Accelerated Database Recovery in Azure SQL
Applies to: ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Accelerated Database Recovery (ADR) is a SQL Server database engine feature that greatly improves database availability, especially in the presence of long running transactions, by redesigning the SQL Server database engine recovery process.
ADR is currently available for Azure SQL Database, Azure SQL Managed Instance, databases in Azure Synapse Analytics, and SQL Server on Azure VMs starting with SQL Server 2019. For information on ADR in SQL Server, see Manage accelerated database recovery.
Note
ADR is enabled by default in Azure SQL Database and Azure SQL Managed Instance. Disabling ADR in Azure SQL Database and Azure SQL Managed Instance is not supported.
Overview
The primary benefits of ADR are:
Fast and consistent database recovery
With ADR, long running transactions do not impact the overall recovery time, enabling fast and consistent database recovery irrespective of the number of active transactions in the system or their sizes.
Instantaneous transaction rollback
With ADR, transaction rollback is instantaneous, irrespective of the time that the transaction has been active or the number of updates that has performed.
Aggressive log truncation
With ADR, the transaction log is aggressively truncated, even in the presence of active long-running transactions, which prevents it from growing out of control.
Standard database recovery process
Database recovery follows the ARIES recovery model and consists of three phases, which are illustrated in the following diagram and explained in more detail following the diagram.
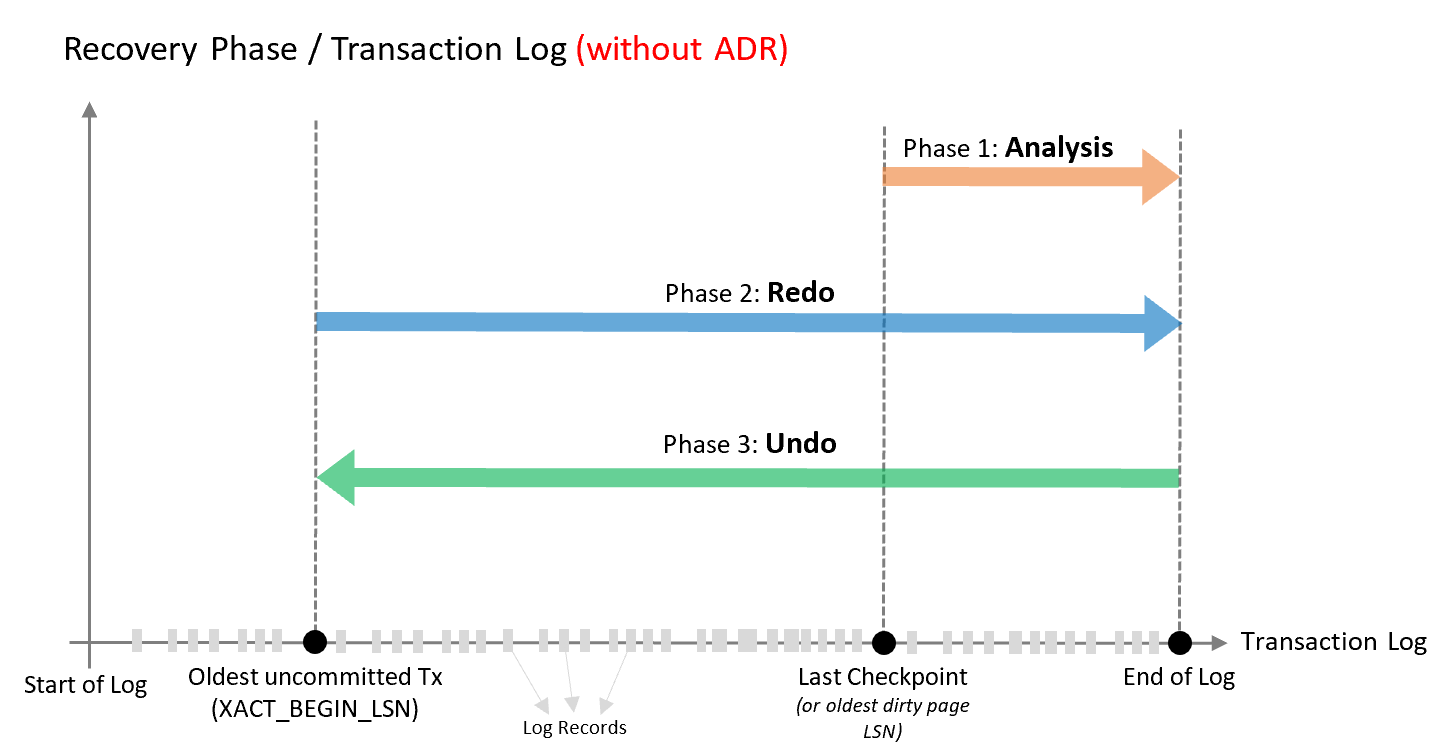
Analysis phase
Forward scan of the transaction log from the beginning of the last successful checkpoint (or the oldest dirty page LSN) until the end, to determine the state of each transaction at the time the database stopped.
Redo phase
Forward scan of the transaction log from the oldest uncommitted transaction until the end, to bring the database to the state it was at the time of the crash by redoing all committed operations.
Undo phase
For each transaction that was active as of the time of the crash, traverses the log backwards, undoing the operations that this transaction performed.
Based on this design, the time it takes the SQL Server database engine to recover from an unexpected restart is (roughly) proportional to the size of the longest active transaction in the system at the time of the crash. Recovery requires a rollback of all incomplete transactions. The length of time required is proportional to the work that the transaction has performed and the time it has been active. Therefore, the recovery process can take a long time in the presence of long-running transactions (such as large bulk insert operations or index build operations against a large table).
Also, cancelling/rolling back a large transaction based on this design can also take a long time as it is using the same Undo recovery phase as described above.
In addition, the SQL Server database engine cannot truncate the transaction log when there are long-running transactions because their corresponding log records are needed for the recovery and rollback processes. As a result of this design of the SQL Server database engine, some customers used to face the problem that the size of the transaction log grows very large and consumes huge amounts of drive space.
The Accelerated Database Recovery process
ADR addresses the above issues by completely redesigning the SQL Server database engine recovery process to:
- Make it constant time/instant by avoiding having to scan the log from/to the beginning of the oldest active transaction. With ADR, the transaction log is only processed from the last successful checkpoint (or oldest dirty page Log Sequence Number (LSN)). As a result, recovery time is not impacted by long running transactions.
- Minimize the required transaction log space since there is no longer a need to process the log for the whole transaction. As a result, the transaction log can be truncated aggressively as checkpoints and backups occur.
At a high level, ADR achieves fast database recovery by versioning all physical database modifications and only undoing logical operations, which are limited and can be undone almost instantly. Any transaction that was active as of the time of a crash are marked as aborted and, therefore, any versions generated by these transactions can be ignored by concurrent user queries.
The ADR recovery process has the same three phases as the current recovery process. How these phases operate with ADR is illustrated in the following diagram and explained in more detail following the diagram.
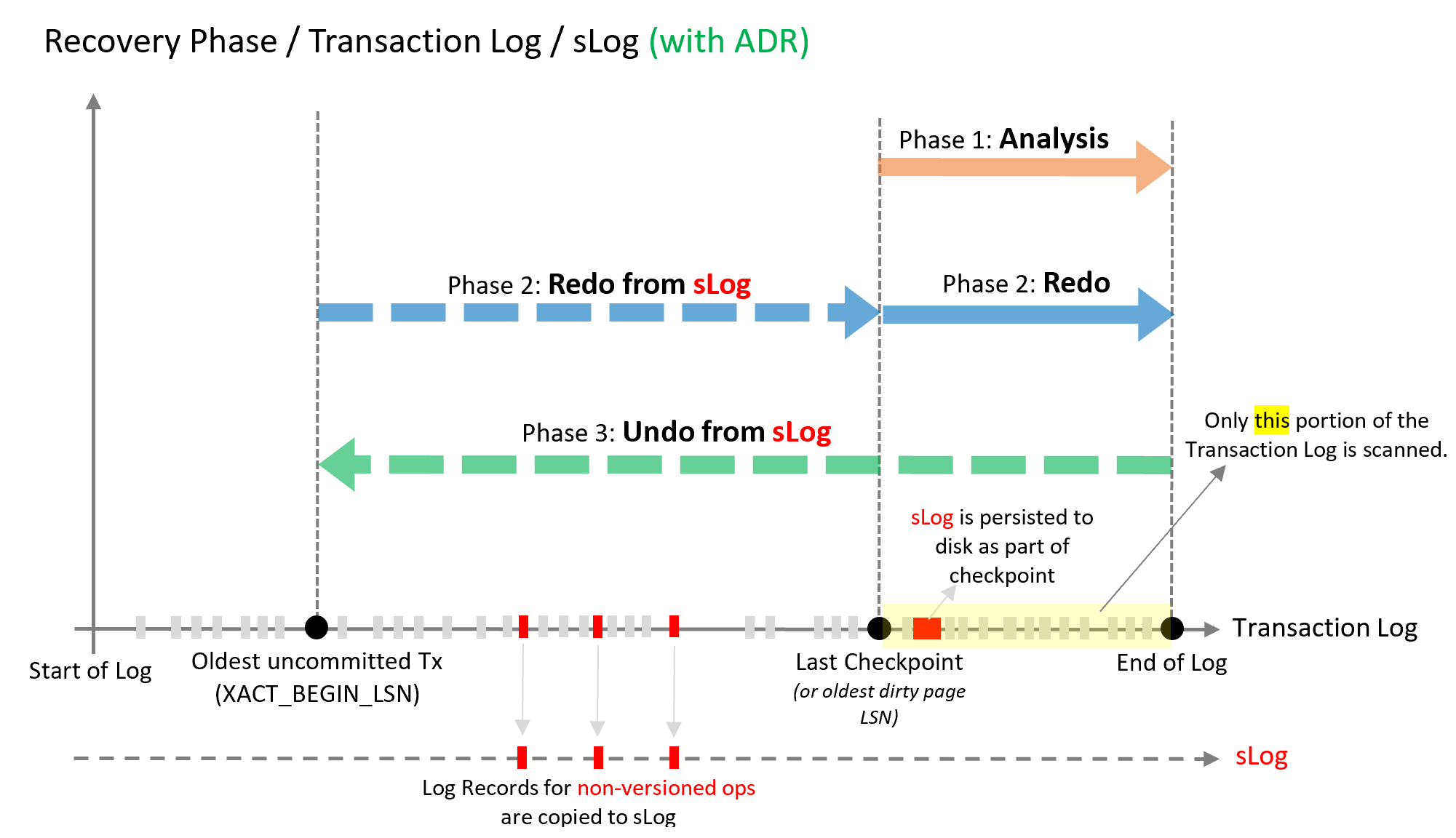
Analysis phase
The process remains the same as before with the addition of reconstructing SLOG and copying log records for non-versioned operations.
