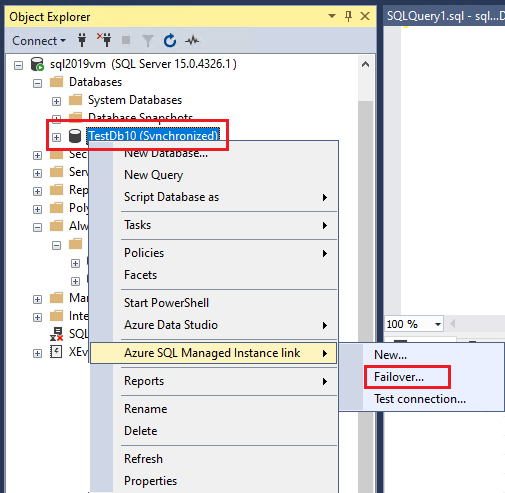
Para conmutar por error, primero debe cambiar los modos de replicación de la instancia de SQL Server mediante Transact-SQL (T-SQL).
Después, puede conmutar por error y cambiar roles mediante PowerShell.
Cambio del modo de replicación (de Conmutación por error a SQL MI)
La replicación entre SQL Server y SQL Managed Instance es asincrónica de manera predeterminada. Si realiza la conmutación por error de SQL Server a Azure SQL Managed Instance, antes de conmutar por error la base de datos, cambie el vínculo al modo sincrónico en SQL Server mediante Transact-SQL (T-SQL).
Nota
- Omita este paso si realiza la conmutación por error desde SQL Managed Instance a SQL Server 2022.
- La replicación sincrónica a través de grandes distancias de red puede ralentizar las transacciones en la réplica principal.
Ejecute el siguiente script de T-SQL en SQL Server para cambiar el modo de replicación del grupo de disponibilidad distribuido de async a sync. Reemplace:
<DAGName> por el nombre del grupo de disponibilidad distribuido (que se ha usado para crear el vínculo).<AGName> por el nombre del grupo de disponibilidad creado en SQL Server (que se ha usado para crear el vínculo).<ManagedInstanceName> por el nombre de la instancia administrada.
USE master
GO
ALTER AVAILABILITY GROUP [<DAGName>]
MODIFY
AVAILABILITY GROUP ON
'<AGName>' WITH
(AVAILABILITY_MODE = SYNCHRONOUS_COMMIT),
'<ManagedInstanceName>' WITH
(AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);
Para confirmar que ha cambiado correctamente el modo de replicación del vínculo, use la siguiente vista de administración dinámica. Los resultados indican el estado SYNCHRONOUS_COMMIT.
SELECT
ag.name, ag.is_distributed, ar.replica_server_name,
ar.availability_mode_desc, ars.connected_state_desc, ars.role_desc,
ars.operational_state_desc, ars.synchronization_health_desc
FROM
sys.availability_groups ag
join sys.availability_replicas ar
on ag.group_id=ar.group_id
left join sys.dm_hadr_availability_replica_states ars
on ars.replica_id=ar.replica_id
WHERE
ag.is_distributed=1
Ahora que ha cambiado SQL Server al modo de confirmación sincrónica, la replicación entre las dos instancias es sincrónica. Si necesita invertir este estado, siga los mismos pasos y establezca AVAILABILITY_MODE en ASYNCHRONOUS_COMMIT.
Comprobación de los valores LSN en SQL Server y SQL Managed Instance
Para completar la conmutación por error o la migración, confirme que la replicación a la instancia secundaria ha finalizado. Para ello, debe asegurarse de que los LSN (números de secuencia de registro) en las entradas de registro para SQL Server y SQL Managed Instance sean iguales.
Inicialmente, se espera que el LSN en la base de datos principal sea mayor que el LSN en la base de datos secundaria. La latencia de red puede provocar que la replicación se retrase un poco detrás de la principal. Dado que la carga de trabajo se ha detenido en la principal, pasado un tiempo los LSN coincidirán y dejarán de cambiar.
Use la siguiente consulta T-SQL en SQL Server para leer el número de secuencia de registro del último registro de transacciones registrado. Sustituya:
<DatabaseName> por el nombre de la base de datos, y busque el último número de secuencia de registro de seguridad (LSN) protegido.
SELECT
ag.name AS [Replication group],
db.name AS [Database name],
drs.database_id AS [Database ID],
drs.group_id,
drs.replica_id,
drs.synchronization_state_desc AS [Sync state],
drs.end_of_log_lsn AS [End of log LSN],
drs.last_hardened_lsn AS [Last hardened LSN]
FROM
sys.dm_hadr_database_replica_states drs
inner join sys.databases db on db.database_id = drs.database_id
inner join sys.availability_groups ag on drs.group_id = ag.group_id
WHERE
ag.is_distributed = 1 and db.name = '<DatabaseName>'
Use la siguiente consulta T-SQL en SQL Managed Instance para leer el último número de secuencia de registro de la base de datos. Reemplace <DatabaseName> por el nombre de su base de datos.
