הערה
הגישה לדף זה מחייבת הרשאה. באפשרותך לנסות להיכנס או לשנות מדריכי כתובות.
הגישה לדף זה מחייבת הרשאה. באפשרותך לנסות לשנות מדריכי כתובות.
Fabric runtime offers a seamless integration with Azure. It provides a sophisticated environment for both data engineering and data science projects that use Apache Spark. This article provides an overview of the essential features and components of Fabric Runtime 1.3.
Microsoft Fabric Runtime 1.3 is a GA runtime version that incorporates the following components and upgrades designed to enhance your data processing capabilities:
Apache Spark 3.5
Operating System: Mariner 2.0
Java: 11
Scala: 2.12.17
Python: 3.11
Delta Lake: 3.2
R: 4.4.1
Tip
Fabric Runtime 1.3 includes support for the Native Execution Engine, which can significantly enhance performance without more costs. To enable the native execution engine across all jobs and notebooks in your environment, navigate to your environment settings, select Spark compute, go to the Acceleration tab, and check Enable native execution engine. After you save and publish, this setting is applied across the environment, so all new jobs and notebooks automatically inherit and benefit from the enhanced performance capabilities.
Integrate Runtime 1.3
Note
For information about all available Fabric runtimes and their current status, see Apache Spark Runtimes in Fabric.
Use the following instructions to integrate runtime 1.3 into your workspace and use its new features:
Navigate to the Workspace settings tab within your Fabric workspace.
Go to Data Engineering/Science tab and select Spark Settings.
Select the Environment tab.
Under the Runtime Versions expand the dropdown.
Select 1.3 (Spark 3.5, Delta 3.2) and save your changes. This action sets 1.3 as the default runtime for your workspace.
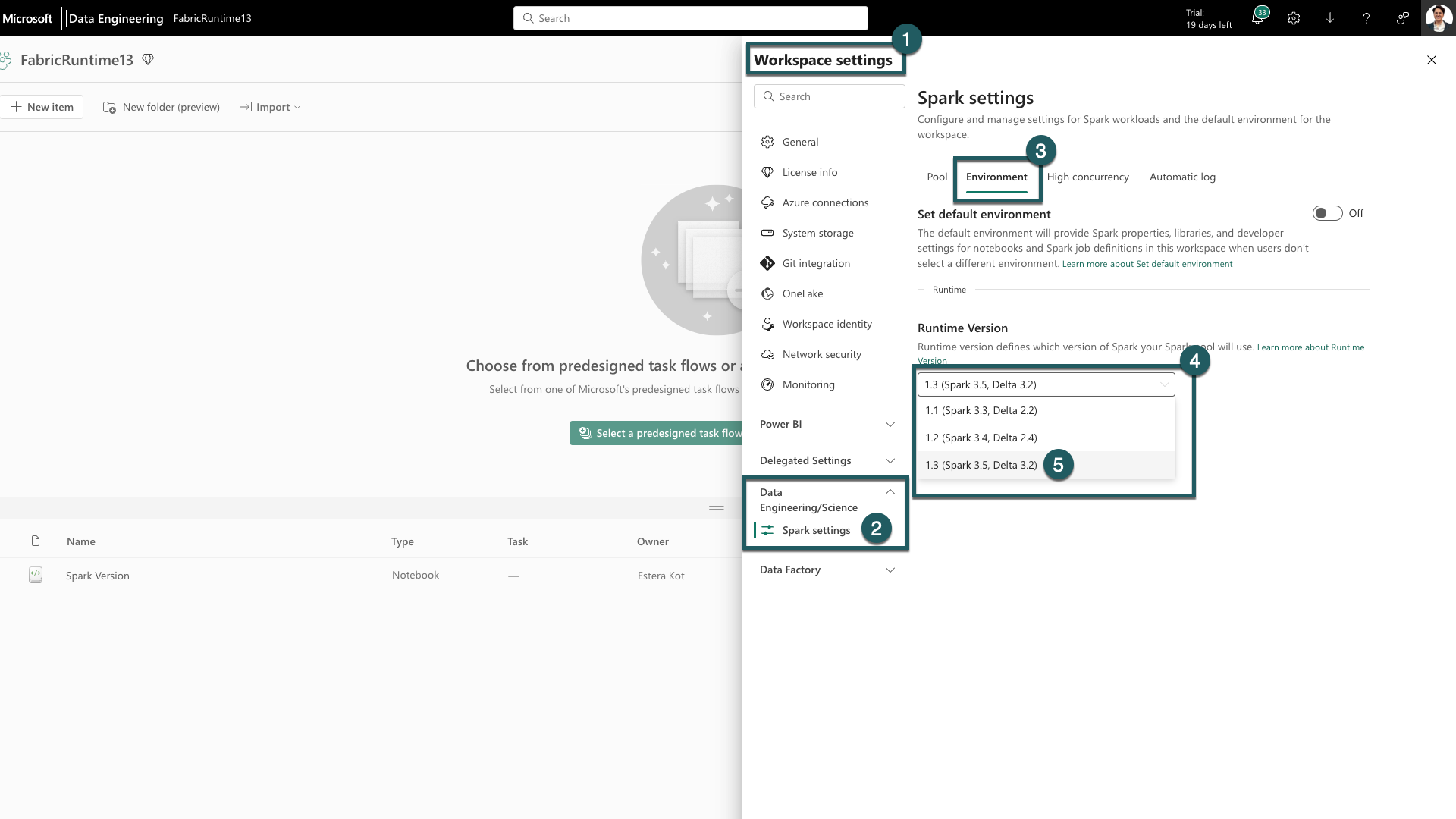

You can now start working with the newest improvements and functionalities introduced in Fabric runtime 1.3 (Spark 3.5 and Delta Lake 3.2).
Learn about Apache Spark 3.5
