Introducing app deployment in SQL Server Big Data Clusters
Applies to: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
The Microsoft SQL Server 2019 Big Data Clusters add-on will be retired. Support for SQL Server 2019 Big Data Clusters will end on February 28, 2025. All existing users of SQL Server 2019 with Software Assurance will be fully supported on the platform and the software will continue to be maintained through SQL Server cumulative updates until that time. For more information, see the announcement blog post and Big data options on the Microsoft SQL Server platform.
Application deployment enables the deployment of applications on a SQL Server Big Data Clusters by providing interfaces to create, manage, and run applications. Applications deployed on a Big Data Cluster benefit from the computational power of the cluster and can access the data that is available on the cluster. This increases scalability and performance of the applications, while managing the applications where the data lives. The supported application runtimes on SQL Server Big Data Clusters are: R, Python, dtexec, and MLeap.
The following sections describe the architecture and functionality of application deployment.
Application deployment architecture
Application deployment consists of a controller and app runtime handlers. When creating an application, a specification file (spec.yaml) is provided. This spec.yaml file contains everything the controller needs to know to successfully deploy the application. The following is a sample of the contents for spec.yaml:
#spec.yaml
name: add-app #name of your python script
version: v1 #version of the app
runtime: Python #the language this app uses (R or Python)
src: ./add.py #full path to the location of the app
entrypoint: add #the function that will be called upon execution
replicas: 1 #number of replicas needed
poolsize: 1 #the pool size that you need your app to scale
inputs: #input parameters that the app expects and the type
x: int
y: int
output: #output parameter the app expects and the type
result: int
The controller inspects the runtime specified in the spec.yaml file and calls the corresponding runtime handler. The runtime handler creates the application. First, a Kubernetes ReplicaSet is created containing one or more pods, each of which contains the application to be deployed. The number of pods is defined by the replicas parameter set in the spec.yaml file for the application. Each pod can have one of more pools. The number of pools is defined by the poolsize parameter set in the spec.yaml file.
These settings determine the amount of requests the deployment can handle in parallel. The maximum number of requests at one given time is equals to replicas times poolsize. If you have 5 replicas and 2 pools per replica the deployment can handle 10 requests in parallel. See the image below for a graphical representation of replicas and poolsize:
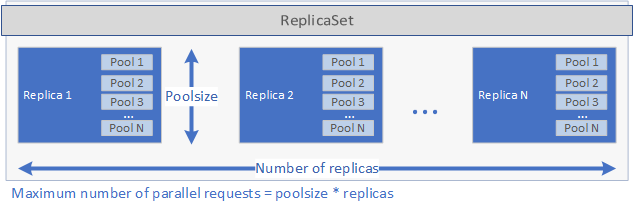
After the ReplicaSet has been created and the pods have started, a cron job is created if a schedule was set in the spec.yaml file. Finally, a Kubernetes Service is created that can be used to manage and run the application (see below).
When an application is executed, the Kubernetes service for the application proxies the requests to a replica and returns the results.
Security considerations for applications deployments on OpenShift
SQL Server 2019 CU5 enables support for BDC deployment on Red Hat OpenShift and an updated security model for BDC so privileged containers no longer required. In addition to non-privileged, containers are running as non-root user by default for all new deployments using SQL Server 2019 CU5.
At the time of the CU5 release, the setup step of the applications deployed with app deploy interfaces will still run as root user. This is required since during setup extra packages that application will use are installed. Other user code deployed as part of the application will run as low privilege user.
In addition, CAP_AUDIT_WRITE capability is an optional capability necessary to allow scheduling SQL Server Integration Services (SSIS) applications using cron jobs. When the application's yaml specification file specifies a schedule, the application will be triggered via a cron job, which requires the extra capability. Alternatively, the application can be triggered on demand with azdata app run through a web service call, which does not require the CAP_AUDIT_WRITE capability. Note that CAP_AUDIT_WRITE capability no longer needed for cronjob starting from SQL Server 2019 CU8 release.
Note
The custom SCC in the OpenShift deployment article does not include this capability since it is not required by a default deployment of BDC. To enable this capability, you must first update the custom SCC yaml file to include CAP_AUDIT_WRITE.
...
allowedCapabilities:
- SETUID
- SETGID
- CHOWN
- SYS_PTRACE
- AUDIT_WRITE
...
How to work with app deploy inside Big Data Cluster
The two main interfaces for application deployment are:
It is also possible for an application to be executed using a RESTful web service. For more information, see Consume applications on Big Data Clusters.
App deploy scenarios
Application deployment enables the deployment of applications on a SQL Server BDC by providing interfaces to create, manage, and run applications.
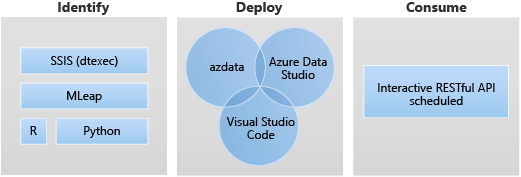
The followings are the target scenarios for app deploy:
- Deploy Python or R web services inside the big data cluster to address variety of use cases such as machine learning inferencing, API serving, etc.
- Create a machine learning inferencing endpoint using the MLeap engine.
- Schedule and run packages from DTSX files using dtexec utility for data transformation and movement.
Use app deploy Python runtime
In app deploy, BDC python runtime allows Python application inside the big data cluster to address variety of use cases such as machine learning inferencing, API serving and more.
The app deploy Python runtime uses Python 3.8 on SQL Server Big Data Clusters CU10+.
In app deploy, spec.yaml is where you provide the information that controller needs to know to deploy your application. The following are the fields that can be specified:
name: the application nameversion: the application version, for instance, such asv1runtime: the app deploy runtime, you need to specify it as:Pythonsrc: the path to the Python applicationentry point: the entry point function in the src script to execute for this Python application.
Aside from above you need to specify the input and output of your Python application. That generates a spec.yaml file similar to the following:
#spec.yaml
name: add-app
version: v1
runtime: Python
src: ./add.py
entrypoint: add
replicas: 1
poolsize: 1
inputs:
x: int
y: int
output:
result: int
You can create the basic folder and file structure needed to deploy a Python app running on Big Data Clusters:
azdata app init --template python --name hello-py --version v1
For next steps, see How to deploy an app on SQL Server Big Data Clusters.
Limitations of app deploy Python runtime
App deploy Python runtime doesn't support scheduling scenario. Once Python app is deployed, and running in BDC, a RESTful endpoint is configured to listen for incoming requests.
Use app deploy R runtime
In app deploy, BDC Python runtime allows R application inside the big data cluster to address variety of use cases such as machine learning inferencing, API serving and more.
The app deploy R runtime uses Microsoft R Open (MRO) version 3.5.2 on SQL Server Big Data Clusters CU10+.
How to use it?
In app deploy, spec.yaml is where you provide the information that controller needs to know to deploy your application. The following are the fields that can be specified:
name: the application nameversion: the application version, for instance, such asv1runtime: the app deploy runtime, you need to specify it as:Rsrc: the path to the R applicationentry point: the entry point to execute this R application
Aside from above you need to specify the input and output of your R application. That generates a spec.yaml file similar to the following:
#spec.yaml
name: roll-dice
version: v1
runtime: R
src: ./roll-dice.R
entrypoint: rollEm
replicas: 1
poolsize: 1
inputs:
x: integer
output:
result: data.fram
You can create the basic folder and file structure needed to deploy a new R application using the following command:
azdata app init --template r --name hello-r --version v1
For next steps, see How to deploy an app on SQL Server Big Data Clusters.
Limitations of R runtime
These limitations align with the Microsoft R Application Network, which was retired on July 1, 2023. For more information and workarounds, see Microsoft R Application Network retirement.
Using app deploy dtexec runtime
In app deploy, the Big Data Cluster runtime integrated dtexec utility is from SSIS on Linux (mssql-server-is). App deploy uses the dtexec utility to load packages from *.dtsx files. It supports running SSIS packages on cron-style schedule or on-demand through web service requests.
This feature uses /opt/ssis/bin/dtexec /FILE from SQL Server 2019 Integration Service on Linux. It supports dtsx format for SQL Server 2019 Integration Service on Linux (mssql-server-is 15.0.2). To learn more about dtexec utility, see dtexec Utility.
In app deploy, spec.yaml is where you provide the information that controller needs to know to deploy your application. The following are the fields that can be specified:
name: the applicationnameversion: the application version, for instance, such asv1runtime: the app deploy runtime, in order to run dtexec utility, you need to specify it as:SSISentrypoint: specify an entry point, this is usually your .dtsx file in our case.options: specify additional options for/opt/ssis/bin/dtexec /FILE, for example to connect to a database with connection string, it would follow the following pattern:/REP V /CONN "sqldatabasename"\;"\"Data Source=xx;User ID=xx;Password=<password>\""For details on syntax, see dtexec Utility.
schedule: specify how often the job needs to be executed, for instances, when using cron expression to specify this value specifies as "*/1 * * * *" meaning the job is being executed on minute basis.
You can create the basic folder and file structure needed to deploy a new SSIS application using the following command:
azdata app init --name hello-is –version v1 --template ssis
That generates a spec.yaml file to the following:
#spec.yaml
entrypoint: ./hello.dtsx
name: hello-is
options: /REP V
poolsize: 2
replicas: 2
runtime: SSIS
schedule: '*/2 * * * *'
version: v1
The example also creates a sample hello.dtsx package.
All of your app files are in the same directory as your spec.yaml. The spec.yaml must be at the root level of your app source code directory including the dtsx file.
For next steps, see How to deploy an app on SQL Server Big Data Clusters.
Limitations of the dtexec utility runtime
All limitations and known issues for SQL Server Integration Services (SSIS) on Linux are applicable in SQL Server Big Data Clusters. You can find out more from Limitations and known issues for SSIS on Linux.
Using app deploy MLeap runtime
The app deploy MLeap runtime supports MLeap Serving v0.13.0.
In app deploy, spec.yaml is where you provide the information that controller needs to know to deploy your application. The following are the fields that can be specified:
name: the application nameversion: the application version, for instance, such asv1runtime: the app deploy runtime, you need to specify it as:Mleap
Aside from above you need to specify the bundleFileName of your MLeap application. That generates a spec.yaml file similar to the following:
#spec.yaml
name: mleap-census
version: v1
runtime: Mleap
bundleFileName: census-bundle.zip
replicas: 1
You can create the basic folder and file structure needed to deploy a new MLeap application using the following command:
azdata app init --template mleap --name hello-mleap --version v1
For next steps, see How to deploy an app on SQL Server Big Data Clusters.
Limitations of MLeap runtime
The limitations align with the vision from the MLeap open-source project Combust on GitHub.
Next steps
To learn more about how to create and run applications on SQL Server Big Data Clusters, see the following:
- Deploy applications using azdata
- Deploy applications using the app deploy extension
- Consume applications on Big Data Clusters
To learn more about the SQL Server Big Data Clusters, see the following overview: