Modos de modelo semántico en el servicio Power BI
En este artículo se proporciona una explicación técnica de los modos de modelo semántico de Power BI. Se aplica a los modelos semánticos que representan una conexión dinámica a un modelo de Analysis Services hospedado externamente y también a los modelos desarrollados en Power BI Desktop. En el artículo se resaltan las razones de cada modo y los impactos posibles en los recursos de capacidad de Power BI.
Los tres modos de modelo semántico son:
Modo de importación
Modo de importación es el modo más común que se usa para desarrollar modelos semánticos. Este modo ofrece un rendimiento rápido gracias a las consultas en memoria. También ofrece flexibilidad de diseño a los modeladores y admite características específicas del servicio Power BI (Preguntas y respuestas, Conclusiones rápidas, etc.). Debido a estos puntos fuertes, es el modo predeterminado en el momento de crear una nueva solución de Power BI Desktop.
Es importante comprender que los datos importados siempre se almacenan en el disco. Cuando se consultan o se actualizan, los datos se deben cargar por completo en la memoria de la capacidad de Power BI. Una vez en la memoria, los modelos de importación pueden obtener resultados de consulta muy rápidos. También es importante entender que no hay ningún concepto de un modelo de importación que se cargue parcialmente en la memoria.
Cuando se actualizan, los datos se comprimen y optimizan y luego se almacenan en el disco mediante el motor de almacenamiento de VertiPaq. Cuando se cargan desde el disco en la memoria, es posible ver una compresión 10 veces superior. Por lo tanto, es razonable esperar que 10 GB de datos de origen se puedan comprimir a aproximadamente 1 GB de tamaño. El tamaño de almacenamiento en disco puede lograr una reducción del 20 % del tamaño comprimido. La diferencia de tamaño se puede determinar al comparar el tamaño de archivo de Power BI Desktop con el uso de memoria del administrador de tareas del archivo.
La flexibilidad de diseño se puede lograr de tres maneras:
- Integrar los datos mediante el almacenamiento en caché de los datos de flujos de datos y orígenes de datos externos, sea cual sea el formato o el tipo del origen de datos.
- Use todo el conjunto de funciones del lenguaje de fórmulas M de Power Query, conocido como M al crear consultas de preparación de datos.
- Aplique todo el conjunto de funciones de expresiones de análisis de datos (DAX) al mejorar el modelo con la lógica de negocios. Hay compatibilidad con las columnas calculadas, las tablas calculadas y las medidas.
Como se muestra en la imagen siguiente, un modelo de importación puede integrar datos de diversos tipos de orígenes de datos compatibles.
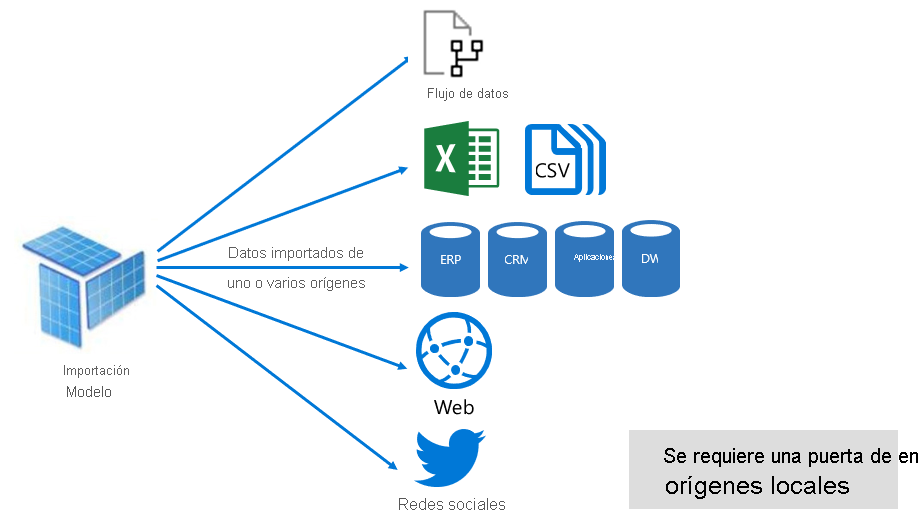
Sin embargo, aunque hay ventajas interesantes asociadas con los modelos de importación, también hay desventajas:
- Es necesario cargar todo el modelo en la memoria antes de que Power BI pueda consultar el modelo, lo que puede poner presión en los recursos de capacidad disponibles, especialmente a medida que aumentan el número y el tamaño de los modelos de importación.
- Los datos del modelo solo son tan actuales como la actualización más reciente, por lo que es necesario actualizar los modelos de importación, normalmente de manera programada.