Apache Spark 3.5.0 is the sixth version in the 3.x series. This version is a product of extensive collaboration within the open-source community, addressing more than 1,300 issues as recorded in Jira.
In this version, there's an upgrade in compatibility for structured streaming. Additionally, this release broadens the functionality within PySpark and SQL. It adds features such as the SQL identifier clause, named arguments in SQL function calls, and the inclusion of SQL functions for HyperLogLog approximate aggregations.
Other new capabilities also include Python user-defined table functions, the simplification of distributed training via DeepSpeed, and new structured streaming capabilities like watermark propagation and the dropDuplicatesWithinWatermark operation.
You can check the full list and detailed changes here: Spark Release 3.5.0.
Learn about Delta Spark
Delta Lake 3.2 marks a collective commitment to making Delta Lake interoperable across formats, easier to work with, and more performant. Delta Spark 3.2 is built on top of Apache Spark™ 3.5. The Delta Spark maven artifact is renamed from delta-core to delta-spark.
You can check the full list and detailed changes here: https://docs.delta.io/index.html.
Components and Libraries
For up-to-date information, a detailed list of changes, and specific release notes for Fabric runtimes, check and subscribe Spark Runtimes Releases and Updates.
Note
EventHubConnector is deprecated in Fabric Runtime 1.3 (Spark 3.5) and will be removed from future Fabric Runtime versions. Customers are encouraged to use Kafka Spark Connector instead as Event Hubs is Kafka compatible already. You can find more information about using Kafka Spark Connector with Event Hubs here: Event Hubs Kafka Spark Tutorial
Related content
- Read about Apache Spark Runtimes in Fabric - Overview, Versioning, Multiple Runtimes Support and Upgrading Delta Lake Protocol
- Spark Core migration guide
- SQL, Datasets, and DataFrame migration guides
- Structured Streaming migration guide
- MLlib (Machine Learning) migration guide
- PySpark (Python on Spark) migration guide
- SparkR (R on Spark) migration guide