En savoir plus sur QLoRA dans QLoRA : optimisation efficace des LLM quantifiés.
Étape 1 : configurer le projet
Pour démarrer une nouvelle session de réglage précis à l’aide de QLoRA, sélectionnez l’élément réglage précis dans la section Tools dans le volet gauche de AI Toolkit.
Commencez par saisir un Nom de projet et un Emplacement de projet uniques. Un nouveau dossier portant le nom du projet spécifié est créé à l’emplacement que vous avez sélectionné pour stocker les fichiers projet.
Ensuite, sélectionnez un modèle, par exemple, Phi-3-mini-4k-instruct, dans le catalogue de modèles, puis sélectionnez Configurer le projet :
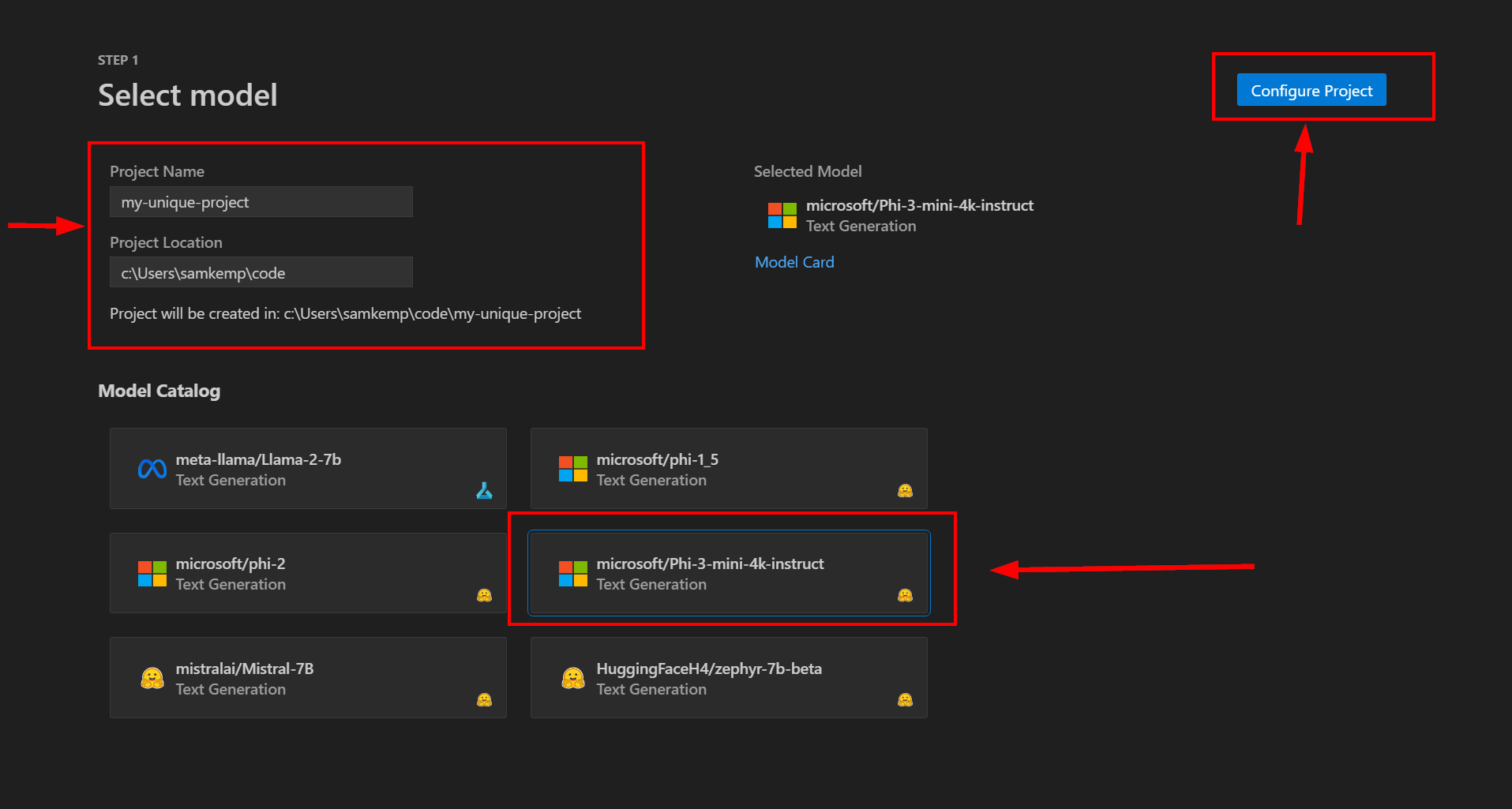
Vous serez ensuite invité à configurer vos paramètres de projet d’ajustement. Assurez-vous que la case à cocher Ajuster localement est cochée (à l’avenir, l’extension VS Code vous permettra de décharger l’ajustement sur le cloud) :
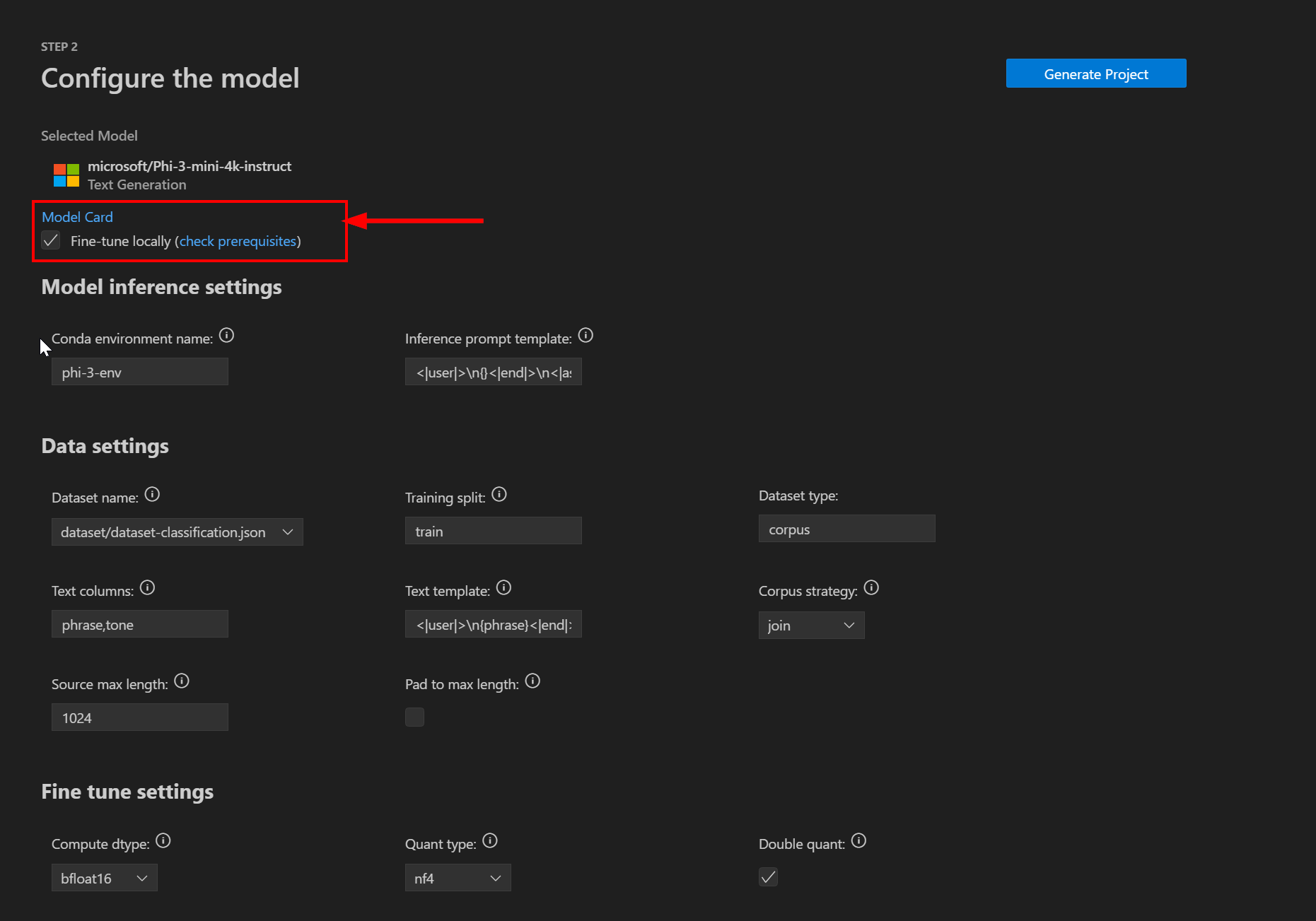
Paramètres d’inférence du modèle
Il existe deux paramètres disponibles dans la section Inférence du modèle :
| Réglage | Descriptif |
|---|---|
| Nom d’environnement Conda | Nom de l’environnement conda à activer et utiliser pour le processus d’ajustement. Ce nom doit être unique dans votre installation conda. |
| Modèle d’invite d’inférence | Modèle d’invite à utiliser au moment de l’inférence. Assurez-vous que cela correspond à la version ajustée. |
Paramètres des données
Les paramètres suivants sont disponibles dans la section Données pour configurer les informations de jeu de données :
| Réglage | Descriptif |
|---|---|
| Nom du jeu de données | Nom du jeu de données à utiliser pour ajuster le modèle. |
