הערה
הגישה לדף זה מחייבת הרשאה. באפשרותך לנסות להיכנס או לשנות מדריכי כתובות.
הגישה לדף זה מחייבת הרשאה. באפשרותך לנסות לשנות מדריכי כתובות.
A machine learning model is a file trained to recognize certain types of patterns. You train a model over a set of data, and you provide it with an algorithm that uses to reason over and learn from that data set. After you train the model, you can use it to reason over data that it never saw before, and make predictions about that data.
In MLflow, a machine learning model can include multiple model versions. Here, each version can represent a model iteration. In this article, you learn how to interact with ML models to track and compare model iterations.
In this article, you learn how to:
- Create machine learning models in Microsoft Fabric
- Manage and track model versions
- Compare model performance across versions
- Apply models for scoring and inferencing
Create a machine learning model
You can create a machine learning model from the Fabric UI or programmatically with the MLflow API. In MLflow, models use a standard packaging format that works with various downstream tools, including batch inferencing on Apache Spark. The format saves a model in different "flavors" that different downstream tools can understand.
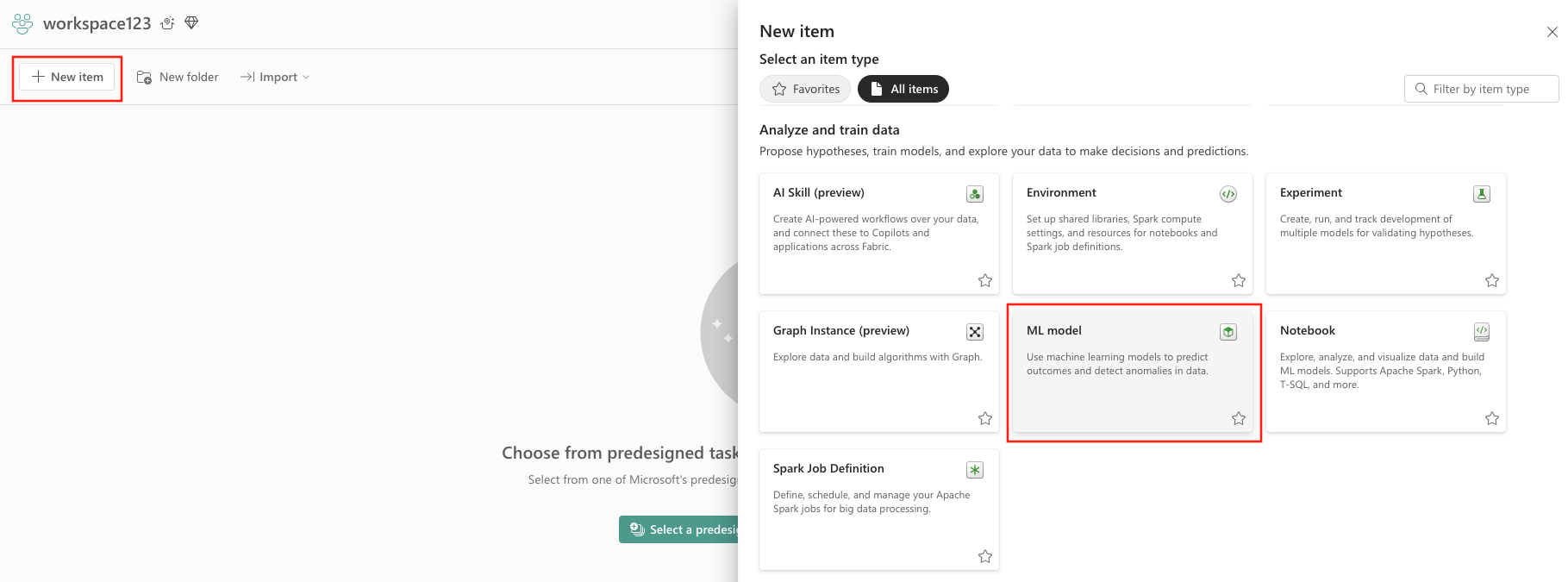
To create a machine learning model from the UI:
- Select an existing data science workspace, or create a new workspace.
- Create a new item through the workspace or by using the Create button:
- Workspace:
- Select your workspace.
- Select New item.
- Select ML Model under Analyze and train data.
- Create button:
- Select Create, which can be found in ... from the vertical menu.
- Select ML Model under Data Science.

- Select Create, which can be found in ... from the vertical menu.
- Workspace:
- After model creation, you can start adding model versions to track run metrics and parameters. Register or save experiment runs to an existing model.