Esta consulta funciona en una SQL Managed Instance de uso general. Para una SQL Managed Instance crítica para la empresa, quite la marca de comentario and drs.is_primary_replica = 1 al final del script. En el nivel de servicio Crítico para la empresa, este filtro garantiza que los detalles solo se lean de la réplica principal.
SELECT
db.name AS [Database name],
drs.database_id AS [Database ID],
drs.group_id,
drs.replica_id,
drs.synchronization_state_desc AS [Sync state],
drs.end_of_log_lsn AS [End of log LSN],
drs.last_hardened_lsn AS [Last hardened LSN]
FROM
sys.dm_hadr_database_replica_states drs
inner join sys.databases db on db.database_id = drs.database_id
WHERE
db.name = '<DatabaseName>'
Como alternativa, también podría utilizar el comando Get-AzSqlInstanceLink de PowerShell o az sql mi link show de la CLI de Azure para obtener la propiedad LastHardenedLsn de su enlace en SQL Managed Instance para proporcionar la misma información que la consulta T-SQL anterior.
Importante
Verifique una vez más que su carga de trabajo está detenida en la principal. Compruebe que los LSN de SQL Server y SQL Managed Instance coinciden, y que permanecen coincidentes y sin cambios durante algún tiempo. Los LSN estables en ambas instancias indican que el registro final se ha replicado en la secundaria y que la carga de trabajo se ha detenido correctamente.
Conmutación por error de una base de datos
Si quiere usar PowerShell para conmutar por error una base de datos entre SQL Server 2022 y SQL Managed Instance mientras mantiene el vínculo, o para realizar una conmutación por error con pérdida de datos para cualquier versión de SQL Server, use el asistente para la conmutación por error entre SQL Server e Instancia administrada en SSMS a fin de generar el script para su entorno. Puede realizar una conmutación por error planeada desde la réplica principal o secundaria. Para realizar una conmutación por error forzada, conéctese a la réplica secundaria.
Para interrumpir el vínculo y detener la replicación al conmutar por error o migrar la base de datos independientemente de la versión de SQL Server, use el comando Remove-AzSqlInstanceLink de PowerShell o az sql mi link delete de la CLI de Azure.
Advertencia
- Antes de realizar la conmutación por error, detenga la carga de trabajo en la base de datos de origen para permitir que la base de datos replicada se ponga completamente al día y realice la conmutación por error sin pérdida de datos. Si realiza una conmutación por error forzada o si interrumpe el vínculo antes de que coincidan los LSN, podría perder datos.
- La conmutación por error de una base de datos en SQL Server 2019 y versiones anteriores interrumpe y quita el vínculo entre las dos réplicas. No se puede conmutar por recuperación a la principal inicial.
El siguiente script de ejemplo interrumpe el vínculo y finaliza la replicación entre las réplicas, lo que hace que la base de datos lea y escriba en ambas instancias. Sustituya:
<ManagedInstanceName> por el nombre de la instancia administrada.<DAGName> por el nombre del vínculo con el que se realiza la conmutación por error (salida de la propiedad Name del comando Get-AzSqlInstanceLink ejecutado anteriormente).
$ManagedInstanceName = "<ManagedInstanceName>"
$LinkName = "<DAGName>"
$ResourceGroup = (Get-AzSqlInstance -InstanceName $ManagedInstanceName).ResourceGroupName
Remove-AzSqlInstanceLink -ResourceGroupName $ResourceGroup |
-InstanceName $ManagedInstanceName -Name $LinkName -Force
Cuando el proceso de conmutación por error funciona, el vínculo se anula y deja de existir. Tanto la base de datos de SQL Server como la base de datos de SQL Managed Instance pueden ejecutar cargas de trabajo de lectura y escritura porque ahora son completamente independientes.
Importante
Tras una conmutación por error exitosa a SQL Managed Instance, vuelva a apuntar manualmente la cadena de conexión de su(s) aplicación(es) al FQDN de SQL Managed Instance para completar el proceso de migración o conmutación por error y continuar su ejecución en Azure.
Después de quitar el vínculo, puede mantener el grupo de disponibilidad en SQL Server, pero debe quitar el grupo de disponibilidad distribuido para quitar los metadatos de vínculo de SQL Server. Este paso adicional solo es necesario cuando se realiza la conmutación por error mediante PowerShell, ya que SSMS realiza esta acción automáticamente.
Para anular el grupo de disponibilidad distribuido, reemplace el siguiente valor y, después, ejecute el código T-SQL de ejemplo:
<DAGName> por el nombre del grupo de disponibilidad distribuido en SQL Server (que se ha usado para crear el vínculo).
USE MASTER
GO
DROP AVAILABILITY GROUP <DAGName>
GO