Business continuity management in Azure
Azure maintains one of the most mature and respected business continuity management programs in the industry. The goal of business continuity in Azure is to build and advance recoverability and resiliency for all independently recoverable services, whether a service is customer-facing (part of an Azure offering) or an internal supporting platform service.
In understanding business continuity, it's important to note that many offerings are made up of multiple services. At Azure, each service is statically identified through tooling and is the unit of measure used for privacy, security, inventory, risk business continuity management, and other functions. To properly measure capabilities of a service, the three elements of people, process, and technology are included for each service, whatever the service type.
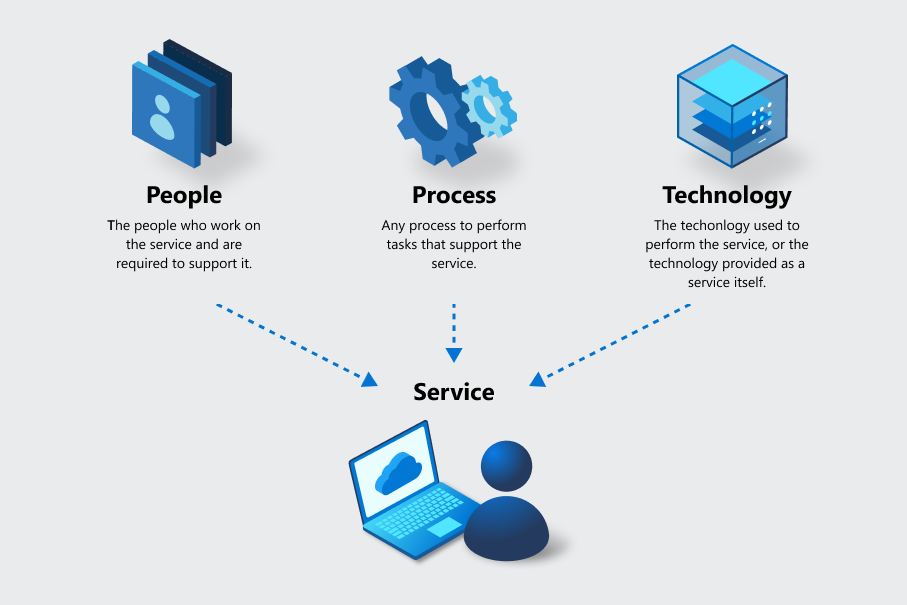
For example:
- If there's a business process based on people, such as a help desk or team, the service delivery is what they do. The people use processes and technology to perform the service.
- If there's technology as a service, such as Azure Virtual Machines, the service delivery is the technology along with the people and processes that support its operation.
Shared responsibility model
Many of the offerings Azure provides require you to set up disaster recovery in multiple regions and aren't the responsibility of Microsoft. Not all Azure services automatically replicate data or automatically fall back from a failed region to cross-replicate to another enabled region. In these cases, you are responsible for configuring recovery and replication.
Microsoft does ensure that the baseline infrastructure and platform services are available. But in some scenarios, usage demands that you duplicate your deployments and storage in a multi-region capacity, if you choose to. These examples illustrate the shared responsibility model. It's a fundamental pillar in your business continuity and disaster recovery strategy.
Division of responsibility
In any on-premises datacenter, you own the whole stack. As you move assets to the cloud, some responsibilities transfer to Microsoft. The following diagram illustrates areas and division of responsibility between you and Microsoft according to the type of deployment.
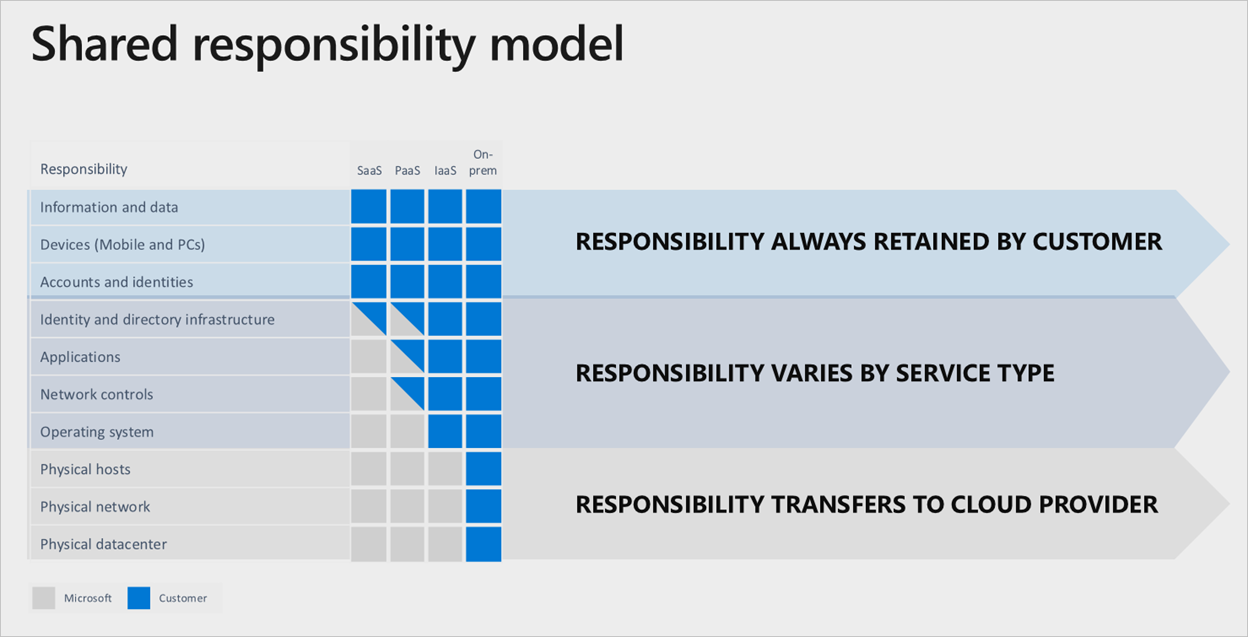
A good example of the shared responsibility model is the deployment of virtual machines. If you want to set up cross-region replication for resiliency if there's region failure, you must deploy a duplicate set of virtual machines in an alternate enabled region. Azure doesn't automatically replicate these services over if there's a failure. It's your responsibility to deploy necessary assets. You must have a process to manually change primary regions, or you must use a traffic manager to detect and automatically fail over.
