Nota
O acceso a esta páxina require autorización. Pode tentar iniciar sesión ou modificar os directorios.
O acceso a esta páxina require autorización. Pode tentar modificar os directorios.
En este artículo se explica la opción de nivel de compatibilidad de Azure Stream Analytics.
Stream Analytics es un servicio administrado con actualizaciones de características regulares y constantes mejoras de rendimiento. La mayoría de las actualizaciones del entorno de ejecución del servicio se ponen a disposición de los usuarios finales automáticamente, con independencia del nivel de compatibilidad. Sin embargo, cuando una nueva funcionalidad introduce un cambio en el comportamiento de los trabajos existentes o un cambio en la forma en que se consumen los datos en los trabajos en ejecución, el cambio se incluye en un nuevo nivel de compatibilidad. Puede mantener los trabajos de Stream Analytics existentes en ejecución sin cambios importantes si rebaja la opción de nivel de compatibilidad. Cuando esté listo para los comportamientos de runtime más recientes, puede aumentar el nivel de compatibilidad.
Elegir un nivel de compatibilidad
Los niveles de compatibilidad controlan el comportamiento en tiempo de ejecución de un trabajo de Stream Analytics.
Actualmente, Azure Stream Analytics admite tres niveles de compatibilidad:
- 1.2: comportamiento más nuevo con las mejoras más recientes
- 1.1: comportamiento anterior
- 1.0: el nivel de compatibilidad original, se incorporó durante la disponibilidad general de Azure Stream Analytics hace varios años.
Al crear un nuevo trabajo de Stream Analytics, se recomienda hacerlo con el nivel de compatibilidad más reciente. Inicie el diseño del trabajo basándose en los comportamientos más recientes a fin de evitar la incorporación de cambio y complejidad más adelante.
Definición del nivel de compatibilidad
Puede establecer el nivel de compatibilidad de un trabajo de Stream Analytics desde Azure Portal o con la llamada a la API de REST del trabajo Create.
Para actualizar el nivel de compatibilidad del trabajo en Azure Portal:
- Usa el portal de Azure para ubicar tu trabajo de Stream Analytics.
- Detenga el trabajo antes de actualizar el nivel de compatibilidad. No se puede actualizar el nivel de compatibilidad si el trabajo está en un estado de ejecución.
- En el encabezado Configurar, seleccione Nivel de compatibilidad.
- Seleccione el valor de nivel de compatibilidad que quiera.
- Seleccione Guardar en la parte inferior de la página.
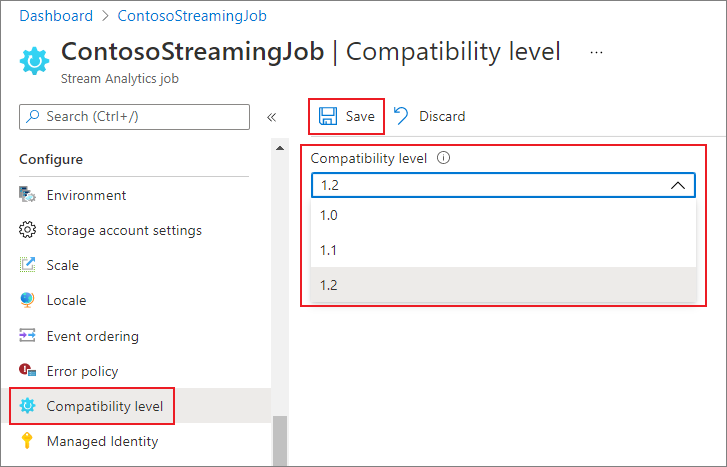
Cuando se actualiza el nivel de compatibilidad, el compilador de T valida el trabajo con la sintaxis que se corresponde con el nivel de compatibilidad seleccionado.
Nivel de compatibilidad 1.2
En el nivel de compatibilidad 1.2 se han incorporado los siguientes cambios de importancia:
Protocolo de mensajería de AMQP
Nivel 1.2: Azure Stream Analytics usa el protocolo de mensajería Advanced Message Queueing Protocol (AMQP) para escribir en colas y temas de Service Bus. AMQP le permite construir aplicaciones híbridas, entre plataformas, utilizando un protocolo estándar abierto.
Funciones geoespaciales
Niveles anteriores: Azure Stream Analytics usaba cálculos geográficos.
Nivel 1.2: Azure Stream Analytics permite calcular coordenadas geográficas proyectadas geométricas. No hay ningún cambio en la firma de las funciones geoespaciales, aunque su semántica es ligeramente diferente, lo que permite un cálculo más preciso que antes.
Azure Stream Analytics admite la indexación de datos de referencia geoespaciales. Los datos de referencia que contienen elementos geoespaciales se pueden indexar para un cálculo de combinación más rápido.
Las funciones geoespaciales actualizadas aportan toda la expresividad del formato geoespacial Well Known Text (WKT). Puede especificar otros componentes geoespaciales que anteriormente no eran compatibles con GeoJson.
Para obtener más información, vea Updates to geospatial features in Azure Stream Analytics – Cloud and IoT Edge (Actualizaciones de características geoespaciales en Azure Stream Analytics: nube e IoT Edge).
Ejecución de consultas en paralelo para los orígenes de entrada con varias particiones
Niveles anteriores: las consultas de Azure Stream Analytics requerían el uso de la cláusula PARTITION BY para ejecutar en paralelo el procesamiento de consultas entre particiones de origen de entrada.
Nivel 1.2: si la lógica de consulta se puede ejecutar en paralelo entre particiones de origen de entrada, Azure Stream Analytics crea instancias de consulta independientes y ejecuta los cálculos en paralelo.
