Indexers in Azure AI Search
An indexer in Azure AI Search is a crawler that extracts textual data from cloud data sources and populates a search index using field-to-field mappings between source data and a search index. This approach is sometimes referred to as a 'pull model' because the search service pulls data in without you having to write any code that adds data to an index.
Indexers also drive skillset execution and AI enrichment, where you can configure skills to integrate extra processing of content en route to an index. A few examples are OCR over image files, text split skill for data chunking, text translation for multiple languages.
Indexers target supported data sources. An indexer configuration specifies a data source (origin) and a search index (destination). Several sources, such as Azure Blob Storage, have more configuration properties specific to that content type.
You can run indexers on demand or on a recurring data refresh schedule that runs as often as every five minutes. More frequent updates require a 'push model' that simultaneously updates data in both Azure AI Search and your external data source.
A search service runs one indexer job per search unit. If you need concurrent processing, make sure you have sufficient replicas. Indexers don't run in the background, so you might detect more query throttling than usual if the service is under pressure.
Indexer scenarios and use cases
You can use an indexer as the sole means for data ingestion, or in combination with other techniques. The following table summarizes the main scenarios.
| Scenario | Strategy |
|---|---|
| Single data source | This pattern is the simplest: one data source is the sole content provider for a search index. Most supported data sources provide some form of change detection so that subsequent indexer runs pick up the difference when content is added or updated in the source. |
| Multiple data sources | An indexer specification can have only one data source, but the search index itself can accept content from multiple sources, where each indexer run brings new content from a different data provider. Each source can contribute its share of full documents, or populate selected fields in each document. For a closer look at this scenario, see Tutorial: Index from multiple data sources. |
| Multiple indexers | Multiple data sources are typically paired with multiple indexers if you need to vary run time parameters, the schedule, or field mappings. Cross-region scale out of Azure AI Search is another scenario. You might have copies of the same search index in different regions. To synchronize search index content, you could have multiple indexers pulling from the same data source, where each indexer targets a different search index in each region. Parallel indexing of very large data sets also requires a multi-indexer strategy, where each indexer targets a subset of the data. |
| Content transformation | Indexers drive skillset execution and AI enrichment. Content transforms are defined in a skillset that you attach to the indexer. You can use skills to incorporate data chunking and vectorization. |
You should plan on creating one indexer for every target index and data source combination. You can have multiple indexers writing into the same index, and you can reuse the same data source for multiple indexers. However, an indexer can only consume one data source at a time, and can only write to a single index. As the following graphic illustrates, one data source provides input to one indexer, which then populates a single index:

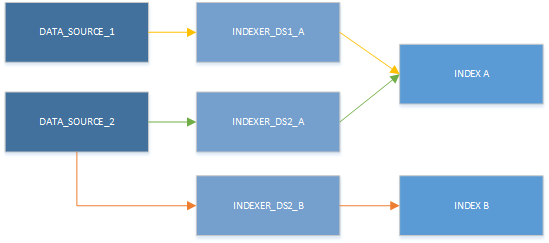
Although you can only use one indexer at a time, resources can be used in different combinations. The main takeaway of the next illustration is to notice is that a data source can be paired with more than one indexer, and multiple indexers can write to same index.
Supported data sources
Indexers crawl data stores on Azure and outside of Azure.
- Azure Blob Storage
- Azure Cosmos DB
- Azure Data Lake Storage Gen2
- Azure SQL Database
- Azure Table Storage
- Azure SQL Managed Instance
- SQL Server on Azure Virtual Machines
- Azure Files (in preview)
- Azure MySQL (in preview)
- SharePoint in Microsoft 365 (in preview)
- Azure Cosmos DB for MongoDB (in preview)
- Azure Cosmos DB for Apache Gremlin (in preview)
Azure Cosmos DB for Cassandra is not supported.
Indexers accept flattened row sets, such as a table or view, or items in a container or folder. In most cases, it creates one search document per row, record, or item.
Indexer connections to remote data sources can be made using standard Internet connections (public) or encrypted private connections when you use a shared private link. You can also set up connections to authenticate using a managed identity. For more information about secure connections, see Indexer access to content protected by Azure network security features and Connect to a data source using a managed identity.
Stages of indexing
On an initial run, when the index is empty, an indexer will read in all of the data provided in the table or container. On subsequent runs, the indexer can usually detect and retrieve just the data that has changed. For blob data, change detection is automatic. For other data sources like Azure SQL or Azure Cosmos DB, change detection must be enabled.
For each document it receives, an indexer implements or coordinates multiple steps, from document retrieval to a final search engine "handoff" for indexing. Optionally, an indexer also drives skillset execution and outputs, assuming a skillset is defined.