You can also create a machine learning model directly from your authoring experience with the mlflow.register_model() API. If a registered machine learning model with the given name doesn't exist, the API creates it automatically.
import mlflow
model_uri = "runs:/{}/model-uri-name".format(run.info.run_id)
mv = mlflow.register_model(model_uri, "model-name")
print("Name: {}".format(mv.name))
print("Version: {}".format(mv.version))
Manage versions within a machine learning model
A machine learning model contains a collection of model versions for simplified tracking and comparison. Within a model, a data scientist can navigate across various model versions to explore the underlying parameters and metrics. Data scientists can also make comparisons across model versions to identify whether or not newer models might yield better results.
Track machine learning models
A machine learning model version represents an individual model that is registered for tracking.
![]()
Each model version includes the following information:
| Property | Description |
|---|---|
| Time Created | Date and time of model creation. |
| Run Name | The identifier for the experiment run used to create this specific model version. |
| Hyperparameters | Saved as key-value pairs. Both keys and values are strings. |
| Metrics | Run metrics saved as key-value pairs. The value is numeric. |
| Model Schema/Signature | A description of the model inputs and outputs. |
| Logged files | Logged files in any format. For example, you can record images, environment, models, and data files. |
| Tags | Custom metadata as key-value pairs attached to runs. Learn how to apply tags. |
Apply tags to machine learning models
MLflow tagging for model versions enables users to attach custom metadata to specific versions of a registered model in the MLflow Model Registry. These tags, stored as key-value pairs, help organize, track, and differentiate between model versions, making it easier to manage model lifecycles. Tags can be used to denote the model's purpose, deployment environment, or any other relevant information, facilitating more efficient model management and decision-making within teams.
This code demonstrates how to train a RandomForestRegressor model using Scikit-learn, log the model and parameters with MLflow, and then register the model in the MLflow Model Registry with custom tags. These tags provide useful metadata, such as project name, department, team, and project quarter, making it easier to manage and track the model version.
import mlflow.sklearn
from mlflow.models import infer_signature
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
# Generate synthetic regression data
X, y = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
# Model parameters
params = {"n_estimators": 3, "random_state": 42}
# Model tags for MLflow
model_tags = {
"project_name": "grocery-forecasting",
"store_dept": "produce",
"team": "stores-ml",
"project_quarter": "Q3-2023"
}
# Log MLflow entities
with mlflow.start_run() as run:
# Train the model
model = RandomForestRegressor(**params).fit(X, y)
# Infer the model signature
signature = infer_signature(X, model.predict(X))
# Log parameters and the model
mlflow.log_params(params)
mlflow.sklearn.log_model(model, artifact_path="sklearn-model", signature=signature)
# Register the model with tags
model_uri = f"runs:/{run.info.run_id}/sklearn-model"
model_version = mlflow.register_model(model_uri, "RandomForestRegressionModel", tags=model_tags)
# Output model registration details
print(f"Model Name: {model_version.name}")
print(f"Model Version: {model_version.version}")
After applying the tags, you can view them directly on the model version details page. Additionally, tags can be added, updated, or removed from this page at any time.

Compare and filter machine learning models
To compare and evaluate the quality of machine learning model versions, you can compare the parameters, metrics, and metadata between selected versions.
Visually compare machine learning models
You can visually compare runs within an existing model. Visual comparison allows easy navigation between, and sorts across, multiple versions.

To compare runs, you can:
- Select an existing machine learning model that contains multiple versions.
- Select the View tab, and then navigate to the Model list view. You can also select the option to View model list directly from the details view.
- You can customize the columns within the table. Expand the Customize columns pane. From there, you can select the properties, metrics, tags, and hyperparameters that you want to see.
- Lastly, you can select multiple versions, to compare their results, in the metrics comparison pane. From this pane, you can customize the charts with changes to the chart title, visualization type, X-axis, Y-axis, and more.
Compare machine learning models using the MLflow API
Data scientists can also use MLflow to search among multiple models saved within the workspace. Visit the MLflow documentation to explore other MLflow APIs for model interaction.
from pprint import pprint
from mlflow import MlflowClient
client = MlflowClient()
for rm in client.search_registered_models():
pprint(dict(rm), indent=4)
Apply machine learning models
Once you train a model on a data set, you can apply that model to data it never saw to generate predictions. We call this model use technique scoring or inferencing.
Fabric supports multiple approaches for applying your trained models:
- Batch scoring � Apply your model at scale across large datasets using Apache Spark. This is ideal for generating predictions on historical or scheduled data.
- Real-time scoring � Deploy your model to an endpoint for on-demand predictions, useful for applications that need immediate results.
To get started with applying your models, choose the approach that fits your scenario: