Connect to and manage Teradata in Microsoft Purview
This article outlines how to register Teradata, and how to authenticate and interact with Teradata in Microsoft Purview. For more information about Microsoft Purview, read the introductory article.
Supported capabilities
| Metadata Extraction | Full Scan | Incremental Scan | Scoped Scan | Classification | Labeling | Access Policy | Lineage | Data Sharing | Live view |
|---|---|---|---|---|---|---|---|---|---|
| Yes | Yes | No | Yes | Yes | No | No | Yes* | No | No |
* Besides the lineage on assets within the data source, lineage is also supported if dataset is used as a source/sink in Data Factory or Synapse pipeline.
The supported Teradata database versions are 12.x to 17.x.
When scanning Teradata source, Microsoft Purview supports:
Extracting technical metadata including:
- Server
- Databases
- Tables including the columns, foreign keys, indexes, and constraints
- Views including the columns
- Stored procedures including the parameter dataset and result set
- Functions including the parameter dataset
Fetching static lineage on assets relationships among tables and views.
When setting up scan, you can choose to scan an entire Teradata server, or scope the scan to a subset of databases matching the given name(s) or name pattern(s).
Known limitations
When object is deleted from the data source, currently the subsequent scan won't automatically remove the corresponding asset in Microsoft Purview.
Required permissions for scan
Microsoft Purview supports basic authentication (username and password) for scanning Teradata. The user should have SELECT permission granted for every individual system table listed below:
grant select on dbc.tvm to [user];
grant select on dbc.dbase to [user];
grant select on dbc.tvfields to [user];
grant select on dbc.udtinfo to [user];
grant select on dbc.idcol to [user];
grant select on dbc.udfinfo to [user];
To retrieve data types of view columns, Microsoft Purview issues a prepare statement for select * from <view> for each of the view queries and parse the metadata that contains the data type details for better performance. It requires the SELECT data permission on views. If the permission is missing, view column data types will be skipped.
For classification, user also needs to have read permission on the tables/views to retrieve sample data.
Prerequisites
An Azure account with an active subscription. Create an account for free.
An active Microsoft Purview account.
You need Data Source Administrator and Data Reader permissions to register a source and manage it in the Microsoft Purview governance portal. For more information about permissions, see Access control in Microsoft Purview.
Set up the latest self-hosted integration runtime. For more information, see the create and configure a self-hosted integration runtime guide.
Ensure JDK 11 is installed on the machine where the self-hosted integration runtime is installed. Restart the machine after you newly install the JDK for it to take effect.
Ensure Visual C++ Redistributable (version Visual Studio 2012 Update 4 or newer) is installed on the self-hosted integration runtime machine. If you don't have this update installed, you can download it here.
Download the Teradata JDBC driver on the machine where your self-hosted integration runtime is running. Note down the folder path which you will use to set up the scan.
Note
The driver should be accessible by the self-hosted integration runtime. By default, self-hosted integration runtime uses local service account "NT SERVICE\DIAHostService". Make sure it has "Read and execute" and "List folder contents" permission to the driver folder.
Register
This section describes how to register Teradata in Microsoft Purview using the Microsoft Purview governance portal.
Steps to register
Open the Microsoft Purview governance portal by:
- Browsing directly to https://web.purview.azure.com and selecting your Microsoft Purview account.
- Opening the Azure portal, searching for and selecting the Microsoft Purview account. Selecting the the Microsoft Purview governance portal button.
Select Data Map on the left navigation.
Select Register
On Register sources, select Teradata. Select Continue

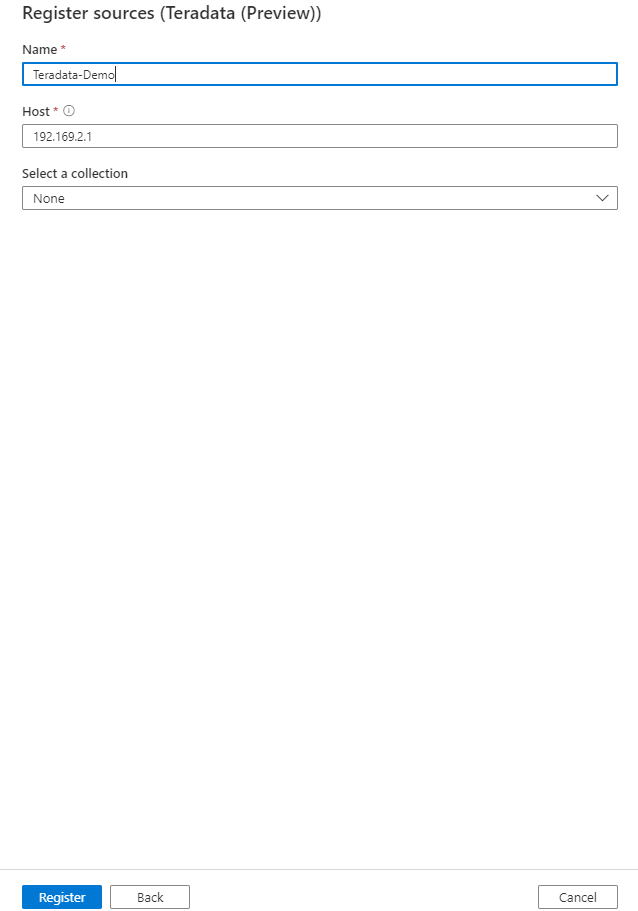
On the Register sources (Teradata) screen, do the following:
Enter a Name that the data source will be listed with in the Catalog.
Enter the Host name to connect to a Teradata source. It can also be an IP address of the server.
Select a collection from the list.
Finish to register the data source.
Scan
Follow the steps below to scan Teradata to automatically identify assets. For more information about scanning in general, see our introduction to scans and ingestion.
Create and run scan
In the Management Center, select Integration runtimes. Make sure a self-hosted integration runtime is set up. If it isn't set up, use the steps mentioned here to set up a self-hosted integration runtime
Select the Data Map tab on the left pane in the Microsoft Purview governance portal.
Select the registered Teradata source.
Select New scan
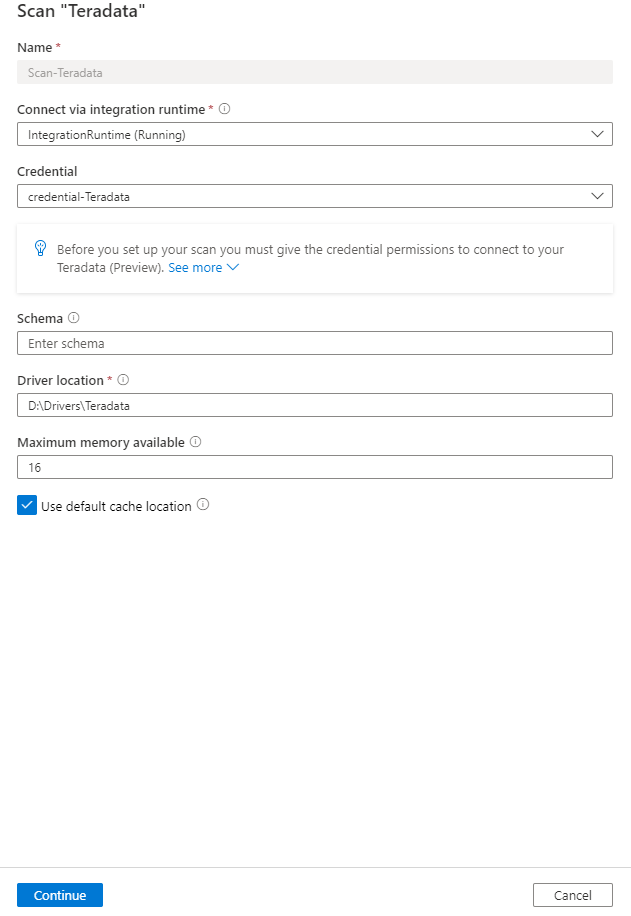
Provide the below details:
Name: The name of the scan
Connect via integration runtime: Select the configured self-hosted integration runtime.
Credential: Select the credential to connect to your data source. Make sure to:
- Select Basic Authentication while creating a credential.
- Provide a user name to connect to database server in the User name input field
- Store the database server password in the secret key.
To understand more on credentials, refer to the link here
Schema: List subset of databases to import expressed as a semicolon separated list. For Example:
schema1;schema2. All user databases are imported if that list is empty. All system databases (for example, SysAdmin) and objects are ignored by default.Acceptable database name patterns can be static names or contain wildcard %. For example:
A%;%B;%C%;D- Start with A or
- End with B or
- Contain C or
- Equal D
Usage of NOT and special characters aren't acceptable
Driver location: Specify the path to the JDBC driver location in your machine where self-host integration runtime is running. For example:
D:\Drivers\Teradata.- For self-hosted integration runtime on a local machine:
D:\Drivers\Teradata. It's the path to valid JAR folder location. The value must be a valid absolute file path and doesn't contain space. Make sure the driver is accessible by the self-hosted integration runtime;; learn more from prerequisites section.
- For self-hosted integration runtime on a local machine:
Stored procedure details: Controls the number of details imported from stored procedures:
- Signature: The name and parameters of stored procedures.
- Code, signature: The name, parameters and code of stored procedures.
- Lineage, code, signature: The name, parameters and code of stored procedures, and the data lineage derived from the code.
- None: Stored procedure details aren't included.
Maximum memory available: Maximum memory (in GB) available on customer's VM to be used by scanning processes. This is dependent on the size of Teradata source to be scanned.
Note
As a rule of thumb, please provide 2GB memory for every 1000 tables
Select Continue.
Select a scan rule set for classification. You can choose between the system default, existing custom rule sets, or create a new rule set inline.
Choose your scan trigger. You can set up a schedule or ran the scan once.
Review your scan and select Save and Run.
View your scans and scan runs
To view existing scans:
- Go to the Microsoft Purview portal. On the left pane, select Data map.
- Select the data source. You can view a list of existing scans on that data source under Recent scans, or you can view all scans on the Scans tab.
- Select the scan that has results you want to view. The pane shows you all the previous scan runs, along with the status and metrics for each scan run.
- Select the run ID to check the scan run details.
Manage your scans
To edit, cancel, or delete a scan:
Go to the Microsoft Purview portal. On the left pane, select Data Map.
Select the data source. You can view a list of existing scans on that data source under Recent scans, or you can view all scans on the Scans tab.
Select the scan that you want to manage. You can then:
- Edit the scan by selecting Edit scan.
- Cancel an in-progress scan by selecting Cancel scan run.
- Delete your scan by selecting Delete scan.
Note
- Deleting your scan does not delete catalog assets created from previous scans.
Lineage
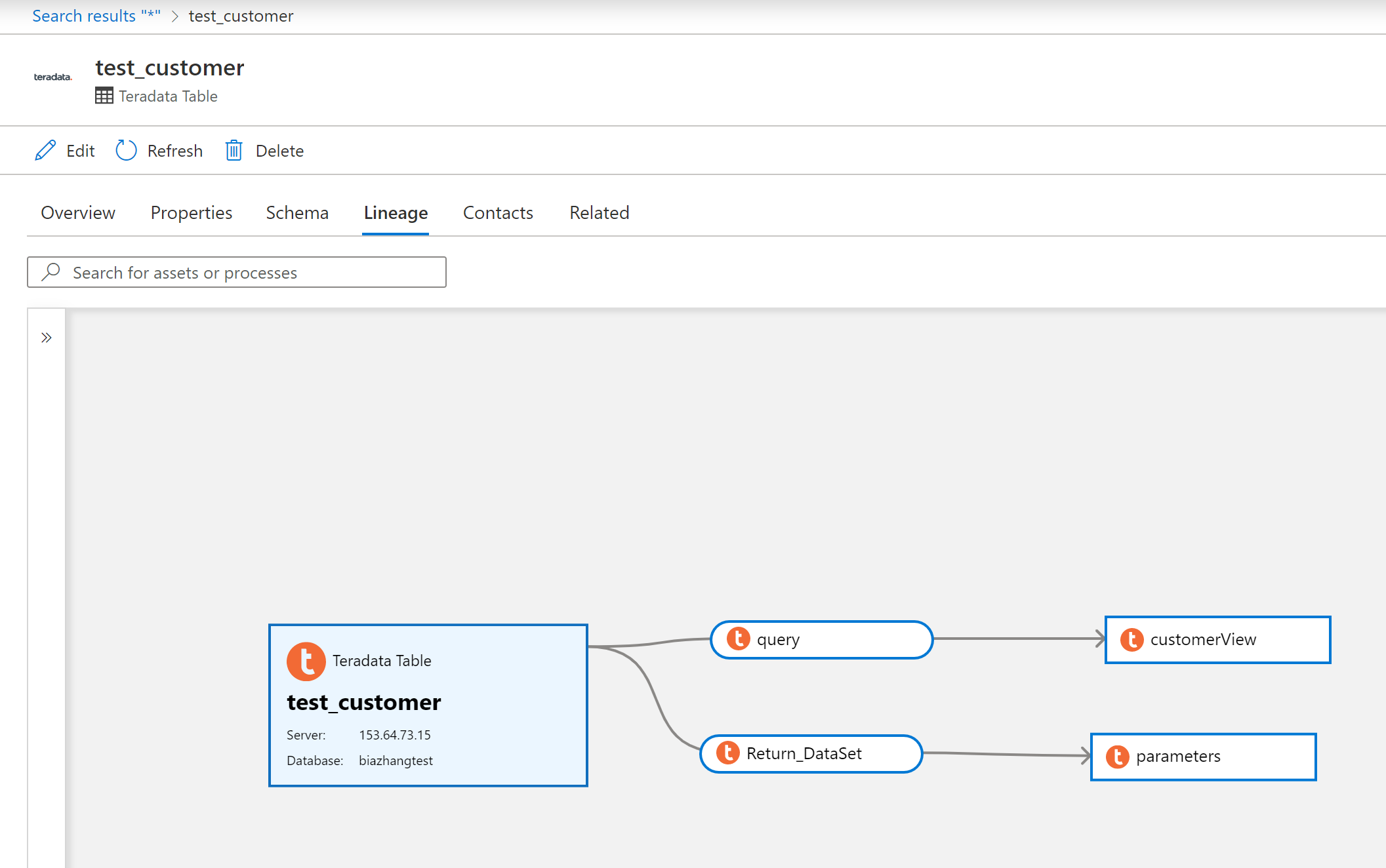
After scanning your Teradata source, you can browse data catalog or search data catalog to view the asset details.
Go to the asset -> lineage tab, you can see the asset relationship when applicable. Refer to the supported capabilities section on the supported Teradata lineage scenarios. For more information about lineage in general, see data lineage and lineage user guide.
Next steps
Now that you've registered your source, follow the below guides to learn more about Microsoft Purview and your data.