Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Cette rubrique décrit les trois étapes du processus d’indexation et les principaux composants impliqués dans chacune d’elles, explique le moment de l’activité d’indexation et fournit des notes pour les développeurs tiers qui souhaitent que leurs magasins de données ou formats de fichiers soient indexés.
Cette rubrique est organisée comme suit :
- Vue d'ensemble
- Étape 1 : Url de mise en file d’attente pour l’indexation
- Étape 2 : Analyse des URL
- Étape 3 : Mise à jour de l’index
- Comment l’indexation est planifiée
- Notes pour les responsables de l’implémentation
- Rubriques connexes
Vue d’ensemble
Recherche Windows prend en charge l’indexation des propriétés et du contenu à partir de fichiers de formats différents, tels que les formats .doc ou .jpeg, et les magasins de données, tels que le système de fichiers ou les boîtes aux lettres Windows Outlook. Il existe deux types d’index : les index de valeur qui permettent le filtrage et le tri en fonction de la valeur entière d’une propriété et les index inversés qui indexent les mots dans des propriétés textuelles ou du contenu. Si vous disposez d’un format de fichier ou d’un magasin de données personnalisé, vous devez comprendre comment les index recherche Windows pour que vos éléments soient correctement indexés.
Le processus d’indexation se produit en trois étapes contrôlées par un composant De recherche Windows appelé le rassembleur. Dans la première étape, le rassembleur ajoute des URL aux files d’attente. Les URL identifient les éléments à indexer, et les files d’attente ne sont que des listes d’URL prioritaires. Dans la deuxième étape, le rassembleur coordonne d’autres composants Windows Search et tiers pour accéder aux éléments et collecter des données à leur sujet. Enfin, dans la troisième étape, les données collectées sont ajoutées à l’index.
Le diagramme suivant montre les principaux composants et le flux de données via le processus d’indexation. Un certain nombre de composants sont impliqués dans la collecte des données pour l’index. Certains d’entre eux font partie de Windows Search, et d’autres proviennent d’applications tierces. Si vous disposez d’un magasin de données ou d’un format de fichier personnalisé, Recherche Windows s’appuie sur votre gestionnaire de protocole et votre filtre pour accéder aux URL et émettre des propriétés pour l’indexation. Les composants Windows Search sont affichés en bleu et les composants tiers sont affichés en vert.
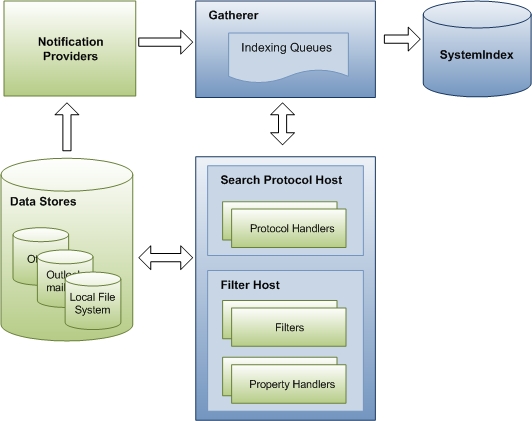
Étape 1 : Url de mise en file d’attente pour l’indexation
Dans la première étape de l’indexation, le rassembleur collecte des informations sur les mises à jour des magasins de données, compare ces informations à l’étendue d’analyse connue, puis crée une file d’attente d’URL à parcourir pour collecter des données pour l’index. Pour les sources qui ne sont pas basées sur la notification, telles que les lecteurs FAT, le rassembleur lance régulièrement une traversée complète de l’étendue d’analyse afin que les données de l’index soient conservées à jour. Pour les sources telles que NTFS, il n’y a qu’une seule analyse et tout le reste est géré par les notifications du journal des modifications USN. Il n’existe pas non plus d’analyse de Microsoft Outlook. Le diagramme suivant montre une vue générale du processus de mise en file d’attente pour l’indexation non d’analyse.
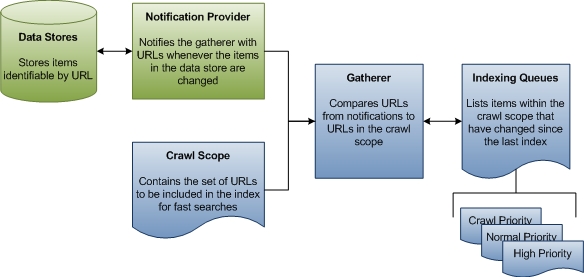
Le reste de cette section explique comment Recherche Windows détermine les URL à analyser et définit certains termes importants en cours de route.