Redo phase
Broken into two phases (P)
Phase 1
Redo from SLOG (oldest uncommitted transaction up to last checkpoint). Redo is a fast operation as it only needs to process a few records from the SLOG.
Phase 2
Redo from Transaction Log starts from last checkpoint (instead of oldest uncommitted transaction)
Undo phase
The Undo phase with ADR completes almost instantaneously by using SLOG to undo non-versioned operations and Persisted Version Store (PVS) with Logical Revert to perform row level version-based Undo.
ADR recovery components
The four key components of ADR are:
Persisted version store (PVS)
The persisted version store is a new SQL Server database engine mechanism for persisting the row versions generated in the database itself instead of the traditional
tempdbversion store. PVS enables resource isolation as well as improves availability of readable secondaries.Logical revert
Logical revert is the asynchronous process responsible for performing row-level version-based Undo - providing instant transaction rollback and undo for all versioned operations. Logical revert is accomplished by:
- Keeping track of all aborted transactions and marking them invisible to other transactions.
- Performing rollback by using PVS for all user transactions, rather than physically scanning the transaction log and undoing changes one at a time.
- Releasing all locks immediately after transaction abort. Since abort involves simply marking changes in memory, the process is very efficient and therefore locks do not have to be held for a long time.
SLOG
SLOG is a secondary in-memory log stream that stores log records for non-versioned operations (such as metadata cache invalidation, lock acquisitions, and so on). The SLOG is:
- Low volume and in-memory
- Persisted on disk by being serialized during the checkpoint process
- Periodically truncated as transactions commit
- Accelerates redo and undo by processing only the non-versioned operations
- Enables aggressive transaction log truncation by preserving only the required log records
Cleaner
The cleaner is the asynchronous process that wakes up periodically and cleans page versions that are not needed.
Accelerated Database Recovery (ADR) patterns
The following types of workloads benefit most from ADR:
- ADR is recommended for workloads with long running transactions.
- ADR is recommended for workloads that have seen cases where active transactions are causing the transaction log to grow significantly.
- ADR is recommended for workloads that have experienced long periods of database unavailability due to long running recovery (such as unexpected service restart or manual transaction rollback).
Best practices for Accelerated Database Recovery
Avoid long-running transactions in the database. Though one objective of ADR is to speed up database recovery due to redo long active transactions, long-running transactions can delay version cleanup and increase the size of the PVS.
Avoid large transactions with data definition changes or DDL operations. ADR uses a SLOG (system log stream) mechanism to track DDL operations used in recovery. The SLOG is only used while the transaction active. SLOG is checkpointed, so avoiding large transactions that use SLOG can help overall performance. These scenarios can cause the SLOG to take up more space:
Many DDLs are executed in one transaction. For example, in one transaction, rapidly creating and dropping temp tables.
A table has very large number of partitions/indexes that are modified. For example, a DROP TABLE operation on such table would require a large reservation of SLOG memory, which would delay truncation of the transaction log and delay undo/redo operations. As a workaround, drop the indexes individually and gradually, then drop the table. For more information on the SLOG, see ADR recovery components.
Prevent or reduce unnecessary aborted situations. A high abort rate will put pressure on the PVS cleaner and lower ADR performance. The aborts may come from a high rate of deadlocks, duplicate keys, or other constraint violations.
The
sys.dm_tran_aborted_transactionsDMV shows all aborted transactions on the SQL Server instance. Thenested_abortcolumn indicates that the transaction committed but there are portions that aborted (savepoints or nested transactions) which can block the PVS cleanup process. For more information, see sys.dm_tran_aborted_transactions (Transact-SQL).To activate the PVS cleanup process manually between workloads or during maintenance windows, use
sys.sp_persistent_version_cleanup. For more information, see sys.sp_persistent_version_cleanup.
If you observe issues either with storage usage, high abort transaction and other factors, see Troubleshooting Accelerated Database Recovery (ADR) on SQL Server.