Nota
O acceso a esta páxina require autorización. Pode tentar iniciar sesión ou modificar os directorios.
O acceso a esta páxina require autorización. Pode tentar modificar os directorios.
Sugerencia
Power BI Dataflow Gen1 está ahora en un estado heredado y no recibirá inversiones en nuevas características. Para los clientes Premium con acceso a Fabric, Dataflow Gen2 es la ruta recomendada, que ofrece mejoras en el rendimiento, la escala, la confiabilidad, la funcionalidad y la inteligencia artificial integrada. Los clientes de Pro/PPU pueden seguir usando Gen1 ya que la orientación de Gen2 para estos escenarios está evolucionando. Consulte Upgrade from Dataflow Gen1 to Dataflow Gen2 (Actualización de Dataflow Gen1 a Dataflow Gen2 ) para obtener instrucciones de actualización.
Los flujos de datos de Power BI son una solución de preparación de datos centrada en la empresa, que habilita un ecosistema de datos que está listo para su uso, reutilización e integración. Este artículo presenta algunos escenarios comunes, con vínculos a artículos y otra información que le ayudará a comprender y usar los flujos de datos para sacarles el máximo partido.
Obtención de acceso a las características Premium de los flujos de datos
Los flujos de datos de Power BI de capacidades Premium proporcionan muchas características clave que ayudan a lograr una escala y un rendimiento mayores para los flujos de datos, como los siguientes:
- Proceso avanzado, que acelera el rendimiento de ETL y proporciona capacidades de DirectQuery.
- Actualización incremental, que permite cargar datos que han cambiado desde un origen.
- Entidades vinculadas, que puede usar para hacer referencia a otros flujos de datos.
- Entidades calculadas, que puede usar para crear bloques componibles de flujos de datos que contienen lógica de negocios.
Por estos motivos, se recomienda que use flujos de datos en una capacidad Premium siempre que sea posible. Los flujos de datos usados con una licencia de Power BI Pro se pueden usar para casos de uso sencillos y a pequeña escala.
Solución
Se puede obtener acceso a estas características prémium de los flujos de datos de dos maneras:
- Designe una capacidad Premium a un área de trabajo determinada y traiga su propia licencia Pro para crear flujos de datos aquí.
- Traiga su propia licencia Premium por usuario (PPU) , que requiere que otros miembros del área de trabajo también posean una licencia PPU.
No puede consumir flujos de datos PPU (ni ningún otro contenido) fuera del entorno de PPU (por ejemplo, en Premium u otras SKU o licencias).
Para las capacidades Premium, sus consumidores de flujos de datos en Power BI Desktop no necesitan licencias explícitas para consumir y publicar en Power BI. Pero para publicar en un área de trabajo o compartir un modelo semántico resultante, necesita al menos una licencia Pro.
Para PPU, todos los usuarios que crean o consumen contenido PPU deben tener una licencia PPU. Este requisito varía del resto de Power BI en que necesita licenciar explícitamente a todos los usuarios con PPU. No puede mezclar las capacidades Free, Pro o incluso Premium con el contenido PPU a menos que migre el área de trabajo a una capacidad Premium.
La elección de un modelo depende normalmente del tamaño y de los objetivos de la organización, pero se aplican las siguientes directrices.
| Tipo de equipo | Premium por capacidad | Premium por usuario |
|---|---|---|
| >5000 usuarios | ✔ | |
| <5000 usuarios | ✔ |
En el caso de equipos pequeños, PPU puede cerrar la brecha entre Gratis, Pro y Premium por capacidad. Si tiene necesidades más grandes, el mejor enfoque es usar Premium con usuarios que tienen licencias Pro.
Creación de flujos de datos de usuario con seguridad aplicada
Imagine que necesita crear flujos de datos para consumir, pero tiene requisitos de seguridad:
En este escenario, es probable que tenga dos tipos de áreas de trabajo:
Áreas de trabajo de back-end donde desarrollar flujos de datos y crear la lógica de negocios.
Áreas de trabajo de usuario en las que desea exponer algunos flujos de datos o tablas a un grupo determinado de usuarios para su consumo:
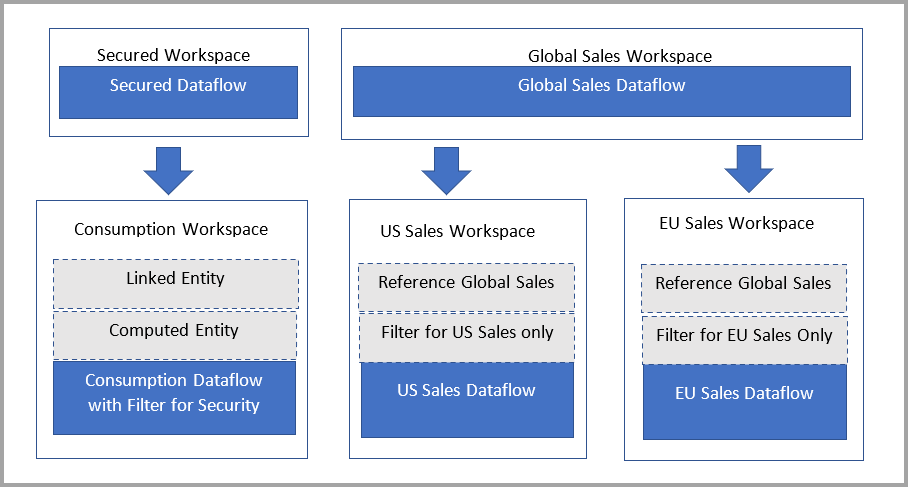
- El área de trabajo del usuario contiene tablas vinculadas que apuntan a los flujos de datos del área de trabajo de back-end.
- Los usuarios tienen acceso de visualizador al área de trabajo del consumidor y no tienen acceso al área de trabajo de servidor.
- Cuando un usuario usa Power BI Desktop para acceder a un flujo de datos en el área de trabajo del usuario, puede ver el flujo de datos. Pero como el flujo de datos aparece vacío en el navegador, las tablas vinculadas no se muestran.
Comprender las tablas vinculadas
Las tablas vinculadas son simplemente un puntero a las tablas de flujo de datos originales y heredan el permiso del origen. Si Power BI permitiera a la tabla vinculada usar el permiso de destino, cualquier usuario podría sortear el permiso de origen mediante la creación de una tabla vinculada en el destino que apunte al origen.
Solución: uso de tablas calculadas
Si tiene acceso a Power BI Premium, puede crear una tabla calculada en el destino que hace referencia a la tabla vinculada, que tiene una copia de los datos de esta última. Puede quitar columnas a través de proyecciones y quitar filas a través de filtros. El usuario con permiso en el área de trabajo de destino puede acceder a los datos a través de esta tabla.
El linaje de los usuarios con privilegios también muestra el área de trabajo a la que se hace referencia y permitirá a los usuarios volver a establecer el vínculo para comprender completamente el flujo de datos primario. Para los usuarios que no tienen privilegios, se sigue respetando la privacidad. Solo se muestra el nombre del área de trabajo.
El diagrama siguiente muestra esta configuración. A la izquierda está el patrón arquitectónico. A la derecha hay un ejemplo que muestra los datos de ventas divididos y asegurados por región.
Reducción de los tiempos de actualización de flujos de datos
Imagine que tiene un gran flujo de datos, pero quiere crear modelos semánticos a partir de ese flujo de datos y reducir el tiempo necesario para actualizarlo. Normalmente, las actualizaciones tardan mucho tiempo en completarse desde la fuente de datos a los flujos de datos y al modelo semántico. Las actualizaciones largas son difíciles de administrar o mantener.
Solución: Utilizar tablas con la opción Habilitar carga configurada explícitamente para las tablas de referencia y no deshabilitar la carga.
Power BI admite una orquestación simple de flujos de datos, tal como se define en Descripción y optimización de la actualización de flujos de datos. Para aprovechar la orquestación, es necesario tener explícitamente cualesquiera flujos de datos descendentes configurados en Habilitar carga.
Deshabilitar la carga solo suele ser adecuado cuando la sobrecarga que supone cargar más consultas anula la ventaja de la entidad con la que está desarrollando.
Si bien deshabilitar la carga significa que Power BI no evalúa esa consulta determinada, cuando se usa como ingredientes, es decir, se hace referencia a ella en otros flujos de datos, también significa que Power BI no la trata como una tabla existente a la que se puede proporcionar un puntero y realizar optimizaciones de plegado y consulta. En este sentido, realizar transformaciones como una unión o combinación es simplemente una unión o combinación de dos consultas de origen de datos. Estas operaciones pueden afectar negativamente al rendimiento porque Power BI debe volver a cargar completamente la lógica ya calculada y, a continuación, aplicar cualquier lógica adicional.
Para simplificar el procesamiento de consultas del flujo de datos y asegurarse de que se están llevando a cabo optimizaciones del motor, habilite la carga y asegúrese de que el motor de proceso de los flujos de datos de Power BI Premium está establecido en la configuración predeterminada, que es Optimizado.
La habilitación de la carga también le permite mantener la vista completa del linaje porque Power BI considera un flujo de datos de carga no habilitado como un nuevo elemento. Si el linaje es importante para usted, no deshabilite la carga de entidades o flujos de datos conectados a otros flujos de datos.