Étendue de l’analyse L’étendue de l’analyse est un ensemble d’URL que Recherche Windows traverse pour collecter des données sur les éléments que l’utilisateur souhaite indexer pour des recherches plus rapides. Recherche Windows ajoute certaines URL à l’étendue d’analyse par défaut, comme les chemins d’accès aux dossiers Documents et Images des utilisateurs. D’autres URL peuvent être ajoutées par des applications tierces, des utilisateurs et des stratégie de groupe. Enfin, les utilisateurs et les stratégie de groupe peuvent exclure explicitement les URL. Recherche Windows prend toutes les URL ajoutées et supprime les URL exclues pour déterminer l’étendue de l’analyse. Il s’agit de l’ensemble de travail d’URL à partir duquel le rassembleur commence son travail.
Cueilleur Le rassembleur est un composant De recherche Windows qui collecte des informations sur les URL dans l’étendue de l’analyse et crée une file d’attente d’URL que l’indexeur doit analyser. Lorsqu’un élément dans l’étendue de l’analyse est ajouté, supprimé ou mis à jour, le rassembleur est averti par le fournisseur de notifications du magasin de données. Il existe une analyse initiale où le rassembleur commence à la racine de l’étendue de l’analyse. L’URL est passée au gestionnaire de protocole, puis au filtre IFilter approprié. Le filtre est généralement une énumération de répertoires qui produit plus d’URL. Les notifications sont à l’état stable. En règle générale, chaque magasin de données a son propre gestionnaire de protocole qui fournit ces notifications. Par exemple, sur le système de fichiers local, le journal des modifications USN agit en tant que fournisseur de notifications pour toutes les URL sous le protocole file://. De même, Microsoft Outlook agit en tant que fournisseur de notifications pour toutes les URL sous le protocole mapi://. Lorsqu’un utilisateur reçoit, déplace ou supprime des e-mails, Outlook avertit le rassembleur de la modification de la status de l’e-mail. À partir de ces notifications, le rassembleur crée des files d’attente d’indexation d’URL à analyser.
File d’attente d’indexation Les files d’attente d’indexation sont des listes d’URL qui identifient les éléments qui doivent être indexés ou réindexés. Le rassembleur compare les URL qu’il reçoit des fournisseurs de notifications aux URL de l’étendue d’analyse. Chaque URL des fournisseurs de notifications qui se trouve dans l’étendue de l’analyse est ajoutée à une file d’attente que le rassembleur utilise pour hiérarchiser les URL à traiter ensuite.
Il existe trois files d’attente : notifications à priorité élevée, notifications normales et analyses périodiques. La file d’attente à haute priorité concerne les notifications qui doivent être traitées immédiatement. Par exemple, lorsqu’un utilisateur modifie la propriété title d’un élément dans Windows Explorer, la vue Windows Explorer doit être mise à jour immédiatement après la modification. La file d’attente de notification normale concerne toutes les notifications de modification restantes. Les files d’attente de notification sont traitées avant la file d’attente d’analyse, car les éléments modifiés sont plus susceptibles d’intéresser un utilisateur. Le rassembleur accède aux données pour les URL de chaque file d’attente dans l’ordre FIFO (premier entré, premier sorti).
Pour plus d’informations sur la hiérarchisation et les API d’événementiel introduites dans Windows 7, consultez Indexation des événements de hiérarchisation et d’ensemble de lignes dans Windows 7. Pour plus d’informations sur la gestion de l’étendue d’analyse et les notifications, consultez Fournir des notifications de modification et Utiliser le Gestionnaire d’étendues d’analyse.
Étape 2 : Analyse des URL
Dans la deuxième étape de l’indexation, le rassembleur analyse les files d’attente, accède aux magasins de données et récupère les flux d’éléments. Tout d’abord, le rassembleur recherche le gestionnaire de protocole approprié pour chaque URL. Ensuite, le rassembleur transmet l’URL au gestionnaire de protocole. Le gestionnaire de protocole accède à l’élément et transmet les métadonnées d’élément au rassembleur. Le rassembleur utilise les métadonnées pour identifier le filtre correct.
Le diagramme suivant montre une vue générale du processus d’analyse d’URL. Cette étape comprend une coordination et une communication considérables entre les composants.