| Fractionnement d’entraînement | Nom de fractionnement de l’entraînement pour votre jeu de données. |
| Type de jeu de données | Le type de jeu de données à utiliser. |
| Colonnes de texte | Les noms des colonnes dans le jeu de données pour remplir l’invite d’entraînement. |
| Modèle de texte | Le modèle d’invite à utiliser pour ajuster le modèle. Cela utilise des jetons de remplacement à partir des Colonnes de texte. |
| Stratégie de corpus | Indique si vous souhaitez joindre les exemples ou les traiter ligne par ligne. |
| Longueur maximale de la source | Le nombre maximal de jetons par exemple d’apprentissage. |
| Remplissage jusqu’à la longueur maximale | Ajoutez un jeton PAD à l’exemple d’entraînement jusqu’au nombre maximal de jetons. |
Ajuster les paramètres
Les paramètres suivants sont disponibles dans la section Ajuster pour configurer davantage le processus de réglage précis :
| Paramètres | Type de données | Valeur par défaut | Descriptif |
|---|---|---|---|
| Dtype de calcul | Chaîne | bfloat16 | Le type de données pour les pondérations de modèle et les pondérations de l’adaptateur. Pour un modèle quantifié de 4 bits, il s’agit également du type de données de calcul pour les modules quantifiés. Valeurs valides : bfloat16, float16 ou float32. |
| Type de quant | Chaîne | nf4 | Le type de données de quantification à utiliser. Valeurs valides : fp4 ou nf4. |
| Quant double | Booléen | Oui | Indique s’il faut utiliser la quantification imbriquée où les constantes de quantification de la première quantification sont quantifiées de nouveau. |
| Lora r | Nombre entier | 64 | La dimension de l’attention Lora. |
