Étape Stream Output
L’étape De sortie de flux (SO) génère en continu les données de vertex (ou flux) de l’étape active précédente vers une ou plusieurs mémoires tampons en mémoire. Les données transmises en mémoire peuvent être retransmis dans le pipeline en tant que données d’entrée ou lecture à partir de l’UC.
Objectif et utilisations
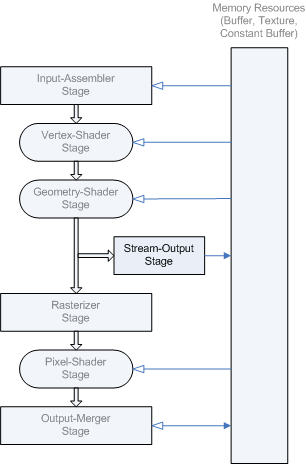
L’étape de sortie de flux diffuse les données primitives du pipeline vers la mémoire sur son chemin vers le rastériseur. Les données de l’étape précédente peuvent être diffusées en continu vers la mémoire et/ou passées dans le rastériseur. Les données transmises en mémoire peuvent être retransmis dans le pipeline en tant que données d’entrée ou lecture à partir de l’UC.
Les données diffusées en mémoire peuvent être lues dans le pipeline dans une passe de rendu ultérieure, ou être copiées dans une ressource intermédiaire (afin qu’elles puissent être lues par le processeur). La quantité de données diffusées en continu peut varier ; Direct3D est conçu pour gérer les données sans avoir à interroger (le GPU) sur la quantité de données écrites.-->
Il existe deux façons de nourrir les données de sortie de flux dans le pipeline :
- Les données de sortie de flux peuvent être renvoyées à l’étape d’assembleur d’entrée (IA).
- Les données de sortie de flux peuvent être lues par des nuanceurs programmables à l’aide de fonctions de chargement .
Entrée
Données de vertex d’une étape de nuanceur précédente.
Sortie
L’étape De sortie de flux (SO) génère en continu (ou flux) des données de vertex de l’étape active précédente, telles que l’étape du nuanceur geometry (GS), vers une ou plusieurs mémoires tampons en mémoire. Si l’étape Du nuanceur de géométrie (GS) est inactive, l’étape De sortie de flux (SO) génère en continu des données de vertex de l’étape De nuanceur de domaine (DS) vers des mémoires tampons en mémoire (ou si DS est également inactif, à partir de l’étape du nuanceur de vertex (VS).
Lorsqu’un triangle ou une bande de traits est lié à l’étape d’assembleur d’entrée (IA), chaque bande est convertie en liste avant qu’elles ne soient diffusées en continu. Les sommets sont toujours écrits sous forme de primitives complètes (par exemple, 3 sommets à la fois pour les triangles) ; les primitives incomplètes ne sont jamais diffusées en continu. Les types primitifs avec adjacency ignorent les données d’adjacency avant la sortie des données de diffusion en continu.
L’étape de sortie de flux prend en charge jusqu’à 4 mémoires tampons simultanément.
- Si vous diffusez des données en continu dans plusieurs mémoires tampons, chaque mémoire tampon ne peut capturer qu’un seul élément (jusqu’à 4 composants) de données par vertex, avec un pas de données implicite égal à la largeur de l’élément dans chaque mémoire tampon (compatible avec la façon dont les mémoires tampons d’élément unique peuvent être liées pour l’entrée dans les étapes du nuanceur). En outre, si les mémoires tampons ont des tailles différentes, l’écriture s’arrête dès que l’une des mémoires tampons est pleine.
- Si vous diffusez des données dans une mémoire tampon unique, la mémoire tampon peut capturer jusqu’à 64 composants scalaires de données par vertex (256 octets ou moins) ou le pas de vertex peut atteindre 2 048 octets.
Rubriques connexes