הערה
הגישה לדף זה מחייבת הרשאה. באפשרותך לנסות להיכנס או לשנות מדריכי כתובות.
הגישה לדף זה מחייבת הרשאה. באפשרותך לנסות לשנות מדריכי כתובות.
This tutorial shows you how to gather statistics about your containers by using Azure Blob Storage inventory along with Azure Databricks.
In this tutorial, you learn how to:
- Generate an inventory report
- Create an Azure Databricks workspace and notebook
- Read the blob inventory file
- Get the number and total size of blobs, snapshots, and versions
- Get the number of blobs by blob type and content type
Prerequisites
An Azure subscription - create an account for free
An Azure storage account - create a storage account
Make sure that your user identity has the Storage Blob Data Contributor role assigned to it.
Generate an inventory report
Enable blob inventory reports for your storage account. See Enable Azure Storage blob inventory reports.
Use the following configuration settings:
| Setting | Value |
|---|---|
| Rule name | blobinventory |
| Container | <name of your container> |
| Object type to inventory | Blob |
| Blob types | Block blobs, Page blobs, and Append blobs |
| Subtypes | include blob versions, include snapshots, include deleted blobs |
| Blob inventory fields | All |
| Inventory frequency | Daily |
| Export format | CSV |
You might have to wait up to 24 hours after enabling inventory reports for your first report to be generated.
Configure Azure Databricks
In this section, you create an Azure Databricks workspace and notebook. Later in this tutorial, you paste code snippets into notebook cells, and then run them to gather container statistics.
Create an Azure Databricks workspace. See Create an Azure Databricks workspace.
Create a new notebook. See Create a notebook.
Choose Python as the default language of the notebook.
Read the blob inventory file
Copy and paste the following code block into the first cell, but don't run this code yet.
from pyspark.sql.types import StructType, StructField, IntegerType, StringType import pyspark.sql.functions as F storage_account_name = "<storage-account-name>" storage_account_key = "<storage-account-key>" container = "<container-name>" blob_inventory_file = "<blob-inventory-file-name>" hierarchial_namespace_enabled = False if hierarchial_namespace_enabled == False: spark.conf.set("fs.azure.account.key.{0}.blob.core.windows.net".format(storage_account_name), storage_account_key) df = spark.read.csv("wasbs://{0}@{1}.blob.core.windows.net/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true') else: spark.conf.set("fs.azure.account.key.{0}.dfs.core.windows.net".format(storage_account_name), storage_account_key) df = spark.read.csv("abfss://{0}@{1}.dfs.core.windows.net/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true')In this code block, replace the following values:
Replace the
<storage-account-name>placeholder value with the name of your storage account.Replace the
<storage-account-key>placeholder value with the account key of your storage account.Replace the
<container-name>placeholder value with the container that holds the inventory reports.Replace the
<blob-inventory-file-name>placeholder with the fully qualified name of the inventory file (For example:2023/02/02/02-16-17/blobinventory/blobinventory_1000000_0.csv).If your account has a hierarchical namespace, set the
hierarchical_namespace_enabledvariable toTrue.
Press the Run button to run the code in this cell.
Get blob count and size
In a new cell, paste the following code:
print("Number of blobs in the container:", df.count()) print("Number of bytes occupied by blobs in the container:", df.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Press the run button to run the cell.
The notebook displays the number of blobs in a container and the number of bytes occupied by blobs in the container.

Get snapshot count and size
In a new cell, paste the following code:
from pyspark.sql.functions import * print("Number of snapshots in the container:", df.where(~(col("Snapshot")).like("Null")).count()) dfT = df.where(~(col("Snapshot")).like("Null")) print("Number of bytes occupied by snapshots in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Press the run button to run the cell.
The notebook displays the number of snapshots and total number of bytes occupied by blob snapshots.

Get version count and size
In a new cell, paste the following code:
from pyspark.sql.functions import * print("Number of versions in the container:", df.where(~(col("VersionId")).like("Null")).count()) dfT = df.where(~(col("VersionId")).like("Null")) print("Number of bytes occupied by versions in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])Press SHIFT + ENTER to run the cell.
The notebook displays the number of blob versions and total number of bytes occupied by blob versions.

Get blob count by blob type
In a new cell, paste the following code:
display(df.groupBy('BlobType').count().withColumnRenamed("count", "Total number of blobs in the container by BlobType"))Press SHIFT + ENTER to run the cell.
The notebook displays the number of blob types by type.

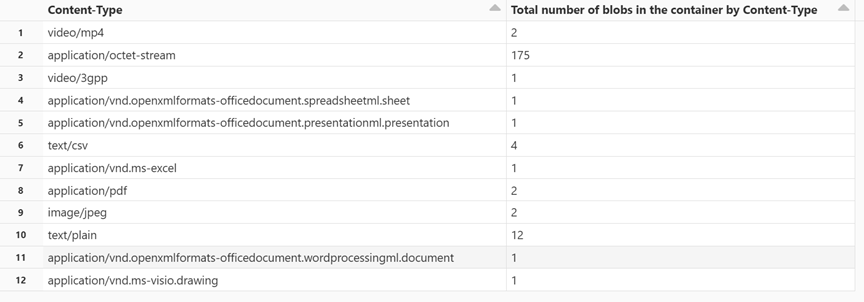
Get blob count by content type
In a new cell, paste the following code:
display(df.groupBy('Content-Type').count().withColumnRenamed("count", "Total number of blobs in the container by Content-Type"))Press SHIFT + ENTER to run the cell.
The notebook displays the number of blobs associated with each content type.
Terminate the cluster
To avoid unnecessary billing, terminate your compute resource. See terminate a compute.
Next steps
Learn how to use Azure Synapse to calculate the blob count and total size of blobs per container. See Calculate blob count and total size per container using Azure Storage inventory
Learn how to generate and visualize statistics that describes containers and blobs. See Tutorial: Analyze blob inventory reports
Learn about ways to optimize your costs based on the analysis of your blobs and containers. See these articles:
Plan and manage costs for Azure Blob Storage