Nota
O acceso a esta páxina require autorización. Pode tentar iniciar sesión ou modificar os directorios.
O acceso a esta páxina require autorización. Pode tentar modificar os directorios.
Power Automate A minería de procesos ofréceche a opción de almacenar e ler os datos do rexistro de eventos directamente desde *Gen2* Azure Data Lake Storage . Esta funcionalidade simplifica a xestión de extracción, transformación e carga (ETL) conectándose directamente á túa conta de almacenamento.
Esta funcionalidade admite actualmente a inxestión do seguinte:
Táboas
-
Táboas Delta
- Mesa Delta individual en fabric Lakehouse.
Ficheiros e cartafoles
-
CSV
- Ficheiro único CSV.
- Cartafol con varios ficheiros CSV que teñen a mesma estrutura. Inxírense todos os ficheiros.
-
Parquet
- Parquet dunha soa ficha.
- Cartafol con varios arquivos de parqué que teñen a mesma estrutura. Inxírense todos os ficheiros.
-
Parquet Delta
- Cartafol que contén unha estrutura delta-parquet .
Requisitos previos
A conta de almacenamento de Data Lake debe ser de segunda xeración. Podes comprobalo desde o portal de Azure. As contas de almacenamento de Azure Data Lake Gen1 non son compatibles.
A conta de almacenamento de Data Lake debe ter o espazo de nomes xerárquico activado.
O rol de *Propietario* (a nivel de conta de almacenamento) debe atribuírse ao usuario que realiza a configuración inicial do contedor para o ambiente para os seguintes usuarios no mesmo ambiente. Estes usuarios conéctanse ao mesmo contedor e deben ter estas asignacións:
- Rol de lector de datos de blobs de almacenamento ou colaborador de datos de blobs de almacenamento asignado
- Rol de lector de Azure Resource Manager asignado, como mínimo.
Deberíase establecer unha regra de compartición de recursos (CORS) para a túa conta de almacenamento para compartila con Power Automate Process Mining.
As orixes permitidas deben definirse en
https://make.powerautomate.comehttps://make.powerapps.com.Os métodos permitidos deben incluír:
get,options,put,post.As cabeceiras permitidas deberían ser o máis flexibles posible. Recomendámos definilos como
*.As cabeceiras expostas deben ser o máis flexibles posible. Recomendámos definilos como
*.A idade máxima debería ser o máis flexible posible. Recomendamos usar
86400.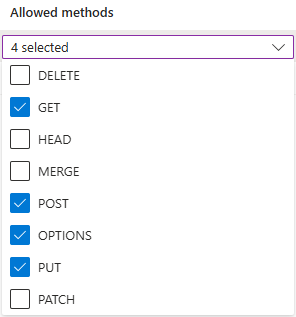
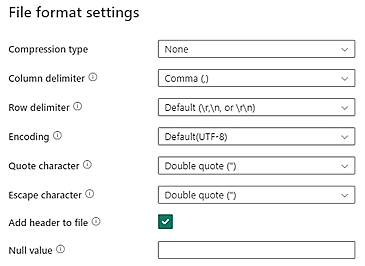
Os datos CSV no teu almacenamento de Data Lake deben cumprir os seguintes requisitos de formato de ficheiro CSV:
- Tipo de compresión: Ningunha
- Delimitador de columna: Coma (,)
- Delimitador de filas: Valor predeterminado e codificación. Por exemplo, Predeterminado (\r,\n ou \r\n)
Todos os datos deben estar no formato de rexistro de eventos final e cumprir os requisitos enumerados en Requisitos de datos. Os datos deberían estar listos para mapearse ao esquema de minería de procesos. Non hai ningunha transformación de datos dispoñible despois da inxestión.
O tamaño (ancho) da fila de cabeceira está limitado actualmente a 1 MB.
Importante
Asegúrate de que a marca de tempo representada no teu ficheiro CSV siga o formato estándar ISO 8601 (por exemplo, YYYY-MM-DD HH:MM:SS.sss ou YYYY-MM-DDTHH:MM:SS.sss).
Conectarse a Azure Data Lake Storage
No panel de navegación da esquerda, selecciona Minería de procesos>Comezar aquí.
No campo Nome do proceso , introduza un nome para o seu proceso.
Na cabeceira Fonte de datos , selecciona Importar datos>Azure Data Lake>Continuar.

Na pantalla Configuración da conexión , selecciona o teu ID da subscrición, Grupo de recursos, Conta de almacenamento e Contedor nos menús despregables.
Seleccione o ficheiro ou cartafol que contén os datos do rexistro de eventos.
Podes seleccionar un único ficheiro ou unha carpeta con varios ficheiros. Todos os ficheiros deben ter as mesmas cabeceiras e o mesmo formato.
Seleccione Seguinte.
Na pantalla Mapear os datos , mapee os seus datos ao esquema requirido.
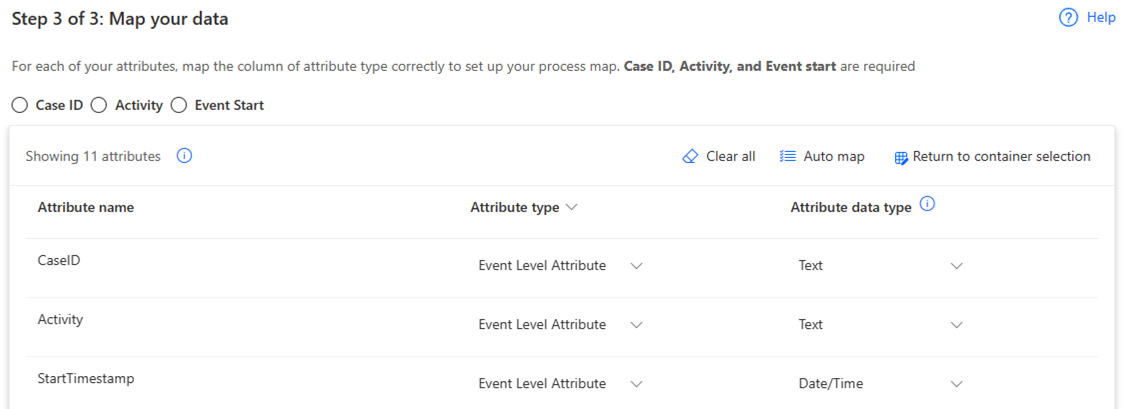
Completa a conexión seleccionando Gardar e analizar.
Definir a configuración de actualización incremental de datos
Pode actualizar un proceso inxerido desde Azure Data Lake segundo unha programación, xa sexa mediante unha actualización completa ou incremental. Aínda que non existen políticas de retención, podes inxerir datos de forma incremental usando un dos seguintes métodos:
Se seleccionaches un único ficheiro na sección anterior, engade máis datos ao ficheiro seleccionado.
Se seleccionaches un cartafol na sección anterior, engade ficheiros incrementais ao cartafol seleccionado.
Importante
Ao engadir ficheiros incrementais a un cartafol ou subcartafol seleccionado, asegúrese de indicar a orde de incremento nomeando os ficheiros con datas como AAAMMDD.csv ou AAAAMMDDHHMMSS.csv.
Para actualizar un proceso:
Vaia á páxina de Detalles do proceso.
Selecciona Actualizar configuración.
Na pantalla Programar actualización , siga estes pasos:
- Activa o interruptor Manter os datos actualizados .
- Nas listas despregables Actualizar datos cada , seleccione a frecuencia da actualización.
- Nos campos Comezar en , seleccione a data e a hora da actualización.
- Activa o interruptor de Actualización incremental .