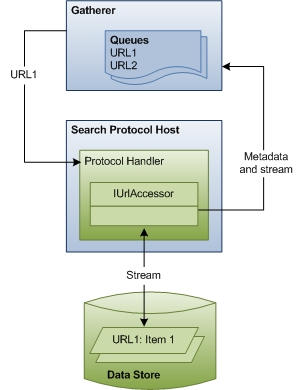
Le reste de cette section décrit comment Recherche Windows accède aux éléments pour l’indexation et explique les rôles de chacun des composants impliqués.
Cueilleur À la phase 2, l’étape d’analyse, le rassembleur traite les URL dans les files d’attente, en commençant par la file d’attente à priorité élevée. Chaque URL est examinée pour identifier son protocole. Le rassembleur recherche ensuite le gestionnaire de protocole inscrit pour ce protocole et l’instancie dans le processus hôte du protocole de recherche.
Hôte du protocole de recherche L’hôte de protocole de recherche est simplement un processus hôte boxed pour les gestionnaires de protocole. En règle générale, Recherche Windows crée deux processus hôtes de ce type, l’un qui s’exécute dans le contexte de sécurité du système et l’autre dans le contexte de sécurité de l’utilisateur. Cette séparation garantit que les données spécifiques à un utilisateur ne sont jamais exécutées dans le contexte système.
Recherche Windows utilise également le processus hôte pour isoler un instance d’un gestionnaire de protocole d’autres processus ou applications. De cette façon, aucune application externe ne peut accéder à cette instance spécifique du gestionnaire de protocole, et si le gestionnaire de protocole échoue de manière inattendue, seul le processus d’indexation est affecté. Étant donné que le processus hôte exécute du code tiers (gestionnaires de protocole), Recherche Windows recycle régulièrement le processus pour réduire le temps nécessaire à l’exploitation des informations dans le processus par une attaque réussie. Au-delà de cela, l’hôte du protocole de recherche n’affecte pas l’analyse des URL ou l’indexation des éléments.
Gestionnaires de protocole Les gestionnaires de protocole fournissent l’accès aux éléments d’un magasin de données à l’aide du protocole du magasin de données. Par exemple, le gestionnaire de protocole NTFS fournit l’accès aux fichiers sur un lecteur local à l’aide du protocole file://. Le gestionnaire de protocole sait comment parcourir le magasin de données, identifier les éléments nouveaux ou mis à jour et notifier le rassembleur. Ensuite, lorsque l’analyse commence, le gestionnaire de protocole fournit un objet IUrlAccessor au rassembleur pour qu’il se lie au flux sous-jacent de l’élément et retourne les métadonnées d’élément telles que les restrictions de sécurité et l’heure de la dernière modification.
Notes
Les gestionnaires de protocole ne sont pas des composants Windows Search ; ils sont des composants du protocole et du magasin de données spécifiques auxquels ils sont conçus pour accéder. Si vous souhaitez indexer un magasin de données personnalisé, vous devez implémenter un gestionnaire de protocole. Pour plus d’informations sur les gestionnaires de protocoles et sur la façon d’en implémenter un, consultez Développement de gestionnaires de protocoles.
Métadonnées et flux À l’aide des métadonnées retournées par l’objet IUrlAccessor du gestionnaire de protocole, le rassembleur identifie le filtre correct pour l’URL. Le rassembleur analyse l’extension de nom de fichier de l’élément et recherche le filtre inscrit pour cette extension. Si le rassembleur ne trouve pas de filtre, Recherche Windows utilise les métadonnées pour dériver un ensemble minimal d’informations de propriété système (comme System.ItemName) et met à jour l’index. Sinon, si le rassembleur trouve le filtre, la troisième étape de l’indexation commence.
Étape 3 : Mise à jour de l’index
Dans la troisième étape de l’indexation, le rassembleur instancie le filtre correct pour l’URL et initialise le filtre avec le flux de l’objet IUrlAccessor . Le filtre accède ensuite à l’élément et retourne le contenu de l’index. Si vous avez un format de fichier personnalisé, Recherche Windows s’appuie sur votre filtre pour accéder aux URL et émettre du contenu et des propriétés pour l’indexation.
Le diagramme suivant montre une vue générale du processus d’accès aux données. Cette étape comprend une coordination et une communication considérables entre les composants.
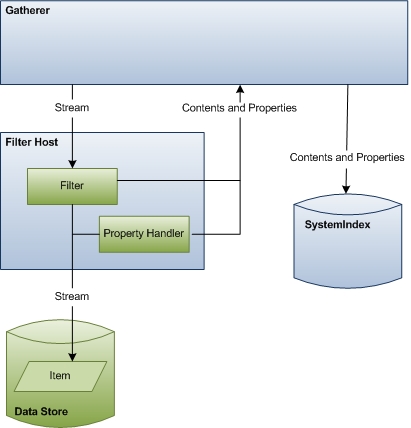
Le reste de cette section décrit comment Recherche Windows accède aux données d’élément pour l’indexation et explique les rôles de chacun des composants impliqués.