Reducir el tiempo de actualización de los modelos semánticos
Imagine que tiene un flujo de datos grande, pero quiere crear modelos semánticos a partir de él y reducir la orquestación. Las actualizaciones tardan mucho tiempo en completarse desde la fuente de datos hasta los flujos de datos y los modelos semánticos, lo que aumenta la latencia.
Solución: uso de flujos de datos DirectQuery
DirectQuery se puede usar siempre que la configuración del motor de proceso mejorado (ECE) de un área de trabajo se configure explícitamente en Activada. Esta configuración es útil cuando tiene datos que no necesitan cargarse directamente en un modelo de Power BI. Si va a configurar el ECE para que esté Activado por primera vez, los cambios que permiten DirectQuery se producirán durante la siguiente actualización. Debe actualizarla cuando la habilite para que se produzcan cambios inmediatamente. Las actualizaciones en la carga del flujo de datos inicial pueden ser más lentas porque Power BI escribe datos en el almacenamiento y en un motor de SQL administrado.
En resumen, el uso de DirectQuery con flujos de datos permite las siguientes mejoras en los procesos de Power BI y flujos de datos:
- Evitar programas de actualización independientes: DirectQuery se conecta directamente a un flujo de datos, lo que elimina la necesidad de crear un modelo semántico importado. De este modo, al utilizar DirectQuery con sus flujos de datos, ya no necesitará programas de actualización independientes para el flujo de datos y el modelo semántico a fin de garantizar la sincronización de los datos.
- Filtrado de datos: DirectQuery resulta útil para trabajar en una vista filtrada de los datos dentro de un flujo de datos. Si desea filtrar los datos y, de esta manera, trabajar con un subconjunto más pequeño de los datos del flujo de datos, puede usar DirectQuery (y el ECE) para filtrar los datos de flujo de datos y trabajar con el subconjunto filtrado que necesite.
Por lo general, al utilizar DirectQuery se intercambian datos actualizados en su modelo semántico con un rendimiento del informe más lento en comparación con el modo de importación. Tenga en cuenta este enfoque solamente cuando:
- El caso de uso requiere datos de baja latencia procedentes del flujo de datos.
- Los datos de flujo de datos son grandes.
- Una importación sería demasiado lenta.
- Está dispuesto a intercambiar el rendimiento almacenado en caché por los datos actualizados.
Solución: utilice el conector de flujos de datos para habilitar el plegado de consultas y la actualización incremental durante la importación
El conector de flujos de datos unificado puede reducir considerablemente el tiempo de evaluación de los pasos realizados en entidades calculadas, como realizar combinaciones, distinciones, filtros y agrupaciones por operaciones. Hay dos ventajas específicas:
- Los usuarios descendentes que se conectan al conector de Dataflows en Power BI Desktop pueden beneficiarse de un mejor rendimiento en escenarios de creación, ya que el nuevo conector admite el plegado de consultas.
- Las operaciones de actualización del modelo semántico también pueden plegarse al motor de cálculo mejorado, lo que significa que incluso la actualización incremental de un modelo semántico puede plegarse a un flujo de datos. Esta funcionalidad mejora el rendimiento de la actualización y reduce potencialmente la latencia entre los ciclos de actualización.
Para habilitar esta característica para cualquier flujo de datos Premium, asegúrese de que el motor de proceso esté establecido explícitamente en Activado. A continuación, use el conector de flujos de datos en Power BI Desktop. Debe usar la versión de agosto de 2021 de Power BI Desktop o posterior para aprovechar esta característica.
Para usar esta característica para las soluciones existentes, debe tener una suscripción Premium o Premium por usuario. También es posible que tenga que realizar algunos cambios en el flujo de datos como se describe en Uso del motor de proceso mejorado. Debe actualizar las consultas de Power Query existentes para usar el nuevo conector reemplazando PowerBI.Dataflows en la sección Origen por PowerPlatform.Dataflows.
Creación de flujos de datos complejos en Power Query
Imagine que tiene un flujo de datos que tiene millones de filas de datos, pero quiere crear transformaciones y lógica de negocios complejas con él. Quiere seguir los procedimientos recomendados para trabajar con flujos de datos grandes. También necesita que las visualizaciones del flujo de datos funcionen rápidamente. Sin embargo, tiene decenas de columnas y millones de filas de datos.
Solución: uso de la vista Esquema
Puede usar la vista Esquema, que está diseñada para optimizar el flujo al trabajar en operaciones de nivel de esquema. Para ello, coloque la información de columna de la consulta delante y en el centro. La vista esquema proporciona interacciones contextuales para dar forma a la estructura de datos. La vista de esquema también proporciona operaciones de menor latencia porque solo requiere que se calculen los metadatos de columna y no los resultados de los datos completos.
