Tableau de bord WinML
Le Tableau de bord WinML est un outil pour l’affichage, la modification, la conversion et la validation de modèles Machine Learning pour le moteur d’inférence Windows ML. Le moteur est intégré à Windows 10 et évalue les modèles entraînés localement sur les appareils Windows à l’aide d’optimisations matérielles pour l’UC et le GPU pour permettre des inférences à haut niveau de performances.
Vous pouvez télécharger le Tableau de bord WinML ici. Vous pouvez également créer l’application à partir de la source en suivant les instructions ci-dessous.
Lorsque vous générez l’application à partir de la source, vous avez besoin des éléments suivants :
| Spécifications | Version | Télécharger | Commande à vérifier |
|---|---|---|---|
| Python3 | 3.4 ou version ultérieure | ici | python --version |
| Yarn | latest | ici | yarn --version |
| Node.js | latest | ici | node --version |
| Git | latest | ici | git --version |
| MSBuild | latest | ici | msbuild -version |
| Nuget | latest | ici | nuget help |
Les six conditions préalables doivent être ajoutées au chemin d’accès de l’environnement. Notez que MSBuild et Nuget seront inclus dans une installation Visual Studio 2017.
Pour exécuter le Tableau de bord WinML, procédez comme suit :
- Dans la ligne de commande, clonez le dépôt :
git clone https://github.com/Microsoft/Windows-Machine-Learning - Dans le dépôt, entrez ce qui suit pour accéder au dossier approprié :
cd Tools/WinMLDashboard - Exécutez
git submodule update --init --recursivepour mettre à jour Netron. - Exécutez Yarn pour télécharger les dépendances.
- Exécutez ensuite
yarn electron-prodpour créer et démarrer l’application de bureau, ce qui lance le Tableau de bord.
Toutes les commandes disponibles du Tableau de bord peuvent être consultées dans le fichier package.json.
Le Tableau de bord utilise Netron pour afficher les modèles Machine Learning. Bien que WinML utilise le format ONNX, la visionneuse Netron prend en charge l’affichage de plusieurs formats de frameworks différents.
Un développeur a souvent besoin de mettre à jour certaines métadonnées de modèle ou de modifier les nœuds d’entrée et de sortie du modèle. Cet outil prend en charge la modification des propriétés de modèle, des métadonnées et des nœuds d’entrée/sortie d’un modèle ONNX.
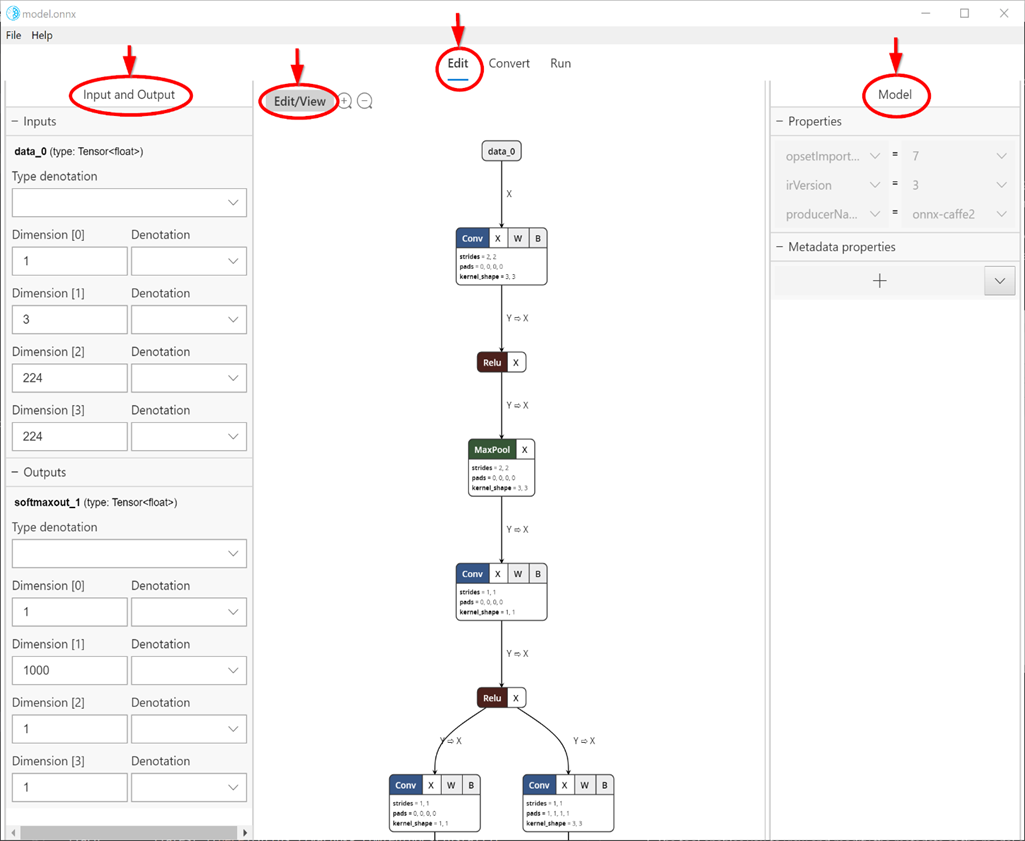
Le fait de sélectionner l’onglet Edit (en haut au centre comme indiqué dans la capture ci-dessous) vous amène à afficher et à modifier le panneau. Le volet gauche du panneau permet de modifier les nœuds d’entrée et de sortie du modèle, et le volet droit permet de modifier les propriétés du modèle. La partie centrale affiche le graphique. Pour l’instant, la prise en charge de la modification est limitée au nœud d’entrée/sortie du modèle (et non aux nœuds internes), aux propriétés de modèle et aux métadonnées du modèle.
Le bouton Edit/View passe du mode Édition au mode Affichage seul et vice-versa. Le mode Affichage seul n’autorise pas la modification et active les fonctionnalités natives de la visionneuse Netron, telles que la capacité à afficher des informations détaillées pour chaque nœud.
Aujourd’hui, il existe plusieurs frameworks différents disponibles pour l’entraînement et l’évaluation des modèles Machine Learning, ce qui complique la tâche des développeurs d’applications qui veulent intégrer des modèles dans leurs produits. Windows ML utilise le format de modèle Machine Learning ONNX qui permet la conversion d’un format de framework à un autre, et ce Tableau de bord permet de convertir facilement les modèles de différents frameworks au format ONNX.
L’onglet Convertir prend en charge la conversion au format ONNX à partir des frameworks sources suivants :
- Apple Core ML
- TensorFlow (sous-ensemble de modèles convertibles au format ONNX)
- Keras
- Scikit-learn (sous-ensemble de modèles convertibles au format ONNX)
- Xgboost
- LibSVM
L’outil permet également la validation du modèle converti en évaluant le modèle avec un moteur d’inférence Windows ML intégré utilisant des données synthétiques (par défaut) ou des données d’entrée réelles sur l’UC ou le GPU.

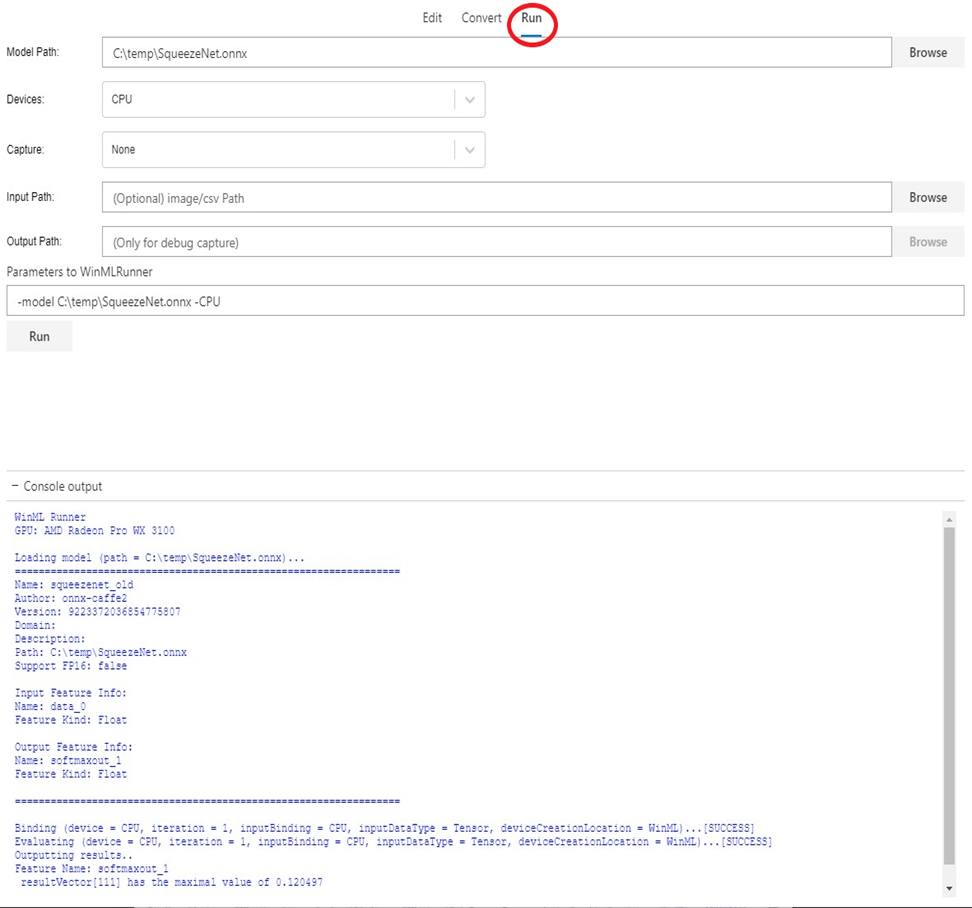
Une fois que vous disposez d’un modèle ONNX, vous pouvez vérifier si la conversion s’est correctement déroulée et que le modèle peut être évalué dans le moteur d’inférence Windows ML. Pour ce faire, utilisez l’onglet Run (voir la capture ci-dessous).
Vous pouvez choisir diverses options, telles que UC (par défaut) ou GPU, entrée réelle ou entrée synthétique (par défaut), etc. Le résultat de l’évaluation du modèle s’affiche dans la fenêtre de console en bas.
Notez que la fonctionnalité de validation de modèle est disponible uniquement sur la mise à jour d’octobre 2018 de Windows 10 ou une version plus récente de Windows 10, car l’outil s’appuie sur un moteur d’inférence Windows ML intégré.
Vous pouvez utiliser la fonctionnalité de débogage du Tableau de bord WinML pour obtenir des informations sur la façon dont les données brutes circulent via les opérateurs de votre modèle. Vous pouvez également choisir de visualiser ces données pour l’inférence de la vision par ordinateur.
Pour déboguer votre modèle, procédez comme suit :
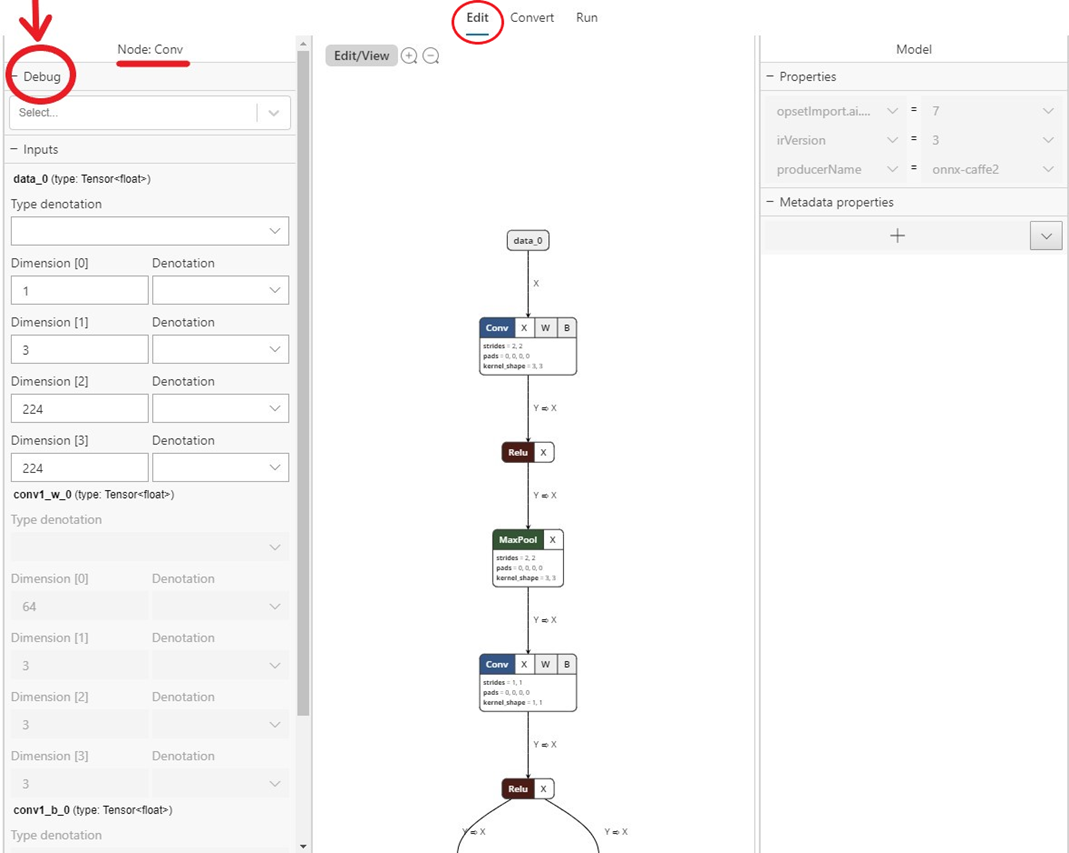
- Accédez à l’onglet
Editet sélectionnez l’opérateur pour lequel vous souhaitez capturer des données intermédiaires. Dans le volet gauche, vous trouverez un menuDebugdans lequel vous pouvez sélectionner les formats des données intermédiaires que vous souhaitez capturer. Les options disponibles sont actuellement texte et PNG. L’option Texte génère un fichier texte contenant les dimensions, le type de données et les données de tenseur brutes produites par cet opérateur. Le format PNG met en forme ces données dans un fichier image qui peut être utile pour les applications de vision par ordinateur.
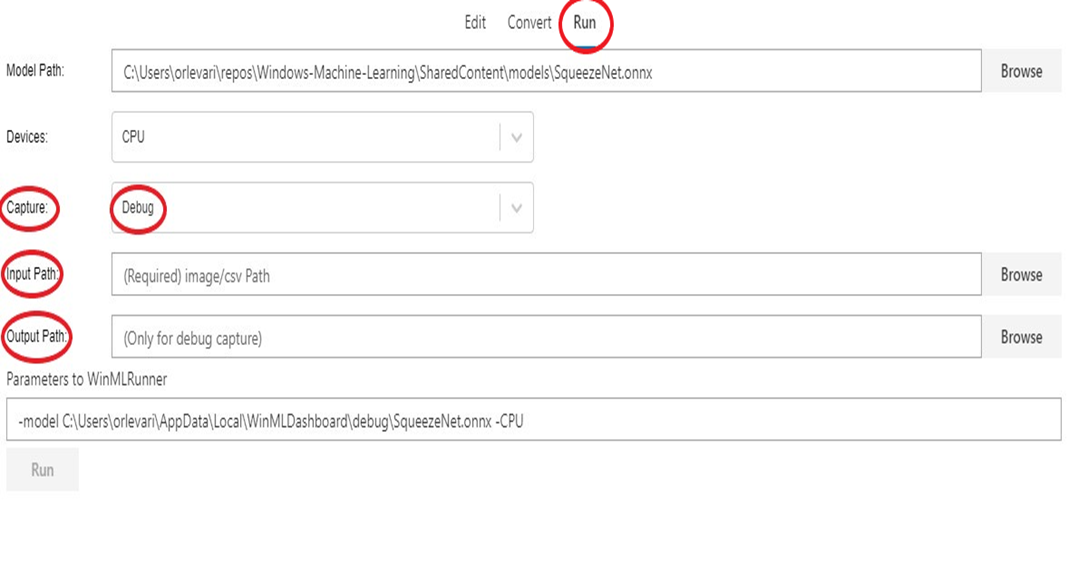
- Accédez à l’onglet
Runet sélectionnez le modèle que vous souhaitez déboguer. - Pour le champ
Capture, sélectionnezDebugdans la liste déroulante. - Sélectionnez une image ou un CSV d’entrée à fournir à votre modèle au moment de l’exécution. Notez que cela est requis lors de la capture de données de débogage.
- Sélectionnez un dossier de sortie pour exporter les données de débogage.
- Sélectionnez
Run. Une fois l’exécution terminée, vous pouvez accéder à ce dossier sélectionné pour afficher votre capture de débogage.
Vous pouvez également ouvrir le mode Débogage dans l’application Electron avec l’une des options suivantes :
- Exécutez-le avec
flag --dev-tools. - Ou sélectionnez
View -> Toggle Dev Toolsdans le menu de l’application. - Ou appuyez sur
Ctrl + Shift + I.