| Lora alpha | Flotter | 16 | Le paramètre alpha pour la mise à l’échelle Lora. |
| Abandon de Lora | Flotter | 0.1 | La probabilité de suppression pour les couches Lora. |
| Taille d’évaluation de la base de données | Flotter | 1 024 | La taille du jeu de données de validation. |
| Graines | Nombre entier | 0 | Une valeur initiale aléatoire pour l’initialisation. |
| Valeur de données | Nombre entier | 42 | Une valeur initiale aléatoire à utiliser avec des échantillonneurs de données. |
| Par taille de lot d’apprentissage d’appareil | Nombre entier | 1 | Taille de lot par GPU pour la formation. |
| Par taille de lot d’évaluation de l’appareil | Nombre entier | 1 | Taille du lot par GPU pour l’évaluation. |
| Étapes d’accumulation de dégradé | Nombre entier | 4 | Nombre d’étapes de mise à jour pour accumuler les dégradés avant d’effectuer une passe descendante/mise à jour. |
| Activez le point de contrôle du dégradé | Booléen | Oui | Utilisez le point de contrôle du dégradé. Le est recommandé pour économiser la mémoire. |
| Taux d’apprentissage | Flotter | 0.0002 | Taux d’apprentissage initial pour AdamW. |
| Max étapes | Nombre entier | -1 | Si défini sur un nombre positif, le nombre total d’étapes d’entraînement à effectuer. Cela remplace num_train_epochs. En cas d’utilisation d’un jeu de données itérable fini, l’entraînement peut s’arrêter avant d’atteindre le nombre défini d’étapes lorsque toutes les données sont épuisées. |
Étape 2 : générer un projet
Une fois tous les paramètres définis, cliquez sur Générer un projet. Cela effectuera les actions suivantes :
- Lancez le téléchargement du modèle.
- Installez tous les prérequis et les dépendances.
- Créez un espace de travail VS Code.
Lorsque le modèle est téléchargé et que l’environnement est prêt, vous pouvez lancer le projet à partir de l’AI Toolkit en sélectionnant Fenêtre de relance dans l’espace de travail sur la page Étape 3 : Génération d’un projet. Ceci lance une nouvelle instance connectée de VS Code à votre environnement.
Remarque
Vous pouvez être invité à installer des extensions supplémentaires telles que le Flux rapide pour VS Code. Pour une expérience optimale d’ajustement, installez-les pour continuer.
Les dossiers suivants seront présents dans l’espace de travail de la fenêtre relancée :
| Nom du dossier | Descriptif |
|---|---|
| ensemble de données | Ce dossier contient le jeu de données du modèle (dataset-classification.json – un fichier de lignes JSON contenant des phrases et des tonalités). Si vous définissez votre projet pour utiliser un fichier local ou un jeu de données Hugging Face, vous pouvez ignorer ce dossier. |
| ajustement | Les fichiers de configuration Olive pour exécuter le travail d’ajustement. Olive est un outil d’optimisation de modèle prenant en charge le matériel simple d’utilisation qui compose des techniques de pointe sur la compression, l’optimisation et la compilation des modèles. Étant donné un modèle et un matériel ciblé, Olive rédige les meilleures techniques d’optimisation appropriées pour générer le(s) modèle(s) les plus efficaces pour l’inférence sur le cloud ou les dispositifs Edge, tout en prenant en compte un ensemble de contraintes telles que la précision et la latence. |
| l’inférence | Exemples de code pour l’inférence avec un modèle ajusté. |
| infra | Pour l’ajustement et l’inférence à l’aide du service Azure Container App (bientôt disponible). Ce dossier contient les fichiers Bicep et de configuration pour approvisionner le service Azure Container App. |
| installation | Fichiers utilisés pour configurer l’environnement conda. Par exemple, les exigences de pip. |
Étape 3 : exécuter un travail d’ajustement
Vous pouvez maintenant ajuster le modèle à l’aide de :
# replace {conda-env-name} with the name of the environment you set
conda activate {conda-env-name}
python finetuning/invoke_olive.py
Important
Le temps nécessaire à l’ajustement dépend du type de GPU, du nombre de GPU, du nombre d’étapes et du nombre d’époques. Cela peut prendre du temps (par exemple plusieurs heures).
Si vous souhaitez uniquement effectuer un test rapide, envisagez de réduire le nombre maximal d’étapes dans votre fichier olive-config.json. Le point de contrôle est utilisé et, par conséquent, l’exécution ajustée suivante continuera à partir du dernier point de contrôle.
Les points de contrôle et le modèle final sont enregistrés dans le dossier models de votre projet.
Étape 4 : intégrer un modèle affiné dans votre application
Ensuite, exécutez l’inférence avec le modèle ajusté par le biais de conversations dans un console, web browser ou prompt flow.
cd inference
# Console interface.
python console_chat.py
# Web browser interface allows to adjust a few parameters like max new token length, temperature and so on.
# User has to manually open the link (e.g. http://127.0.0.1:7860) in a browser after gradio initiates the connections.
python gradio_chat.py
Conseil
Les instructions sont également disponibles dans la page README.md, qui se trouve dans le dossier du projet.