Customer-enabled disaster recovery services all have public-facing documentation to guide you. For an example of public-facing documentation for customer-enabled disaster recovery, see Azure Data Lake Analytics.
For more information on the shared responsibility model, see Microsoft Trust Center.
Business continuity compliance: Service-level responsibility
Each service is required to complete Business Continuity Disaster Recovery records in the Azure Business Continuity Manager Tool. Service owners can use the tool to work within a federated model to complete and incorporate requirements that include:
Service properties: Defines the service and how disaster recovery and resiliency are achieved and identifies the responsible party for disaster recovery (for technology). For details on recovery ownership, see the discussion on the shared responsibility model in the preceding section and diagram.
Business impact analysis: This analysis helps the service owner define the recovery time objective (RTO) and recovery point objective (RPO) based on the criticality of the service across a table of impacts. Operational, legal, regulatory, brand image, and financial impacts are used as target goals for recovery.
Note
Microsoft doesn't publish RTO or RPOs for services because this data is for internal measures only. All customer promises and measures are SLA-based because it covers a wider range versus RTO or RPO, which is only applicable in catastrophic loss.
Dependencies: Each service maps the dependencies (other services) it requires to operate no matter how critical, and is mapped to runtime, needed for recovery only, or both. If there are storage dependencies, another data is mapped that defines what's stored, and if it requires point-in-time snapshots, for example.
Workforce: As noted in the definition of a service, it's important to know the location and quantity of workforce able to support the service, ensuring no single points of failure, and if critical employees are dispersed to avoid failures by cohabitation in a single location.
External suppliers: Microsoft keeps a comprehensive list of external suppliers, and the suppliers deemed critical are measured for capabilities. If identified by a service as a dependency, supplier capabilities are compared to the needs of the service to ensure a third-party outage doesn't disrupt Azure services.
Recovery rating: This rating is unique to the Azure Business Continuity Management program. This rating measures several key elements to create a resiliency score:
- Willingness to fail over: Although there can be a process, it might not be the first choice for short-term outages.
- Automation of failover.
- Automation of the decision to fail over.
The most reliable and shortest time to failover is a service that's automated and requires no human decision. An automated service uses heartbeat monitoring or synthetic transactions to determine a service is down and to start immediate remediation.
Recovery plan and test: Azure requires every service to have a detailed recovery plan and to test that plan as if the service has failed because of catastrophic outage. The recovery plans are required to be written so that someone with similar skills and access can complete the tasks. A written plan avoids relying on subject matter experts being available.
Testing is done in several ways, including self-test in a production or near-production environment, and as part of Azure full-region down drills in canary region sets. These enabled regions are identical to production regions but can be disabled without affecting your services. Testing is considered integrated because all services are affected simultaneously.
Customer enablement: When you are responsible for setting up disaster recovery, Azure is required to have public-facing documentation guidance. For all such services, links are provided to documentation and details about the process.
Verify your business continuity compliance
When a service has completed its business continuity management record, you must submit it for approval. It's assigned to a business continuity management experienced practitioner who reviews the entire record for completeness and quality. If the record meets all requirements, it's approved. If it doesn't, it's rejected with a request for reworking. This process ensures that both parties agree that business continuity compliance has been met and that the work is only attested to by the service owner. Azure internal audit and compliance teams also do periodic random sampling to ensure the best data is being submitted.
Testing of services
Microsoft and Azure do extensive testing for both disaster recovery and for availability zone readiness. Services are self-tested in a production or pre-production environment to demonstrate independent recoverability for services that aren't dependent on major platform failovers.
To ensure services can similarly recover in a true region-down scenario, "pull-the-plug"-type testing is done in canary environments that are fully deployed regions matching production. For example, the clusters, racks, and power units are literally turned off to simulate a total region failure.
During these tests, Azure uses the same production process for detection, notification, response, and recovery. No individuals are expecting a drill, and engineers relied on for recovery are the normal on-call rotation resources. This timing avoids depending on subject matter experts who might not be available during an actual event.
Included in these tests are services where you are responsible for setting up disaster recovery following Microsoft public-facing documentation. Service teams create customer-like instances to show that customer-enabled disaster recovery works as expected and that the instructions provided are accurate.
For more information on certifications, see the Microsoft Trust Center and the section on compliance.