- Una actualización completa quita todos los datos de todas las tablas y los vuelve a cargar desde el origen de datos. Esta operación puede ser costosa en cuanto a tiempo y recursos para el servicio Power BI y los orígenes de datos.
Nota
Power BI puede lograr una actualización incremental para evitar tener que truncar y recargar tablas enteras. Para obtener más información, incluidos los planes admitidos y las licencias, consulte Actualización incremental y datos en tiempo real para modelos semánticos.
Desde una perspectiva de recursos del servicio Power BI, los modelos de importación requieren:
- Memoria suficiente para cargar el modelo cuando se consulta o actualiza.
- Recursos de procesamiento y recursos de memoria adicionales para actualizar los datos.
Modo DirectQuery
El modo DirectQuery es una alternativa al modo de importación. Los modelos desarrollados en el modo DirectQuery no importan datos. En su lugar, constan solo de metadatos que definen la estructura del modelo. Cuando se consulta el modelo, se usan consultas nativas para recuperar datos del origen de datos subyacente.
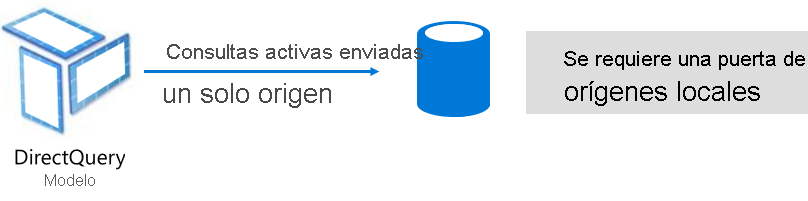
Hay dos razones principales para considerar el desarrollo de un modelo de DirectQuery:
- Cuando los volúmenes de datos son demasiado grandes, incluso cuando se aplican métodos de reducción de datos para cargarlos en un modelo o, prácticamente, para actualizarlos.
- Cuando los informes y paneles deben entregar datos casi en tiempo real, más allá de lo que se puede lograr dentro de límites de actualizaciones programadas. Los límites de actualizaciones programadas son ocho veces al día para la capacidad compartida y 48 veces al día para una capacidad Premium.
Hay varias ventajas asociadas con los modelos de DirectQuery:
- No se aplican los límites de tamaño de los modelos de importación.
- Los modelos no requieren una actualización de datos programada.
- Los usuarios de informes ven los datos más recientes al interactuar con los filtros y las segmentaciones de los informes. Además, los usuarios de informes pueden actualizar todo el informe para recuperar los datos actuales.
- Los informes en tiempo real se pueden desarrollar mediante la característica Actualización automática de páginas.
- Los iconos del panel, cuando se basan en los modelos de DirectQuery, se pueden actualizar automáticamente con una frecuencia de cada 15 minutos.
Pero hay algunas limitaciones asociadas a los modelos de DirectQuery:
- Las expresiones mashup y Power Query solo pueden ser funciones que se pueden transponer en consultas nativas que comprende el origen de datos.
- Las fórmulas de DAX se limitan a usar solo las funciones que se pueden transponer en consultas nativas que comprende el origen de datos. No se admiten las tablas calculadas.
- No se admiten las características de Conclusiones rápidas.
Desde una perspectiva de recursos del servicio Power BI, los modelos de DirectQuery requieren:
- Memoria mínima para cargar el modelo (solo metadatos) cuando se consulta.
- En algunas ocasiones, el servicio Power BI debe usar recursos de procesador significativos para generar y procesar las consultas enviadas al origen de datos. Cuando se produce esta situación, puede afectar al rendimiento, especialmente cuando los usuarios consultan el modelo de manera simultánea.
Para más información, consulte Uso de DirectQuery en Power BI Desktop.
Modo de Composición
El modo de Composición puede combinar los modos de importación y de DirectQuery o integrar varios orígenes de datos de DirectQuery. Los modelos desarrollados en modo de Composición admiten la configuración del modo de almacenamiento para cada tabla del modelo. Este modo también admite tablas calculadas, definidas con DAX.
El modo de almacenamiento de tabla se puede configurar como Importación, DirectQuery o Dual. Una tabla configurada como modo de almacenamiento Dual es tanto Importación como DirectQuery. Esta configuración permite que el servicio Power BI determine el modo más eficaz para usar en cada consulta.
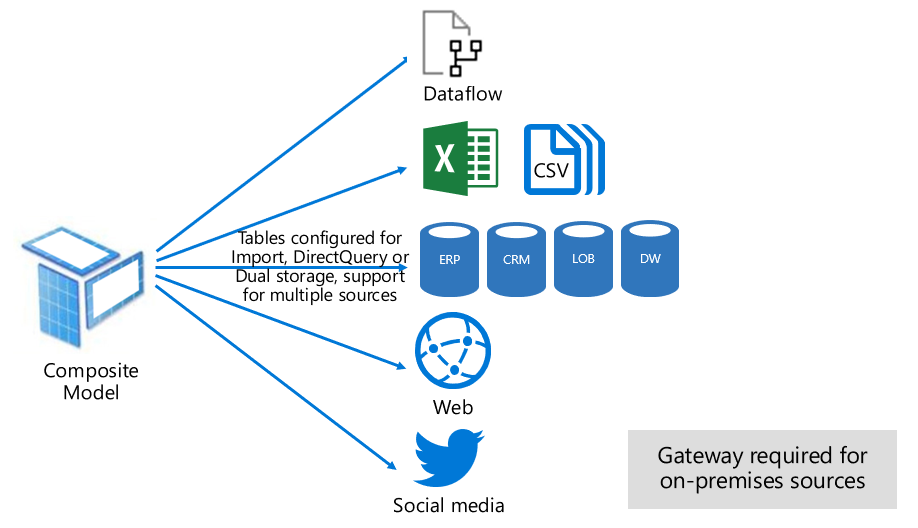
Los modelos compuestos se esfuerzan por ofrecer lo mejor de los modos de Importación y DirectQuery. Cuando se configuran correctamente, pueden combinar el alto rendimiento de consultas de los modelos en memoria con la capacidad de recuperar datos casi en tiempo real de los orígenes de datos.
Para más información, consulte Usar modelos compuestos en Power BI Desktop.
Tablas DirectQuery y de importación pura
Es probable que los modeladores de datos que desarrollan modelos de Composición configuren tablas de tipo de dimensiones en el modo de almacenamiento de Importación o Dual y tablas de tipo de hechos en el modo de DirectQuery. Para más información sobre los roles de tabla de modelo, consulte Descripción de un esquema de estrella e importancia para Power BI.
Por ejemplo, considere un modelo con una tabla de tipo de dimensiones Producto en modo Dual y una tabla de tipo de hechos Ventas en el modo de DirectQuery. La tabla Producto se puede consultar de manera eficaz y rápida desde memoria para representar una segmentación de informe. La tabla Ventas también se podría consultar en el modo de DirectQuery con la tabla Producto. Esta última consulta podría permitir generar una consulta SQL nativa eficaz que combine las tablas Producto y Ventas y que filtre según los valores de segmentación.
Tablas híbridas
Los modeladores de datos que desarrollan modelos compuestos también pueden configurar tablas de hechos como tablas híbridas. Una tabla híbrida es una tabla con una o varias particiones de importación y una partición DirectQuery. La ventaja de una tabla híbrida es que se podría consultar de manera eficaz y rápida desde memoria, al mismo tiempo que se incluyen los cambios de datos más recientes del origen de datos que se produjeron después del último ciclo de importación, como se muestra en la visualización siguiente.

La manera más fácil de crear una tabla híbrida es configurar una directiva de actualización incremental en Power BI Desktop y habilitar la opción Obtener los datos más recientes en tiempo real con DirectQuery (solo Premium). Cuando Power BI aplica una directiva de actualización incremental que tiene esta opción habilitada, particiona la tabla como el esquema de partición mostrado en el diagrama anterior. Para garantizar un buen rendimiento, configure las tablas de tipo de dimensión en modo de almacenamiento dual para que Power BI pueda generar consultas SQL nativas eficaces al consultar la partición DirectQuery.
Nota:
Power BI solo admite tablas híbridas cuando el modelo semántico se hospeda en áreas de trabajo en capacidades Premium. En consecuencia, debe cargar el modelo semántico en un área de trabajo Premium si configura una directiva de actualización incremental con la opción de obtener los datos más recientes en tiempo real con DirectQuery. Para obtener más información, consulte actualización incremental y datos en tiempo real para modelos semánticos.
También es posible convertir una tabla de importación en una tabla híbrida mediante la adición de una partición DirectQuery mediante el lenguaje de scripting del modelo tabular (TMSL), el modelo de objetos tabulares (TOM) o mediante una herramienta de terceros. Por ejemplo, puede crear particiones en una tabla de hechos de forma que la mayor parte de los datos se queden en el almacenamiento de datos y solo se importe una fracción de los datos más recientes. Este enfoque puede ayudar a optimizar el rendimiento si la mayor parte de estos datos son datos históricos a los que se accede con poca frecuencia. Una tabla híbrida puede tener varias particiones de importación, pero solo una partición DirectQuery.