Understanding Parallel Computing Jobs
The most common types of parallel computing jobs that you can run on a HPC Pack cluster are: MPI jobs, parametric sweep jobs, task flow jobs, Service Oriented Architecture (SOA) jobs, and Microsoft Excel calculation offloading jobs. HPC Pack provides job and task properties, tools, and APIs that help you define and submit various types of parallel computing jobs.
In this topic:
MPI job
MS-MPI, a Microsoft implementation of Message Passing Interface (MPI) developed for Windows, allows MPI applications to run as tasks on an HPC cluster.
An MPI task is intrinsically parallel. A parallel task can take a number of forms, depending on the application and the software that supports it. For an MPI application, a parallel task usually consists of a single executable that is running concurrently on multiple cores, with communication occurring between the processes.
The following diagram illustrates a parallel task:

For a task that runs an MPI application, the task command must be preceded by mpiexec: therefore, commands for parallel tasks must be in the following format: mpiexec [mpi_options] <myapp.exe> [arguments], where myapp.exe is the name of the application to run. The mpiexec command takes a number of arguments which allow you to control MPI process placement, networking affinity, and other run time parameters. For more details on these parameters, see the Microsoft HPC Pack Command Line Reference.
Note
For parallel tasks, Windows HPC Server 2008 includes an MPI package based on Argonne National Laboratory's MPICH2 standard. Microsoft’s implementation of MPI, called MS-MPI, includes the launcher mpiexec, an MPI service for each node, and a Software Development Kit (SDK) for user application development. Windows HPC Server 2008 also supports applications that provide their own parallel processing mechanisms.
For more information about the SDK, see Microsoft HPC Pack.
For information about how to create a single-task or MPI job, see Define a Basic or MPI Task - Job Manager.
Parametric sweep job
A parametric sweep job consists of multiple instances of the same application, usually a serial application, running concurrently, and with input supplied by an input file and output directed to an output file. The input and output are usually a set of indexed files (for example, input1, input2, input3…, output1, output2, output3…) set up to reside in a single common folder or in separate common folders. There is no communication or interdependency among the tasks. The tasks may or may not run in parallel, depending on the resources that are available on a cluster when the job is running.
The following diagram illustrates a parametric sweep job:

For information about how to create a parametric sweep job, see Define a Parametric Sweep Task - Job Manager.
Task flow job
In a task flow job, a set of unlike tasks are run in a prescribed order, usually because one task depends on the result of another task. A job can contain many tasks, some of which are parametric, some serial, and some parallel. For example, you can create a task flow job consisting of MPI and parametric tasks. You can establish the order in which tasks are run by defining dependencies between the tasks.
The following diagram illustrates a task flow job:
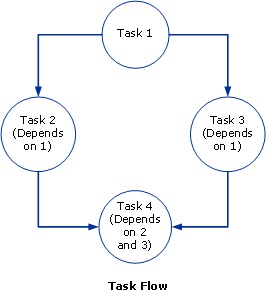
Task 1 runs first. Note that only Tasks 2 and 3 may run in parallel, because neither is dependent on the other. Task 4 runs after Tasks 2 and 3 have both completed.
For information about how to create a task flow job, see Define Task Dependencies - Job Manager.
SOA job
Service Oriented Architecture (SOA) is an approach to building distributed, loosely coupled systems. In a SOA system, distinct computational functions are packaged as software modules called services. Services can be distributed across a network and accessed by other applications. For example, if applications perform repeated parallel calculations, the core calculations can be packaged as services and deployed to a cluster. This allows developers to solve embarrassingly parallel problems without rewriting the low-level code and to rapidly scale out applications. Applications can run faster by distributing core calculations across multiple service hosts (compute nodes). End-users run the application on their computers and cluster nodes perform calculations.
A client application provides an interface for the end-user to access the functionality of one or more services. Developers can create cluster-SOA client applications to provide access to services that are deployed to a Windows HPC cluster. On the back-end, the client application submits a job that contains a Service task to the cluster, initiates a session with the broker node, and sends service requests and receives responses (calculation results). The job scheduler on the head node allocates resources to the service job according to the job scheduling policies. An instance of the Service task runs on each allocated resource and loads the SOA service. The job scheduler tries to adjust resource allocation based on the number of service requests.
Note
If the client created a durable session, the broker stores all messages using MSMQ. Responses that are stored by the broker can be retrieved by the client at any time, even after intentional or unintentional disconnect.
The following diagram illustrates how a SOA job runs on the cluster:

For more information about creating SOA clients for an HPC cluster, see SOA Applications and Microsoft HPC Pack.
Note
HPC Services for Excel use the SOA infrastructure to help offload Microsoft Excel calculations to a cluster.
Microsoft Excel calculation offloading
HPC Services for Excel, included in some versions of HPC Pack, support a number of models for offloading Excel calculations to a HPC Pack cluster. Workbooks that are suitable for cluster acceleration include independent calculations that can run in parallel. Many complex and long-running workbooks run iteratively—that is, they perform a single calculation many times over different sets of input data. These workbooks might contain complex Microsoft Visual Basic for Applications (VBA) functions or calculation intensive XLL add-ins. HPC Services for Excel support offloading workbooks to the cluster, or offloading UDFs to the cluster.
Microsoft Excel 2010 extends the UDF model to the cluster by enabling Excel 2010 UDFs to run in a Windows HPC cluster. When a supported cluster is available, users can instruct Excel 2010 to use that cluster by selecting a cluster connector and specifying the cluster name in the Advanced options of the Excel Options dialog box. In the cluster, UDFs work much like traditional UDFs, except that the calculation is performed by one or more servers. The key benefit is parallelization. If a workbook contains calls to long-running UDFs, multiple servers can be used to evaluate functions simultaneously. In order to run on the cluster, the UDFs must be contained in a cluster-safe XLL file.
For more information, see HPC Services for Excel.
Additional references
For information about the job and task properties that you can use to define your parallel computing jobs, see:
For information about creating, submitting, and monitoring jobs by using HPC Job Manager, see:
For information about creating, submitting, and monitoring jobs by using a command prompt window or HPC PowerShell, and for developer resources, including information about using the SDK, the SOA programming model, and Excel calculation offloading, see additional articles in this documentation set.