Trabajo con orígenes de datos de mayor tamaño
Imagine que ejecuta una consulta en el sistema de origen, pero no quiere proporcionar acceso directo al sistema ni democratizar el acceso. Tiene previsto colocarlo en un flujo de datos.
Solución 1: uso de una vista para la consulta u optimización de esta
Usar una fuente de datos optimizada y una consulta es la mejor opción. A menudo, el origen de datos funciona mejor con consultas pensadas para él. Power Query avanza las funcionalidades de plegado de consultas para delegar estas cargas de trabajo. Power BI también proporciona indicadores de plegado de pasos en Power Query Online. Lea más sobre los tipos de indicadores en la documentación de indicadores de plegado por etapas.
Solución 2: Usar la consulta nativa
También puede usar la función M Value.NativeQuery(). Establezca EnableFolding=true en el tercer parámetro. La consulta nativa se documenta en este sitio web para el conector de Postgres. También funciona para el conector de SQL Server.
Solución 3: Dividir el flujo de datos en flujos de datos de ingesta y consumo para aprovechar las ventajas del ECE y las entidades vinculadas
Al dividir un flujo de datos en flujos de datos de ingesta y consumo independientes puede aprovechar las ventajas del ECE y las entidades vinculadas. Puede obtener más información sobre este patrón y otros en la documentación de procedimientos recomendados.
Garantía de que los clientes usan flujos de datos siempre que sea posible
Imagine que tiene muchos flujos de datos que sirven para finalidades comunes, como dimensiones ajustadas (por ejemplo clientes, tablas de datos, productos y zonas geográficas). Los flujos de datos ya están disponibles en la cinta de opciones para Power BI. Lo ideal es que los clientes usen principalmente los flujos de datos que ha creado.
Solución: uso de la aprobación para certificar y promover flujos de datos
Para obtener más información sobre cómo funciona la aprobación, consulte Aprobación: promoción y certificación del contenido de Power BI.
Capacidad de programación y automatización en flujos de datos de Power BI
Imagine que tiene requisitos empresariales para automatizar importaciones, exportaciones o actualizaciones, así como orquestaciones y acciones adicionales fuera de Power BI. Tiene algunas opciones para habilitar estas operaciones, como se describe en la tabla siguiente.
| Tipo | Mecanismo |
|---|---|
| Use las plantillas de Power Automate. | Sin código |
| Use los scripts de automatización en PowerShell. | Scripts de automatización |
| Cree su propia lógica de negocios mediante las API. | API de REST |
Para más información sobre la actualización, consulte Descripción y optimización de la actualización de flujos de datos.
Asegúrate de proteger los recursos de datos posteriores
Puede usar etiquetas de confidencialidad para aplicar una clasificación de datos y cualquier regla que haya configurado en elementos posteriores que se conecten a sus flujos de datos. Para obtener más información sobre las etiquetas de confidencialidad, consulte etiquetas de confidencialidad en Power BI. Para revisar la herencia, consulte Herencia descendente de las etiquetas de confidencialidad en Power BI.
Compatibilidad con Multi-Geo
En la actualidad, muchos clientes necesitan cumplir requisitos de soberanía y residencia de datos. Puede completar una configuración manual para que el área de trabajo de flujos de datos sea multigeográfica.
Los flujos de datos admiten multigeo cuando usan la característica de llevar tu propia cuenta de almacenamiento. Esta característica se describe en Configuración del almacenamiento de flujo de datos para usar Azure Data Lake Gen 2. El área de trabajo debe estar vacía antes de adjuntarla para esta funcionalidad. Con esta configuración específica, puede almacenar datos del flujo de datos en las regiones geográficas que elija.
Garantía de protección de los recursos de datos detrás de una red virtual
En la actualidad, muchos clientes tienen la necesidad de proteger los recursos de datos detrás de un punto de conexión privado. Para ello, use las redes virtuales y una puerta de enlace para mantener la conformidad. En la tabla siguiente se describe la compatibilidad actual con la red virtual y se explica cómo usar los flujos de datos para mantener la conformidad y proteger los recursos de datos.
| Escenario | Estado |
|---|---|
| Leer orígenes de datos de red virtual a través de una puerta de enlace local. | Se admite a través de una puerta de enlace local |
| Escribe datos en una cuenta de etiqueta de sensibilidad detrás de una red virtual mediante una puerta de enlace local. | Todavía no se admite |
Contenido relacionado
En los artículos siguientes encontrará más información sobre los flujos de datos y Power BI:
- Introducción a los flujos de datos y la preparación de datos de autoservicio
- Crear un flujo de datos
- Configurar y consumir un flujo de datos
- Características prémium de flujos de datos
- Planeamiento de la implementación de Power BI: integración con otros servicios
- Consideraciones y limitaciones de flujos de datos
- Procedimientos recomendados para flujos de datos