Integración nativa de la API Bulk con la salida de Azure Cosmos DB
Niveles anteriores: el comportamiento de upsert era insertar o combinar.
Nivel 1.2: la integración nativa de API Bulk con la escritura de datos de Azure Cosmos DB maximiza el rendimiento y controla con eficacia las solicitudes de limitación. Para obtener más información, vea la página sobre la salida de Azure Stream Analytics a Azure Cosmos DB.
El comportamiento de upsert es insertar o reemplazar.
DateTimeOffset al escribir en la salida de SQL
Niveles anteriores: los tipos DateTimeOffset se ajustaron al formato UTC.
Nivel 1.2: DateTimeOffset ya no se ajustará.
Largo al escribir en la salida de SQL
Niveles anteriores: los valores se truncaron en función del tipo de destino.
Nivel 1.2: los valores que no encajan en el tipo de destino se controlan conforme a la directiva de error de salida.
Serialización de registros y matrices al escribir en la salida de SQL
Niveles anteriores: Los registros se escribieron como "Record" y las matrices se escribieron como "Array".
Nivel 1.2: Los registros y matrices se serializan en formato JSON.
Validación estricta de prefijo de funciones
Niveles anteriores: no había validación estricta de prefijos de función.
Nivel 1.2: Azure Stream Analytics tiene una validación estricta de prefijos de función. La adición de un prefijo a una función integrada produce un error. Por ejemplo, myprefix.ABS(…) no es compatible.
La adición de un prefijo a agregados integrados también produce un error. Por ejemplo, myprefix.SUM(…) no es compatible.
El empleo del prefijo "system" para cualquier función definida por el usuario produce un error.
No se permiten Matriz ni Objeto como propiedades de clave en el adaptador de salida de Azure Cosmos DB
Niveles anteriores: los tipos Array y Object se admitían como una propiedad de clave.
Nivel 1.2: los tipos Array y Object ya no se admiten como una propiedad de clave.
Deserialización del tipo booleano en JSON, AVRO y PARQUET
Niveles anteriores: Azure Stream Analytics deserializa el valor booleano en el tipo BIGINT: false se asigna a 0 y true se asigna a 1. La salida solo crea valores booleanos en JSON, AVRO y PARQUET si convierte explícitamente eventos en BIT.
Por ejemplo, una consulta de paso a través como la lectura de SELECT value INTO output1 FROM input1 de un JSON { "value": true } de input1 escribirá en output1 un valor JSON { "value": 1 }.
Nivel 1.2: Azure Stream Analytics deserializa el valor booleano en el tipo BIT. False se asigna a 0 y true se asigna a 1. Una consulta de paso como SELECT value INTO output1 FROM input1 que lee un JSON { "value": true } desde input1 escribirá en output1 un valor JSON { "value": true }. Puede convertir el valor al tipo BIT en la consulta para asegurarse de que aparezcan como true y false en la salida para los formatos que admiten el tipo booleano.
Nivel de compatibilidad 1.1
En el nivel de compatibilidad 1.1 se introdujeron los siguientes cambios principales:
Formato XML de Service Bus
Nivel 1.0: Azure Stream Analytics usaba DataContractSerializer, por lo que el contenido del mensaje incluía etiquetas XML. Por ejemplo:
@\u0006string\b3http://schemas.microsoft.com/2003/10/Serialization/\u0001{ "SensorId":"1", "Temperature":64\}\u0001
Nivel 1.1: El contenido del mensaje contiene directamente la secuencia sin ninguna etiqueta adicional. Por ejemplo: { "SensorId":"1", "Temperature":64}
Sensibilidad a mayúsculas y minúsculas persistente para los nombres de campo
Nivel 1.0: Los nombres de campo se cambiaban a minúsculas cuando los procesaba el motor de Azure Stream Analytics.
Nivel 1.1: la distinción entre mayúsculas y minúsculas se mantiene para nombres de campo que procesa el motor de Azure Stream Analytics.
Nota
La distinción entre mayúsculas y minúsculas persistente aún no está disponible para trabajos de Stream Analytics hospedados mediante un entorno de Edge. En consecuencia, todos los nombres de campo se convierten a minúsculas si el trabajo se hospeda en Edge.
FloatNaNDeserializationDisabled
Nivel 1.0: el comando CREATE TABLE no filtró los eventos con NaN (Not-a-Number. Por ejemplo, Infinity, -Infinity) en un tipo de columna FLOAT porque están fuera del intervalo documentado para estos números.
Nivel 1.1: El comando CREATE TABLE le permite especificar un esquema seguro. El motor de Stream Analytics valida que los datos se ajustan a este esquema. Con este modelo, el comando puede filtrar eventos con valores NaN.
Deshabilitación de la conversión automática de cadenas de fecha y hora a un tipo DateTime en la entrada de JSON
Nivel 1.0: El analizador JSON convertirá automáticamente los valores de cadena con información de fecha, hora y zona al tipo DATETIME en la entrada, de modo que el valor pierde inmediatamente su formato original y la información de zona horaria. Como esto se hace en la entrada, incluso si ese campo no se utilizó en la consulta, se convierte en fecha y hora en UTC.
Nivel 1.1: Ya no existe la conversión automática de valores de cadena con información de fecha, hora y zona al tipo DATETIME. Como resultado, se conserva la información de zona horaria y el formato original. Sin embargo, si se usa el campo NVARCHAR (MAX) en la consulta como parte de una expresión DATETIME (por ejemplo, la función DATEADD), se convierte al tipo DATETIME para realizar el cálculo y se pierde su formato original.