Cueilleur Au début de cette étape, le rôle du rassembleur est d’instancier le filtre approprié pour l’élément et de lui transmettre le flux d’éléments. À la fin de cette étape, le rassembleur prend le contenu et les propriétés émis par le filtre et le gestionnaire de propriétés, puis met à jour l’index.
Filtrer l’hôte L’hôte de filtre est simplement un processus hôte pour les filtres et les gestionnaires de propriétés et sert un objectif similaire à l’hôte de protocole de recherche. Le processus hôte isole les filtres et les gestionnaires de propriétés du reste du système pour les mêmes raisons de sécurité et de stabilité que les processus hôtes de protocole de recherche isolent les gestionnaires de protocole. Le processus hôte s’exécute avec des droits minimaux (il ne peut même pas accéder au système de fichiers) et est parfois recyclé pour se protéger contre les attaques de sécurité. Recherche Windows surveille également l’utilisation des ressources afin que si un filtre consomme trop de ressources, le processus hôte soit recyclé.
Filtres Les filtres sont des composants critiques dans le processus d’indexation qui émettent des informations d’élément pour le rassembleur. Les filtres sont nommés d’après l’interface principale utilisée dans leur implémentation, l’interface IFilter , et sont par conséquent parfois appelés IFilters. Il existe deux types de filtres : l’un qui interagit avec des éléments individuels tels que des fichiers et l’autre qui interagit avec des conteneurs comme des dossiers. Les deux fournissent des données pour l’index.
À l’aide des métadonnées retournées par l’objet IUrlAccessor du gestionnaire de protocole, le rassembleur identifie le filtre approprié pour une URL particulière et le transmet au flux. Le rassembleur identifie le filtre correct via un gestionnaire de protocole ou par l’extension de nom de fichier, le type MIME ou l’identificateur de classe (CLSID). Si l’URL pointe vers un conteneur, le filtre émet des propriétés pour le conteneur et énumère les éléments du conteneur (URL enfants). Si l’URL pointe vers un élément, le filtre retourne le contenu textuel, le cas échéant la lecture des propriétés et sont plus complexes que les gestionnaires de propriétés. En règle générale, nous recommandons que les filtres émettent le contenu des éléments tandis que les gestionnaires de propriétés émettent des propriétés d’élément. Toutefois, si votre filtre doit fonctionner avec des applications plus anciennes qui ne reconnaissent pas les gestionnaires de propriétés, vous pouvez également implémenter le filtre pour émettre des propriétés.
Notes
Les filtres ne sont pas des composants de Recherche Windows ; il s’agit de composants liés au format de fichier ou au conteneur spécifique auquel ils sont conçus pour accéder. Pour plus d’informations sur les filtres et sur l’implémentation d’un format de fichier ou d’un conteneur personnalisé, consultez Meilleures pratiques pour la création de gestionnaires de filtres dans Recherche Windows.
Le tableau suivant répertorie les résultats que le rassembleur reçoit d’un filtre (IFilter) et d’un gestionnaire de propriétés (IPropertyStore) pendant le processus d’indexation.
| Ifilter | Ipropertystore | |
|---|---|---|
| Autoriser l’écriture | Non | Oui |
| Mélanger le contenu et les propriétés | Oui | Non |
| Multilingue | Oui | Non |
| Émettre des liens | Oui | Non |
| MIME | Oui | Non |
| Limites de texte | Phrase, paragraphe, chapitre | None |
| Client/serveur | Les deux | Client |
| Implémentation | Complex | Simple |
Gestionnaires de propriétés Les gestionnaires de propriétés sont des composants qui lisent et écrivent des propriétés pour un format de fichier particulier. Ils accèdent aux éléments et émettent des propriétés pour le rassembleur de la même manière que les filtres pour le contenu. Les gestionnaires de propriétés sont plus faciles à implémenter que les filtres. Si un format de fichier texte est très simple ou si les fichiers sont censés être très petits, le gestionnaire de propriétés peut émettre à la fois des propriétés et du contenu.
Notes
Les gestionnaires de propriétés ne sont pas des composants Windows Search ; il s’agit de composants liés au format de fichier spécifique auquel ils sont conçus pour accéder. Pour plus d’informations sur les gestionnaires de propriétés et sur la façon d’en implémenter un pour un format de fichier personnalisé, consultez Développement de gestionnaires de propriétés pour Recherche Windows.
Propriétés Recherche Windows fournit un système de propriétés qui comprend une grande bibliothèque de propriétés. N’importe quelle propriété peut apparaître sur n’importe quel élément tel que défini par le filtre ou le gestionnaire de propriétés. Si vous avez un format de fichier personnalisé, vous pouvez mapper les propriétés de votre format de fichier à ces propriétés système, et vous pouvez créer de nouvelles propriétés personnalisées. Lorsque votre filtre ou gestionnaire de propriétés émet ces propriétés, le rassembleur met à jour l’index afin que les utilisateurs puissent effectuer une recherche à l’aide de vos propriétés. Pour plus d’informations sur la création et l’inscription de propriétés personnalisées pour un format de fichier, consultez Système de propriétés.
SystemIndex L’index, appelé SystemIndex, stocke les données indexées et se compose d’un magasin de propriétés et d’index sur les propriétés et le contenu des propriétés d’élément, et d’un index inversé pour le contenu textuel et les propriétés. Une fois que le rassembleur a mis à jour l’index, l’index peut être interrogé par Windows Search et d’autres applications. Pour plus d’informations sur les façons d’interroger l’index, consultez Interrogation de l’index par programmation.
Notes
N’oubliez pas que lorsque vous réinscrivez un schéma, les modifications apportées aux attributs des propriétés définies précédemment peuvent ne pas être respectées par l’indexeur. La solution consiste à reconstruire l’index ou à introduire de nouvelles propriétés qui reflètent les modifications au lieu de mettre à jour les anciennes (non recommandées). Pour plus d’informations, consultez Remarque aux implémenteurs dans Vue d’ensemble du système des propriétés.
Comment l’indexation est planifiée
Lorsque La recherche Windows est installée pour la première fois, elle effectue une indexation complète de l’étendue de l’analyse, en s’arrêtant pendant les périodes d’E/S élevées et d’activité utilisateur. L’étendue d’analyse par défaut se compose des emplacements de bibliothèque par défaut, tels que Documents, Musique, Images et Vidéos. Les notifications sont traitées avant même la fin de l’analyse initiale. Parfois, le rassembleur analyse les URL à partir de l’étendue d’analyse complète. Ces analyses complètes garantissent que les données de l’index sont fraîches. Par exemple, si un fournisseur de notifications ne parvient pas à envoyer des notifications ou si le service Search Windows est arrêté de manière inattendue, le rassembleur n’a aucune connaissance des éléments nouveaux ou modifiés et n’indexe pas ces éléments. Il existe deux types de sources : notification uniquement et notification activée. Dans les deux sources, le rassembleur analyse initialement l’index. Après l’analyse initiale, les sources de notification uniquement n’effectueront plus d’analyse complète, sauf en cas d’échec, comme le basculement du journal des modifications USN . Les sources activées pour la notification effectuent une analyse incrémentielle lorsque l’indexeur est démarré, mais écoutent ensuite les notifications pendant l’exécution. NTFS et Microsoft Outlook sont des notifications uniquement. Internet Explorer et FAT sont activés pour la notification.
Notes pour les responsables de l’implémentation
La qualité des données dans l’index et l’efficacité du processus d’indexation dépendent en grande partie de l’implémentation de votre gestionnaire de filtres et de propriétés. Étant donné que le filtre est appelé chaque fois qu’une URL identifie votre format de fichier, le processus d’indexation peut ralentir considérablement si votre filtre est inefficace. Si votre gestionnaire de propriétés ne mappe pas correctement toutes les propriétés de fichier aux propriétés système ou n’émet pas correctement ces propriétés, les données de l’index sont incorrectes et les recherches ultérieures de ces propriétés retournent des résultats incorrects. Si votre filtre ou gestionnaire de propriétés échoue, l’indexeur ne pourra pas indexer les données.
Les applications et processus autres que Recherche Windows s’appuient sur des gestionnaires de protocoles, des filtres et des gestionnaires de propriétés. Vos implémentations peuvent affecter ces applications de la manière dont vous ne vous attendez peut-être pas. Le Guide de développement de Recherche Windows fournit des conseils sur les choix de conception et sur le test de chacun de ces composants.
Rubriques connexes
Indexation, interrogation et notifications dans Recherche Windows
Processus d’interrogation dans Windows Search