Stage 1: Document cracking
Document cracking is the process of opening files and extracting content. Text-based content can be extracted from files on a service, rows in a table, or items in container or collection. If you add a skillset and image skills, document cracking can also extract images and queue them for image processing.
Depending on the data source, the indexer will try different operations to extract potentially indexable content:
When the document is a file with embedded images, such as a PDF, the indexer extracts text, images, and metadata. Indexers can open files from Azure Blob Storage, Azure Data Lake Storage Gen2, and SharePoint.
When the document is a record in Azure SQL, the indexer will extract non-binary content from each field in each record.
When the document is a record in Azure Cosmos DB, the indexer will extract non-binary content from fields and subfields from the Azure Cosmos DB document.
Stage 2: Field mappings
An indexer extracts text from a source field and sends it to a destination field in an index or knowledge store. When field names and data types coincide, the path is clear. However, you might want different names or types in the output, in which case you need to tell the indexer how to map the field.
To specify field mappings, enter the source and destination fields in the indexer definition.
Field mapping occurs after document cracking, but before transformations, when the indexer is reading from the source documents. When you define a field mapping, the value of the source field is sent as-is to the destination field with no modifications.
Stage 3: Skillset execution
Skillset execution is an optional step that invokes built-in or custom AI processing. Skillsets can add optical character recognition (OCR) or other forms of image analysis if the content is binary. Skillsets can also add natural language processing. For example, you can add text translation or key phrase extraction.
Whatever the transformation, skillset execution is where enrichment occurs. If an indexer is a pipeline, you can think of a skillset as a "pipeline within the pipeline".
Stage 4: Output field mappings
If you include a skillset, you'll need to specify output field mappings in the indexer definition. The output of a skillset is manifested internally as a tree structure referred to as an enriched document. Output field mappings allow you to select which parts of this tree to map into fields in your index.
Despite the similarity in names, output field mappings and field mappings build associations from different sources. Field mappings associate the content of source field to a destination field in a search index. Output field mappings associate the content of an internal enriched document (skill outputs) to destination fields in the index. Unlike field mappings, which are considered optional, an output field mapping is required for any transformed content that should be in the index.
The next image shows a sample indexer debug session representation of the indexer stages: document cracking, field mappings, skillset execution, and output field mappings.

Basic workflow
Indexers can offer features that are unique to the data source. In this respect, some aspects of indexer or data source configuration will vary by indexer type. However, all indexers share the same basic composition and requirements. Steps that are common to all indexers are covered below.
Step 1: Create a data source
Indexers require a data source object that provides a connection string and possibly credentials. Data sources are independent objects. Multiple indexers can use the same data source object to load more than one index at a time.
You can create a data source using any of these approaches:
- Using the Azure portal, on the Data sources tab of your search service pages, select Add data source to specify the data source definition.
- Using the Azure portal, the Import data wizard outputs a data source.
- Using the REST APIs, call Create Data Source.
- Using the Azure SDK for .NET, call SearchIndexerDataSourceConnection class
Step 2: Create an index
An indexer will automate some tasks related to data ingestion, but creating an index is generally not one of them. As a prerequisite, you must have a predefined index that contains corresponding target fields for any source fields in your external data source. Fields need to match by name and data type. If not, you can define field mappings to establish the association.
For more information, see Create an index.
Step 3: Create and run (or schedule) the indexer
An indexer definition consists of properties that uniquely identify the indexer, specify which data source and index to use, and provide other configuration options that influence run time behaviors, including whether the indexer runs on demand or on a schedule.
Any errors or warnings about data access or skillset validation will occur during indexer execution. Until indexer execution starts, dependent objects such as data sources, indexes, and skillsets are passive on the search service.
For more information, see Create an indexer
After the first indexer run, you can rerun it on demand or set up a schedule.
You can monitor indexer status in the portal or through Get Indexer Status API. You should also run queries on the index to verify the result is what you expected.
Indexers don't have dedicated processing resources. Based on this, indexers' status may show as idle before running (depending on other jobs in the queue) and run times may not be predictable. Other factors define indexer performance as well, such as document size, document complexity, image analysis, among others.
Next steps
Now that you've been introduced to indexers, a next step is to review indexer properties and parameters, scheduling, and indexer monitoring. Alternatively, you could return to the list of supported data sources for more information about a specific source.